溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天給大家介紹一下Transformer的原理及與RNN encoder-decoder比較是怎樣的。文章的內容小編覺得不錯,現在給大家分享一下,覺得有需要的朋友可以了解一下,希望對大家有所幫助,下面跟著小編的思路一起來閱讀吧。
1、與RNN encoder-decoder比較
靠attention機制,不使用rnn和cnn,并行度高
通過attention,抓長距離依賴關系比rnn強
transformer的特征抽取能力比RNN系列模型好,seq2seq最大的問題將encoder端的所有信息壓縮到一個固定長度的張量中。
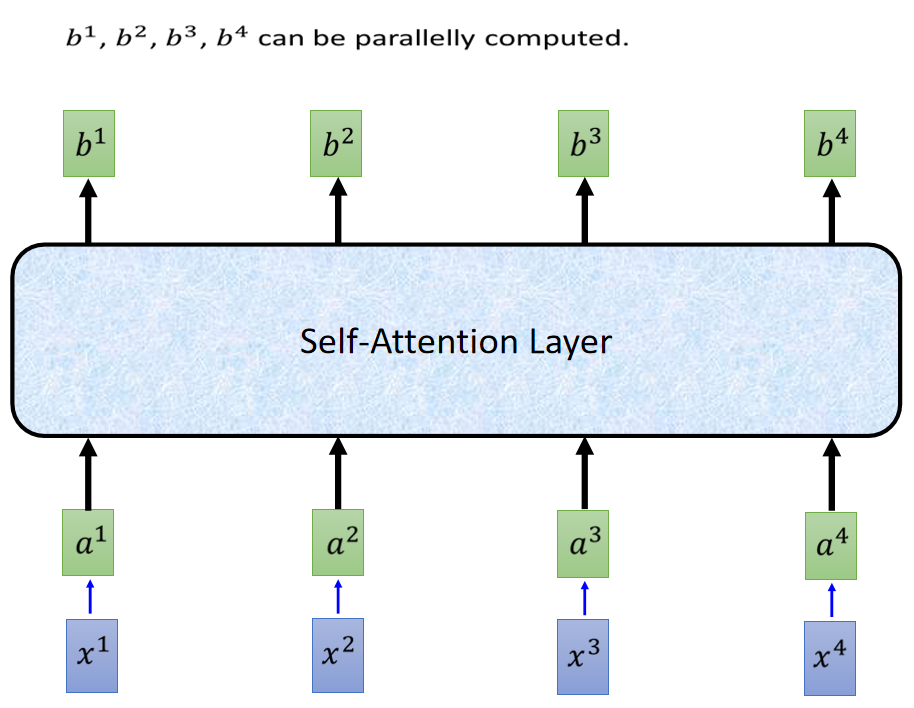
2. Transformer認識
1) RNN(LSTM, GRU)訓練時迭代,串行的,需等當前詞處理完,再處理下一個詞。Transformer的訓練(encoder,decoder)是并行的,所有詞是同時訓練 ,增加了計算效率。

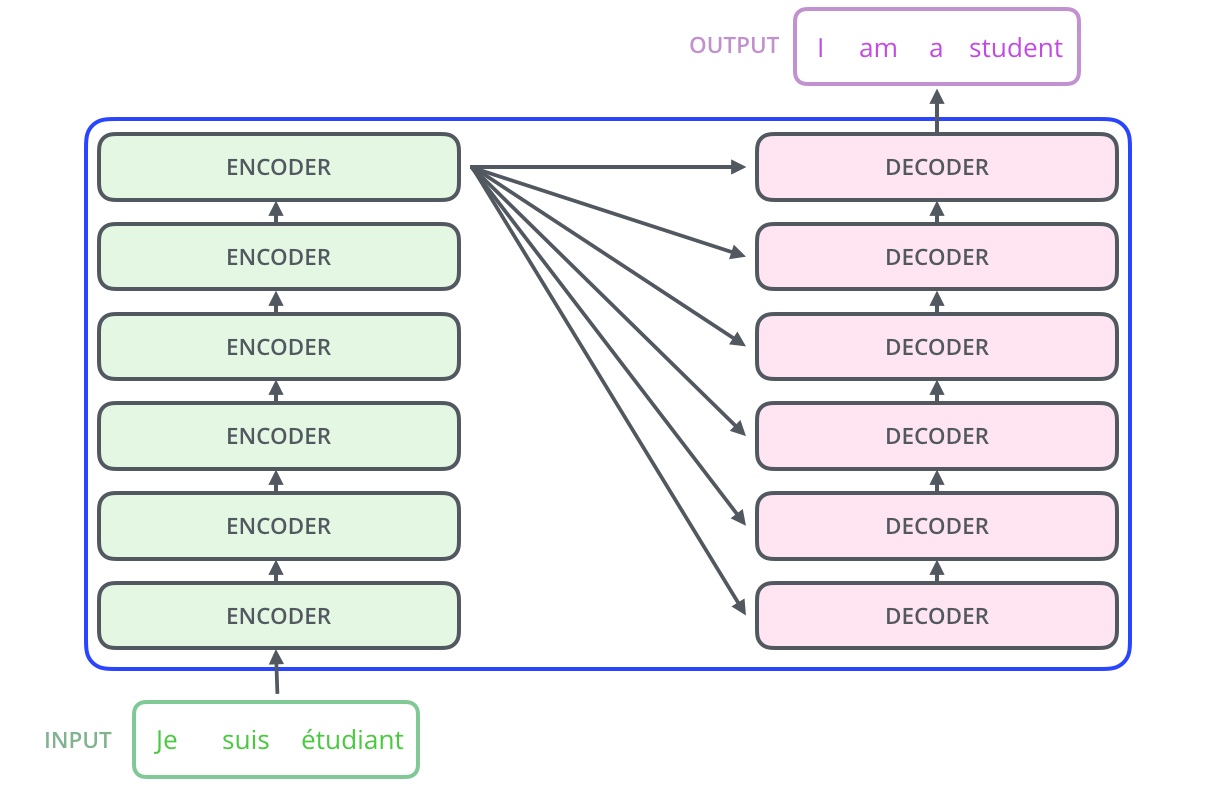
2) Transformer模型由Encoder和Decoder組成。
