溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了python爬取美團網站信息的示例分析,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Proxy-Connection': 'keep-alive',
'Host': 'chs.meituan.com',
'Referer': 'http://chs.meituan.com/',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
'Content-Type': 'text/html;charset=utf-8',
'Cookie': '_lxsdk_cuid=164c9bed44ac8-0bf488e0cbc5d9-5b193413-1fa400-164c9bed44bc8; __mta=248363576.1532393090021.1532393090021.1532393090021.1; rvct=70%2C1; ci=70; iuuid=30CB504DBAC7CCDD72645E3809496C48229D8143D427C01A5532A4DDB0D42388; cityname=%E9%95%BF%E6%B2%99; _lxsdk=30CB504DBAC7CCDD72645E3809496C48229D8143D427C01A5532A4DDB0D42388; _ga=GA1.2.1889738019.1532505689; uuid=2b2adb1787947dbe0888.1534733150.0.0.0; oc=d4TCN9aIiRPd6Py96Y94AGxfsjATZHPGsCDua9-Z_NQHsXDcp6WlG2x7iJpYzpSLttNvEucwm_D_SuJ7VRJkLcjqV6Nk8s_q3VyOJw5IsVJ6RJPL3qCgybGW3vxTkMHr9A4yChReTafbZ7f93F1PkCyUeFBQV4D-YXoVoFV5h4o; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; client-id=97664882-24cd-4743-b21c-d25de878708e; lat=28.189822; lng=112.97422; _lxsdk_s=165553df04a-bc8-311-ba7%7C%7C6',
}
這樣直接插入代碼有點難看,湊合看,這就是能訪問到的headers。直接放到框架中,就可以了,但是還是會出現重定向到403頁面和跑到驗證碼頁面的情況發生,所以還是需要做處理,可以匹配響應的url是否一致,如果不一致的話,怎么處理,只提供思路,代碼我還在完善
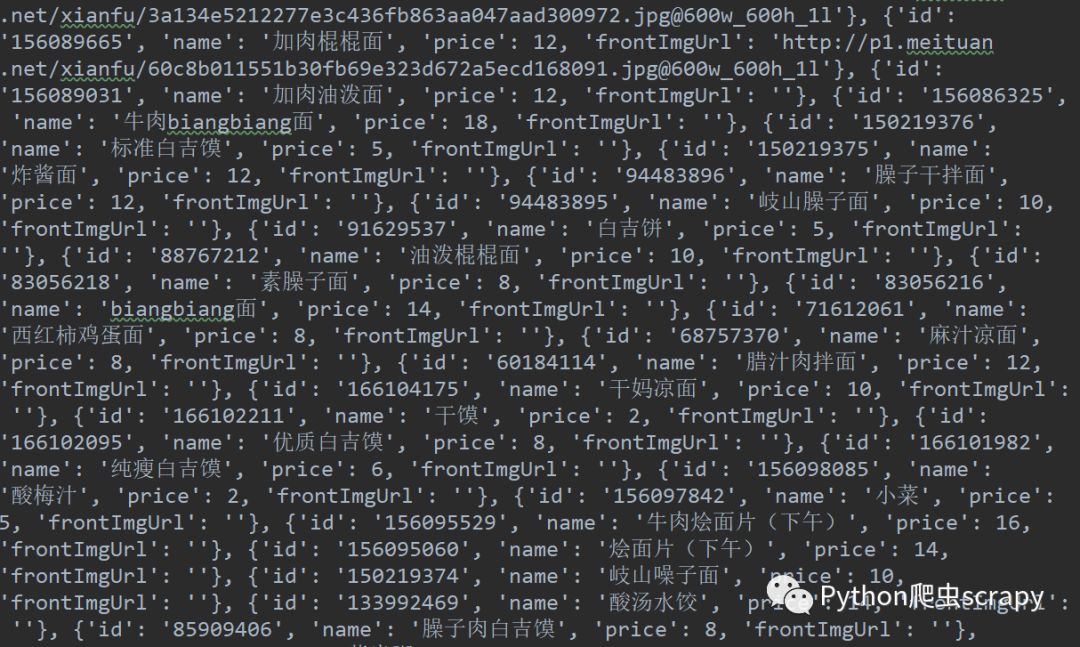
這就是獲取數據到以后打印的日志
具體的評論的詳細信息,后面再重新獲取,現在的數據放在一個集合有點亂。
詳細代碼:
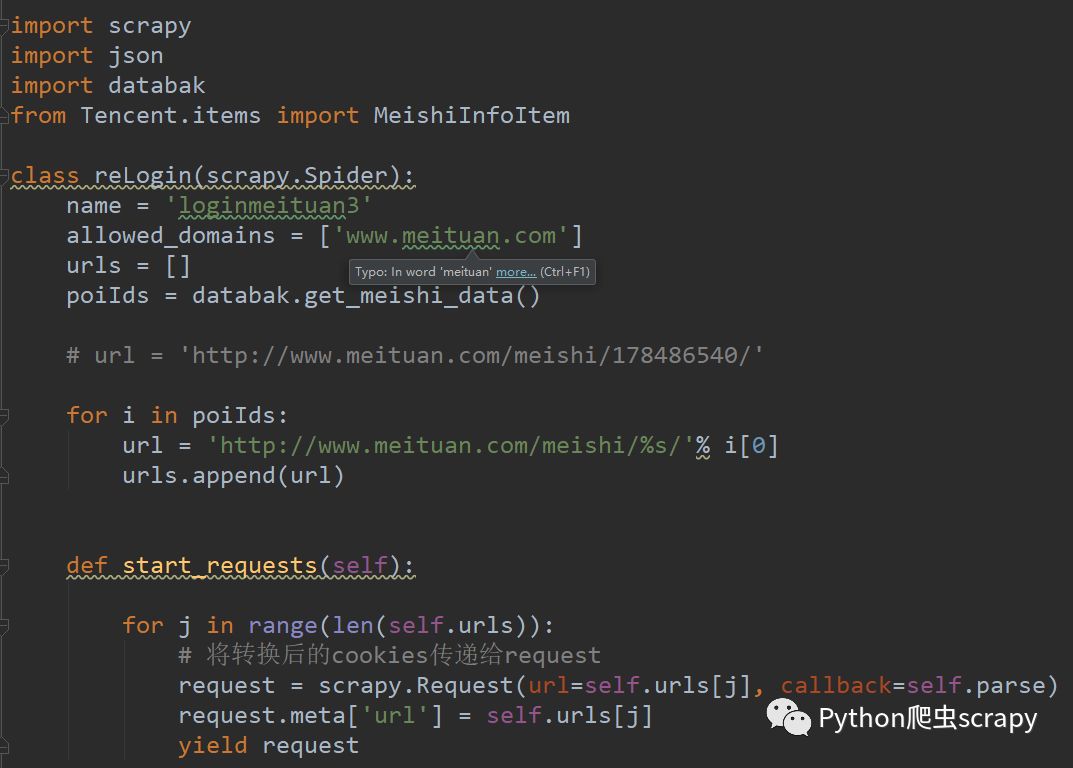
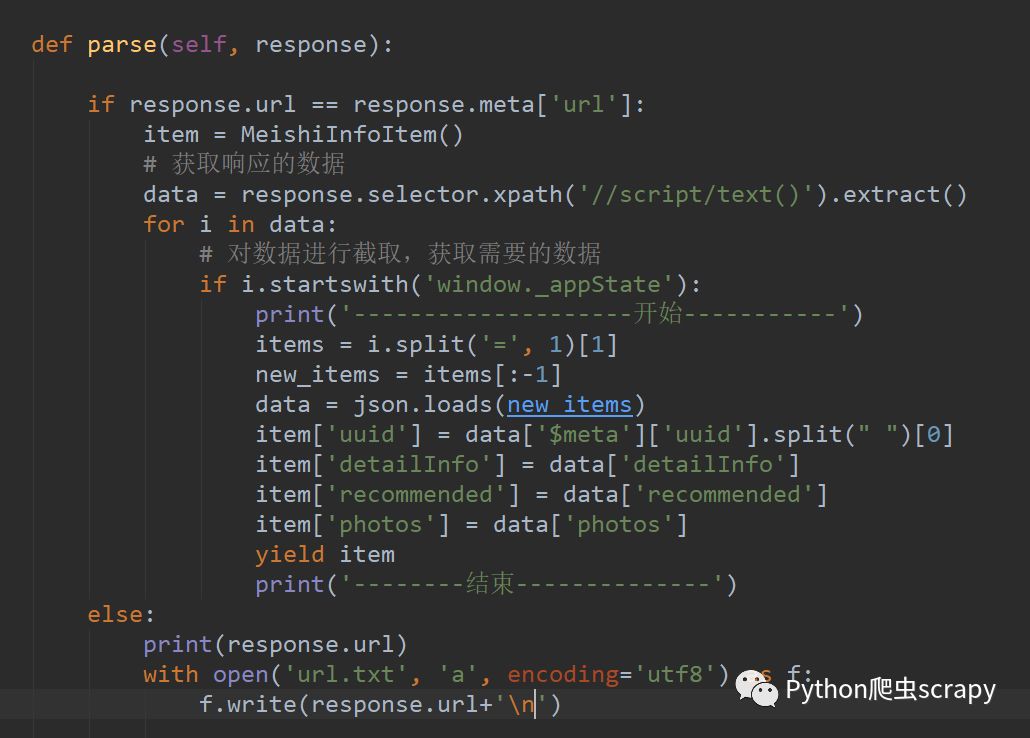
代碼不夠完善,而且會碰到被重定向到驗證碼頁面,需要處理驗證碼,當請求次數過多以后需要使用代理ip,這些都是需要解決的,現在貼出來的代碼還有許多問題,有厲害的可以幫幫忙!
感謝你能夠認真閱讀完這篇文章,希望小編分享的“python爬取美團網站信息的示例分析”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





