溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了PLEK工具有什么用,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
在之前的文章中,我們介紹過CPC和CNCI這兩款軟件,可以用于預測lncRNA序列。其中CPC基于序列比對的方式,對于注釋信息相對全面的物種分類效果較好,但是運行速度相對較慢,CNCI基于序列的三聯體堿基組成來區分編碼和非編碼轉錄本,對于注釋信息缺乏的物種,效果也不錯,但是當序列中存在插入缺失時,其分類效果就變得很差。
在高通量測序產生的數據中,會存在一定的測序錯誤,雖然比例很低,但是基于這樣的序列組裝得到轉錄本然后去預測lncRNA, 對于CNCI這個軟件而言,就會造成相當大的影響。
為了克服上述問題,需要一款運行速度又快,又可以一定程度上降低測序錯誤影響的lncRNA預測軟件,PLEK軟件就是基于這樣的出發點進行開發的。PLEK軟件通過序列的kmer構成來區分編碼和非編碼轉錄本,不需要通過比對來完成,所以運行速度較快,同時其性能受到測序錯誤的影響的概率較低,比較穩定。
在論文中,開發者評估了測序錯誤對各個軟件準確度的影響,結果如下所示
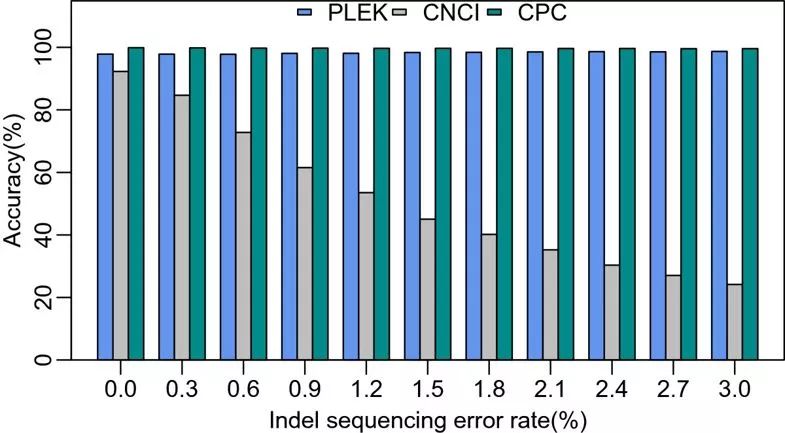
可以看到,隨著測序錯誤比例的上升,CNCI的準確度急劇下降,而PLEK和CPC的結果都相對穩定。
同時利用小鼠的轉錄本數據,評估了各個軟件分類的準確性,結果如下所示
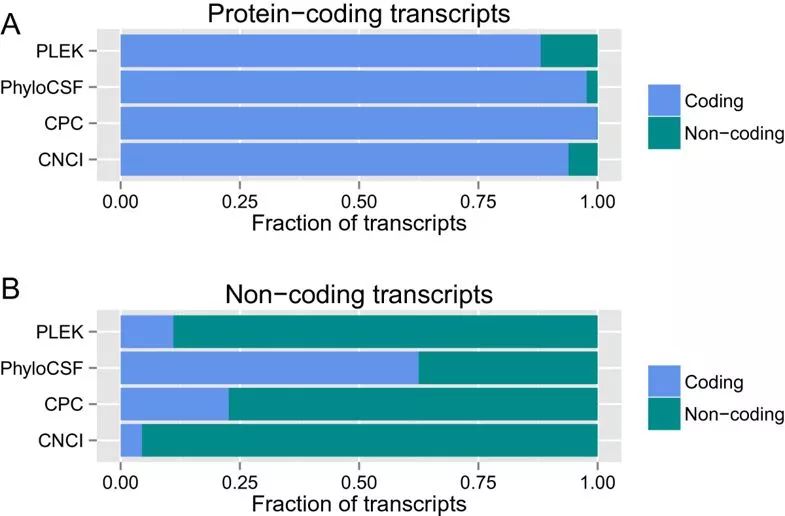
從蛋白編碼的轉錄本來看,CPC的準確率最高,PLEK誤判的概率最高;從非編碼轉錄本來看,CNCI的準確率最高,phyloCSF的誤判率最高。
綜合來看,PLEK的準確性介于CPC和CNCI之間,但是考慮到測序錯誤的影響,PLEK的優勢會更加明顯。
論文中對于各個軟件的運行效率,也進行了比較,結果如下

可以看到PLEK的運行速度是最快的。該軟件的源代碼托管在sourceforge上,網址如下
https://sourceforge.net/projects/plek/files/
安裝方式如下
wget https://sourceforge.net/projects/plek/files/PLEK.1.2.tar.gz tar xzvf PLEK.1.2.tar.gz cd PLEK.1.2 python PLEK_setup.py
基本用法如下
python PLEK.py \ -fasta transcript.fa \ -out output \ -thread 10
只需要輸入轉錄本對應的fasta格式的文件就可以了,輸出文件output內容示意如下
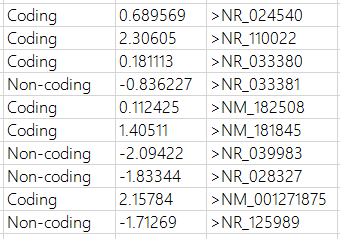
第一列代表該轉錄本為coding還是non-coding, 第二列為打分值,打分值大于0為coding, 小于零為non-coding, 第三列為fasta文件中的序列標識符。
默認情況下會調用內置的svm模型,如果你有該物種已知的mRNA和lncRNA轉錄本序列,也可以構建自己的模型,代碼如下
python PLEKModelling.py \ -mRNA mRNAs.fa \ -lncRNA lncRNAs.fa \ -prefix 20190129
運行成功后,會生成后綴為.model和.range的兩個文件。在預測時可以通過參數指定svm模型,用法如下
python PLEK.py \ -fasta transcript.fa \ -out output \ -model 20190129.model -range 20190129.range \ -thread 10
感謝你能夠認真閱讀完這篇文章,希望小編分享的“PLEK工具有什么用”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