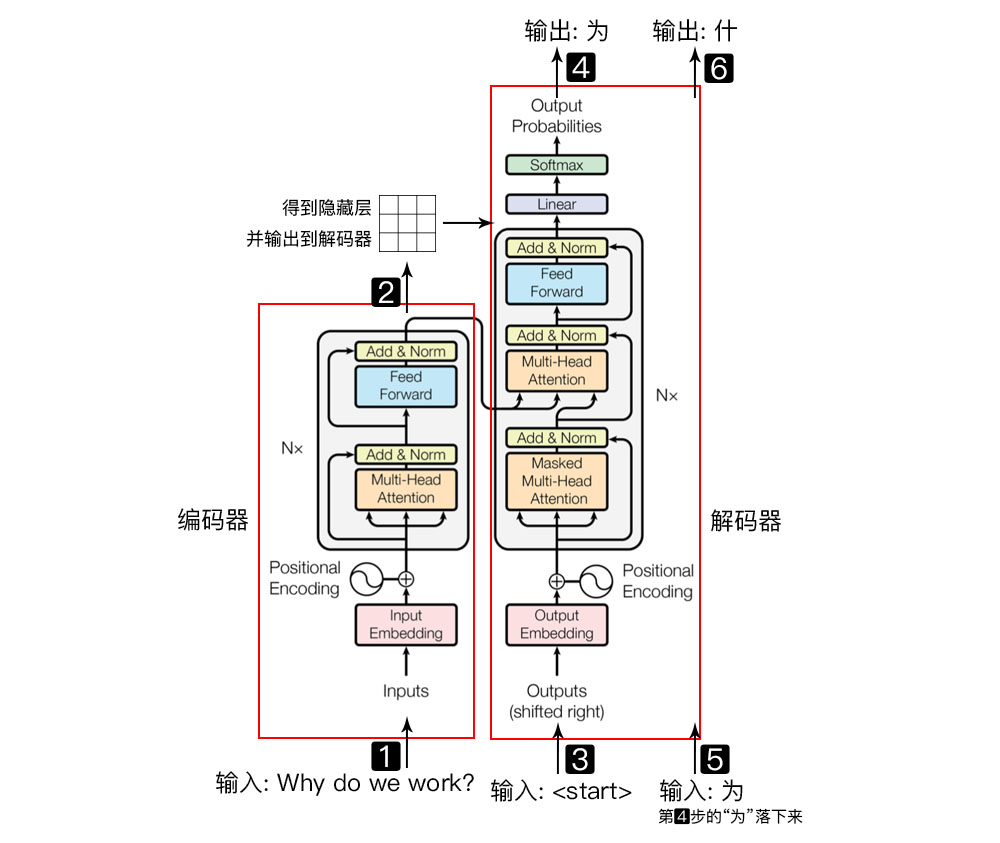
3. positional encoding
1)self-attention無RNN中的位置信息,在embedding input后加上positional.
2)位置編碼采用二進制表示浪費空間,滿足三個條件即可,它應該為每個字輸出唯一的編碼;不同長度的句子之間,任何兩個字之間的差值應該保持一致;它的值應該是有界的。sin, cos是連續且可導。
3)公式: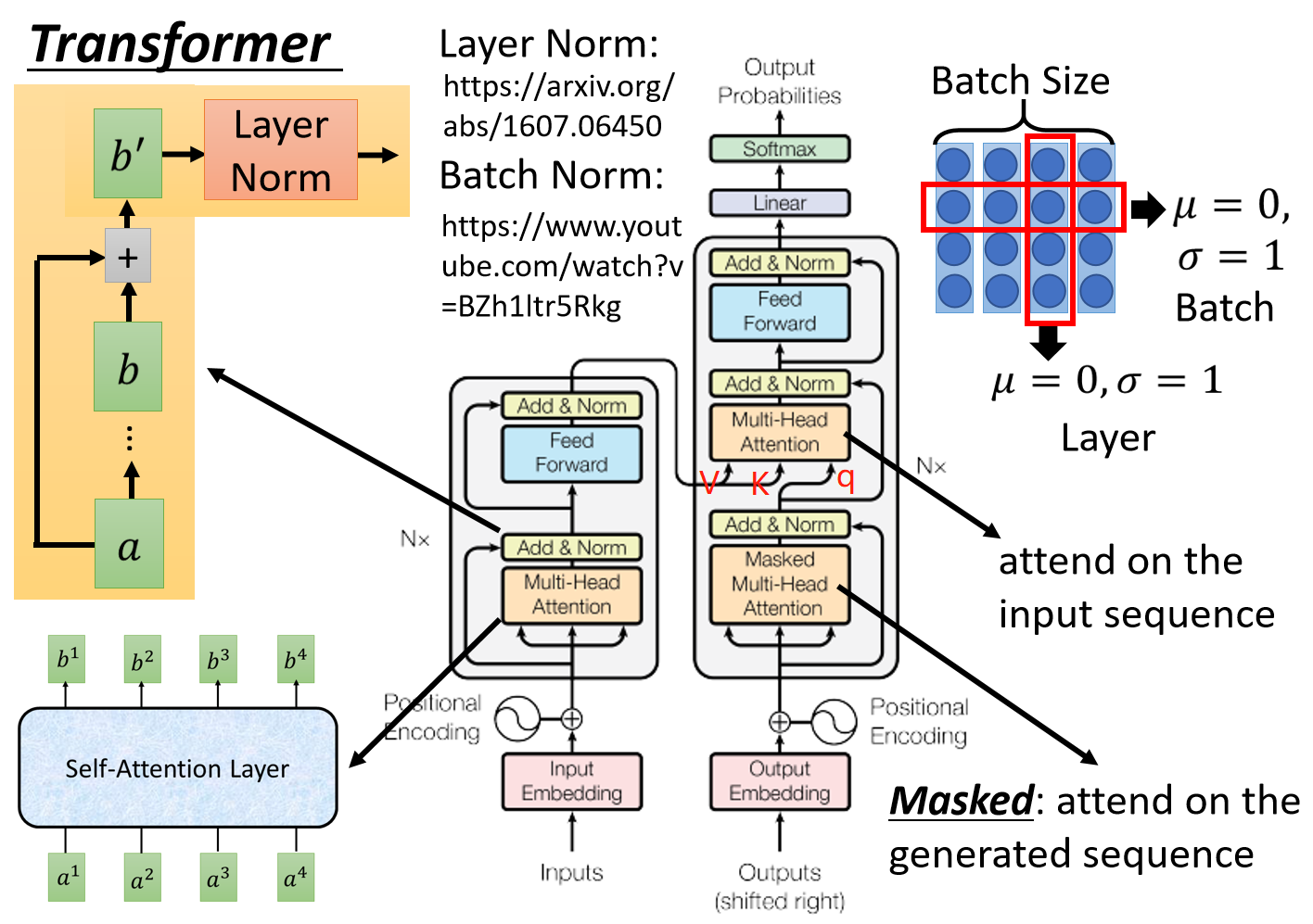
