溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
大數據中如何爬取一個網站的信息,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
假如我們要爬這個網站:http://stuu.scnu.edu.cn/articles 的摘要和圖片。
首先引入庫:
from bs4 import BeautifulSoup
import requests
這兩個庫是爬蟲工具,文章底部有安裝方法。
然后定義url為我們需要爬蟲的網址,并且用requests.get()得到這個網址的內容存放在wb_data中。
url = "http://stuu.scnu.edu.cn/articles"
wb_data = requests.get(url)
對這些內容進行解析,這里要用到lxml,也是一種庫。
soup = BeautifulSoup(wb_data.text,'lxml')
我們先隨便找一欄:
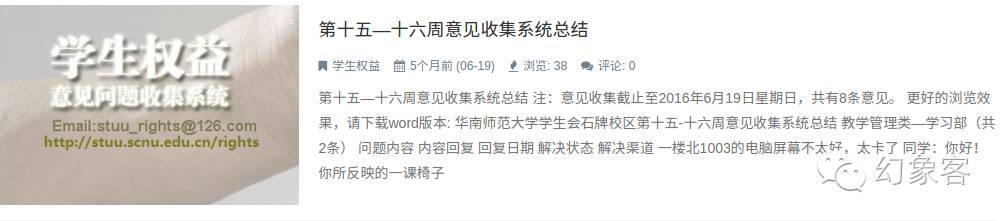
然后對網頁使用開發者工具提取我們想要的信息。還記得左上角這個鼠標+框框的圖案(圖中變藍了)嗎?點擊它,然后點擊標題。

右邊會自動跳轉到它的代碼:

選擇它的上一級,也就是上一個小三角形。如圖:

右鍵-Copy-Copy selector,會得到下面這個:
#main-wrap-left > div.bloglist-container.clr > article:nth-child(5) > div.home-blog-entry-text.clr
把'#'號到'>'號的部分去掉,再把:nth-child(5)去掉,這個指的是第五個標簽,如果不去掉的話你只會得到第五個標簽的內容。
得到:div.bloglist-container.clr > article > div.home-blog-entry-text.clr
如果你對圖片、摘要,分別做同樣的事情,你會得到
圖片:div.bloglist-container.clr > article> a > div > img
摘要:div.bloglist-container.clr > article > div.home-blog-entry-text.clr > p
然后定義一個 :變量=soup.select("你剛剛得到的內容")
titles = soup.select("div.bloglist-container.clr > article > div.home-blog-entry-text.clr")
texts = soup.select("div.bloglist-container.clr > article > div.home-blog-entry-text.clr > p")