1)殘差網絡:b` = b + a, b = (attention or feed farward)(a)
2)歸一化:與RNN搭配的是Layer Normalization, Transformer用LN
3) BN和LN的區別,BN在batch層對同一個dimention做normalization, 均值為0,方差為1;LN不考慮batch層,不同dimention的均值mean為0,方差為1.
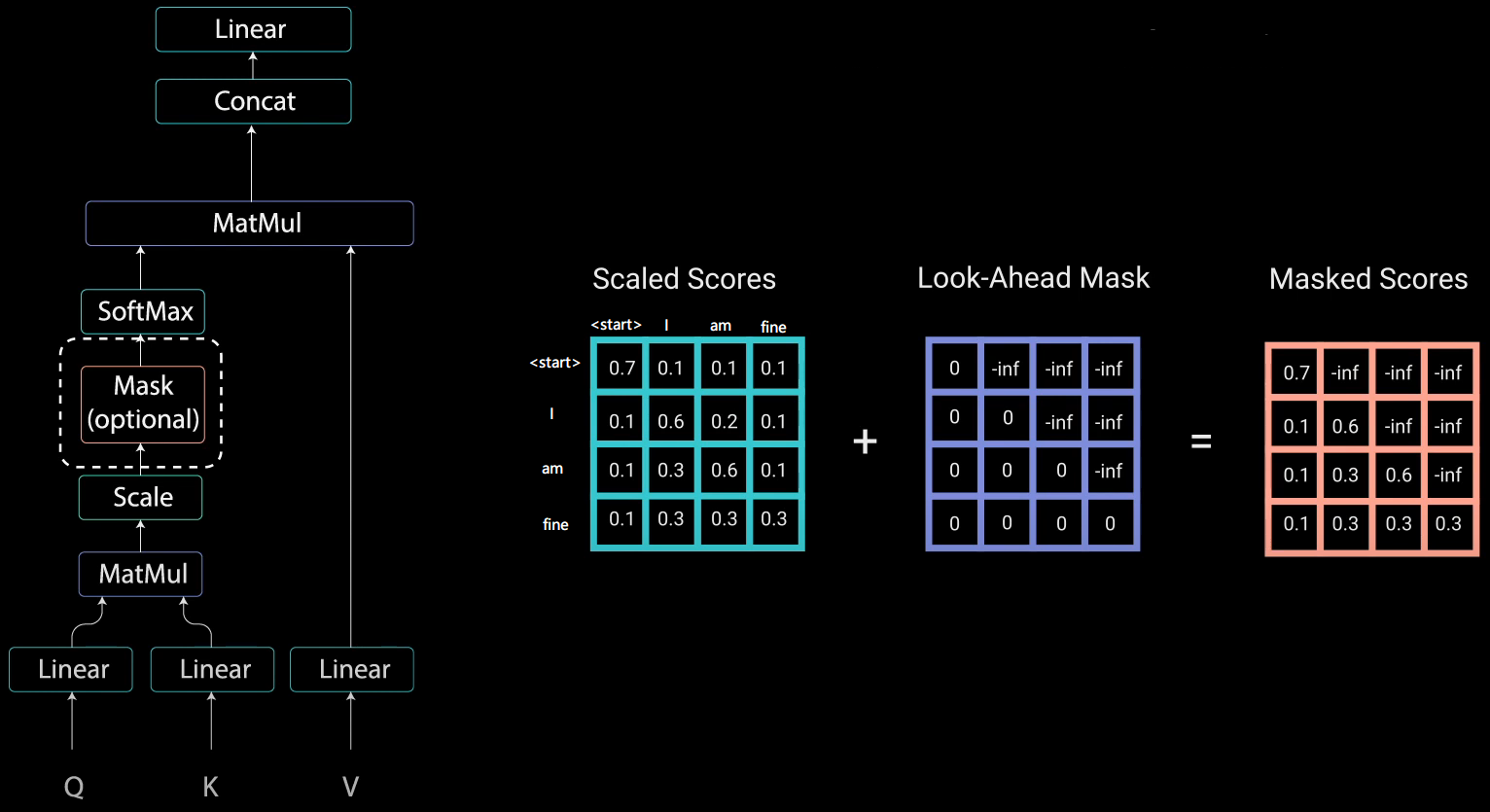
5. mask
1) padding mask
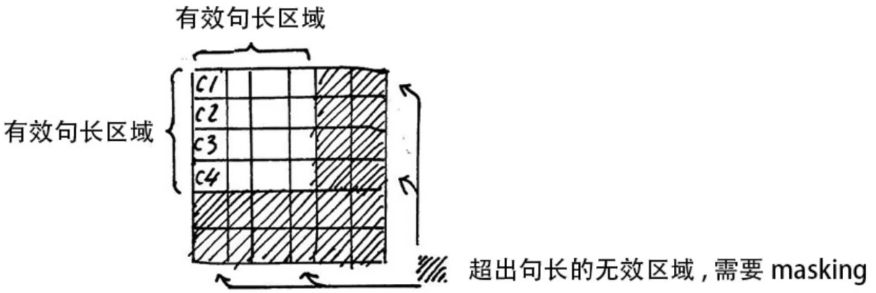
在softmax時對0也會進行運算,exp(0)=1, 這樣讓無效的部分參與了運算,會產生隱患,所以需做一個mask操作,讓無效區域不參與運算,一般讓無效區域加一個很大的負數偏置。
Tips: 我們通常使用 mini-batch 來計算,也就是一次計算多句話,即x的維度是 [batch_size, seq_length],seq_length是句長,而一個 mini-batch 是由多個不等長的句子組成的,我們需要按照這個 mini-batch 中最大的句長對剩余的句子進行補齊,一般用 0 進行填充,這個過程叫做 padding.
2) squence mask
mask, 不給模型看到未來的信息。當Encoder的輸入是:機器學習,則decoder的輸入是:<start>machine learning
Transformer Decoder改為self-Attention, 在訓練過程中不像Seq2Seq中RNN的時間驅動機制(t時刻結束才能看到t+1時刻的詞),而使得所有未來詞暴露在Decoder中。Mask使得上三角的詞為0, softmax(-inf)=0
6. self-attention & multi-head attention
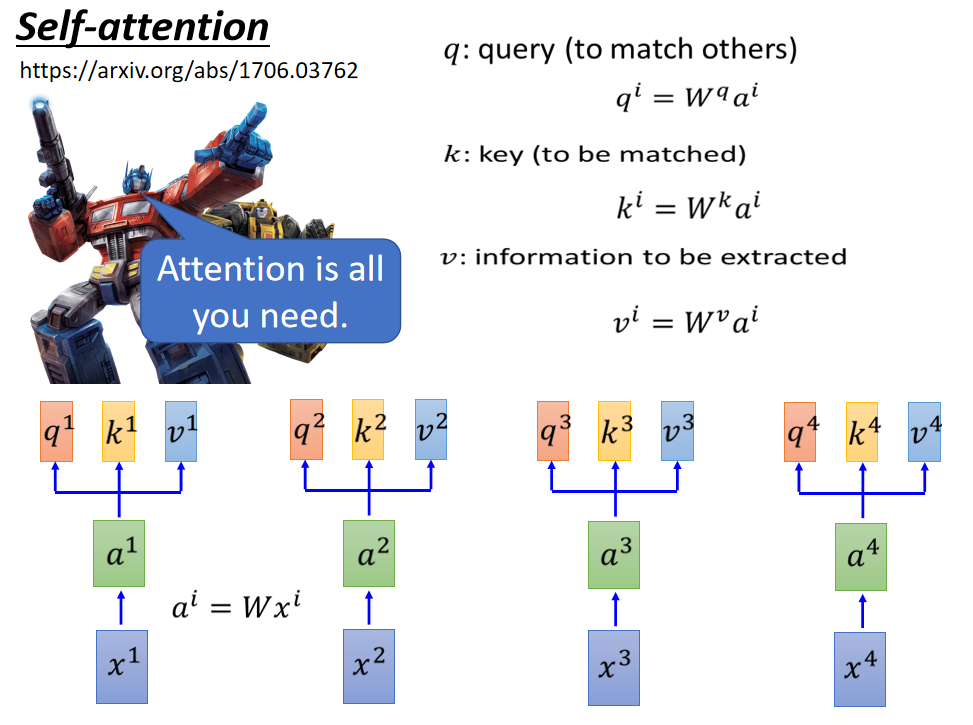
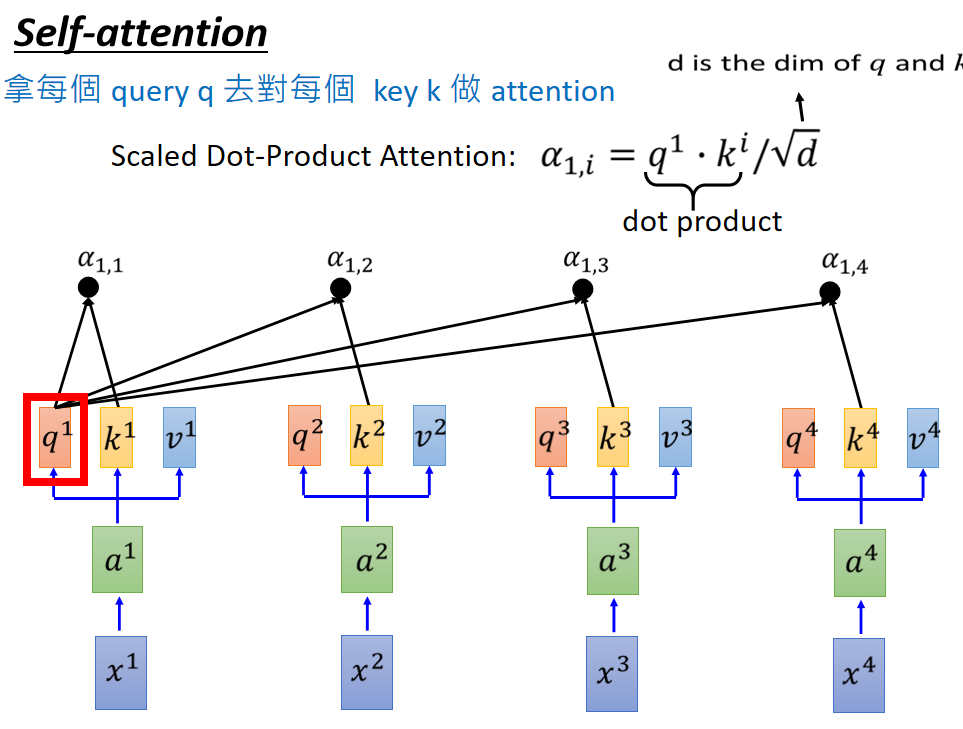

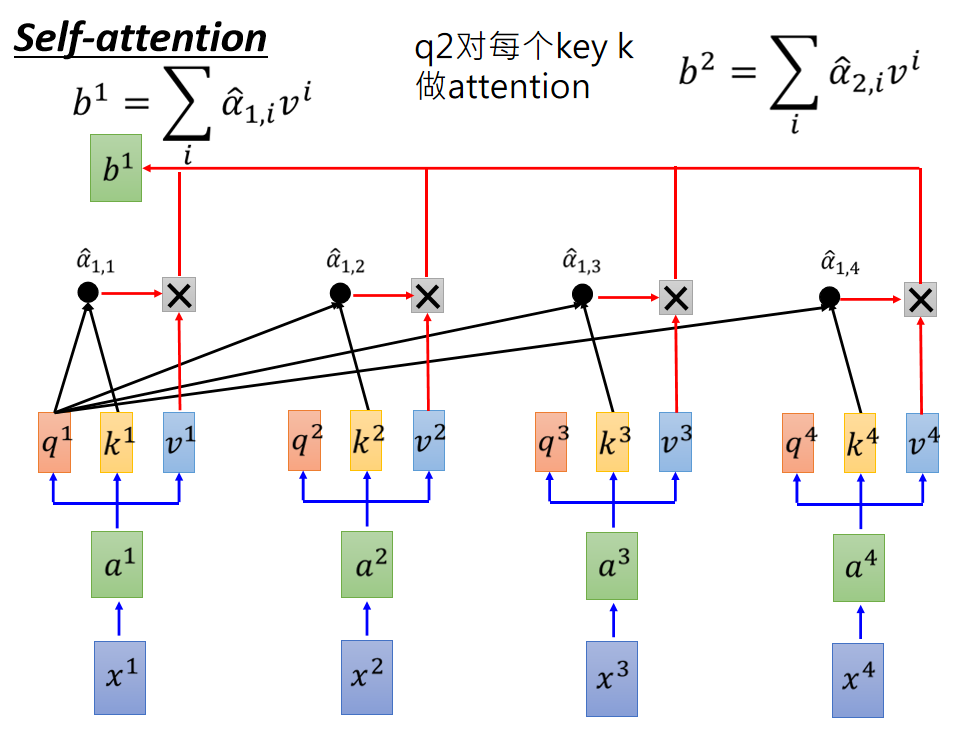
根據位置不同,分為self-attention和soft-attention
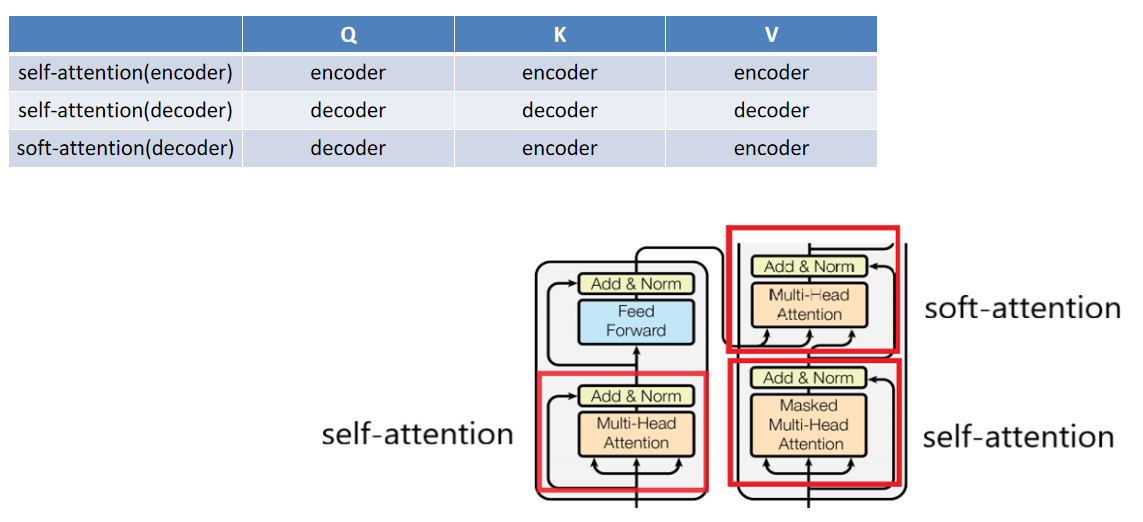
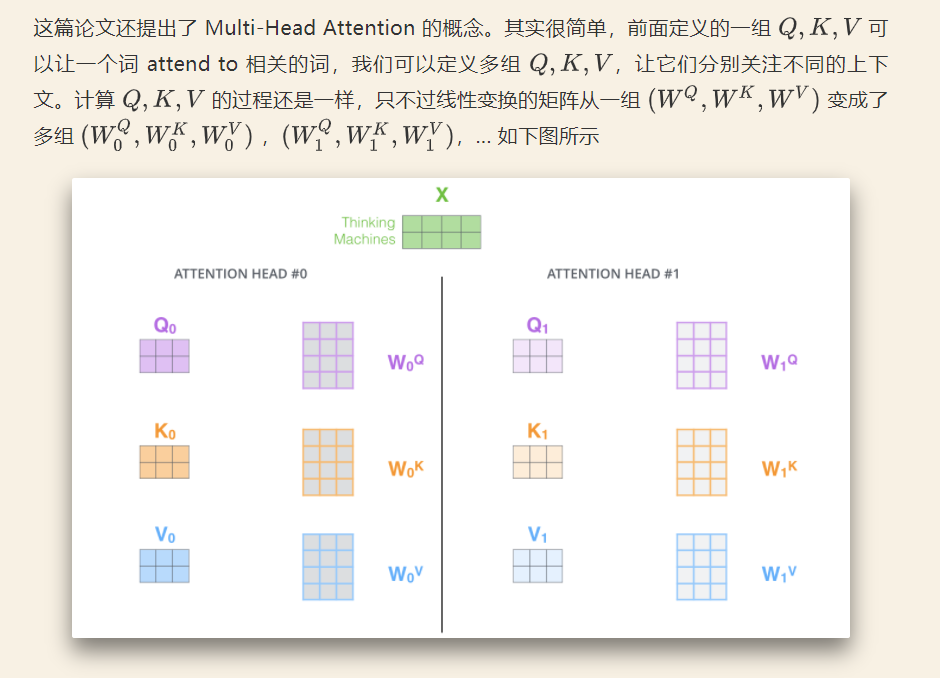
2) multi-head attention
multi-head可以去關注不同點,注意力側重點可以在不同方面,最后再將各方面的信息綜合起來,有助于捕捉到更豐富的特征。
以上就是Transformer的原理及與RNN encoder-decoder比較是怎樣的的全部內容了,更多與Transformer的原理及與RNN encoder-decoder比較是怎樣的相關的內容可以搜索億速云之前的文章或者瀏覽下面的文章進行學習哈!相信小編會給大家增添更多知識,希望大家能夠支持一下億速云!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