imgs = soup.select("div.bloglist-container.clr > article > a > div > img")這里是把這些內容提取出來
再把他們放到字典里(title,text,img都是新變量):
for title,text,img in zip(titles,texts,imgs):
data = {
"標題":title.get_text(),
"摘要":text.get_text(),
"圖片":img.get('src')
}
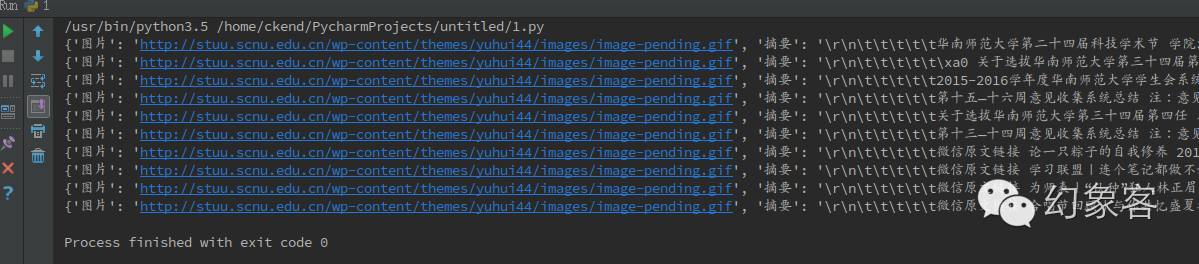
然后print(data),你會得到下面的信息,這樣我們就提取完畢了。(點擊查看大圖)
完整代碼:
from bs4 import BeautifulSoup
import requests
url = "http://stuu.scnu.edu.cn/articles"
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
titles = soup.select("div.bloglist-container.clr > article > div.home-blog-entry-text.clr")
texts = soup.select("div.bloglist-container.clr > article > div.home-blog-entry-text.clr > p")
imgs = soup.select("div.bloglist-container.clr > article > a > div > img")
for title,text,img in zip(titles,texts,imgs):
data = {
"標題":title.get_text(),
"摘要":text.get_text(),
"圖片":img.get('src')
}
print(data)
如果你不止想得到僅僅這十個信息,那么你可以構造函數。
我們注意到第二頁的域名是:http://stuu.scnu.edu.cn/articles?paged=2
這是個重點,我們可以把2換成別的數字:
url = "http://stuu.scnu.edu.cn/articles?paged="
然后再把剛剛的內容變成一個函數:
def get_page(url):
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
titles = soup.select("div.bloglist-container.clr > article > div.home-blog-entry-text.clr")
texts = soup.select("div.bloglist-container.clr > article > div.home-blog-entry-text.clr > p")
imgs = soup.select("div.bloglist-container.clr > article > a > div > img")
for title,text,img in zip(titles,texts,imgs):
data = {
"標題":title.get_text(),
"摘要":text.get_text(),
"圖片":img.get('src')
}
print(data)
再添加一個能夠調整所需要的網頁數目,并調用get_page的函數:
def getmorepage(start,end):
for i in range (start,end):
get_page(url+str(i))
最后你想要多少頁的數據?
getmorepage(1,10)
最終結果(點擊查看大圖):

你想要多少有多少,快速高效。
當然我這只是拋磚引玉(還有很多用法哦)
庫的安裝方法:
首先我們需要三個庫,一個是Beautifulsoup,一個是requests,還有一個是lxml。
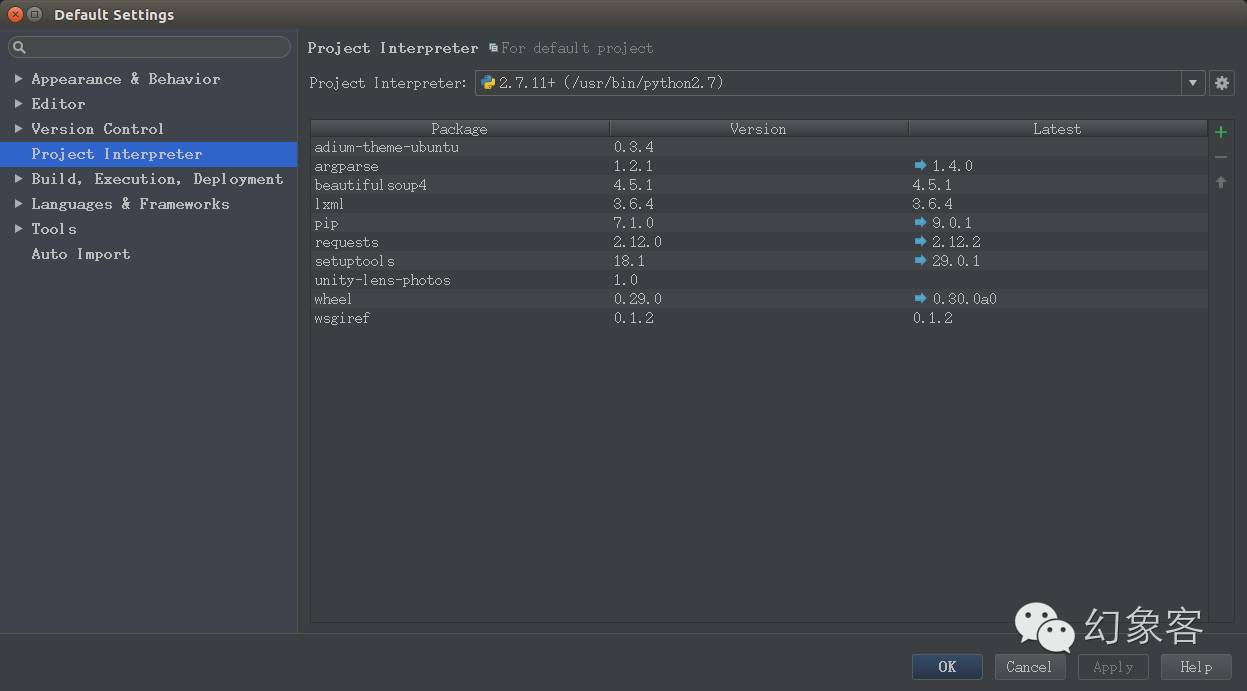
如果你用的是PyCharm,可以從File->Default Settings->project interpreter內添加這兩個庫,如圖:
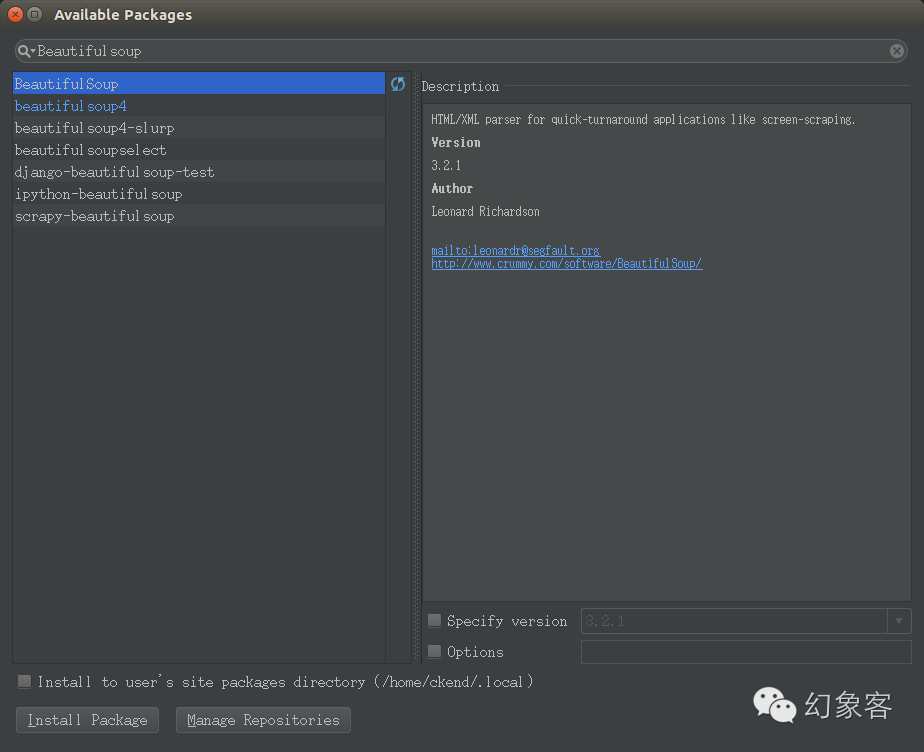
點擊右邊那個+號,輸入你想要安裝的庫即可。
Linux下安裝:
1.有PyCharm的直接按照上文操作即可
2.沒有的話請這樣操作:
sudo apt-get install Python-PackageName
packageName 就是你所需要安裝的庫的名稱。
windows下安裝:
1.首先確定你安裝了pip:
進入命令行(運行-CMD)輸入 pip --version
如果沒有報錯則證明你已經安裝,可以繼續下面的步驟。
2.如果你已經有了PyCharm,可以像上面PyCharm部分所說的那樣操作
如果沒有的話你有兩種選擇,一是壓縮包,二是pip中打命令,這里說第二種
在命令行里輸入:
pip3 install packageName
packageName 就是你所需要安裝的庫的名稱
如果遇到權限問題,請輸入:
sudo pip install packageName
安裝成功后會提示:
Successfully installed PackageName
如果你是python 2. 那么把pip3換成pip即可。
關于大數據中如何爬取一個網站的信息問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





