溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下DataX工具有什么用,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
DataX是一個異構數據源離線同步工具,致力于實現包括關系型數據庫(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各種異構數據源之間穩定高效的數據同步功能。解決異構數據源同步問題,DataX將復雜的網狀的同步鏈路變成了星型數據鏈路,DataX作為中間傳輸載體負責連接各種數據源。當需要接入一個新的數據源的時候,只需要將此數據源對接到DataX,便能跟已有的數據源做到無縫數據同步。
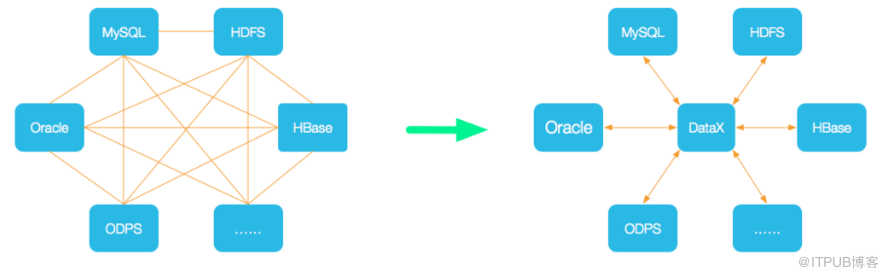
絮叨一句:異構數據源指,為了處理不同種類的業務,使用不同的數據庫系統存儲數據。
DataX本身作為離線數據同步框架,采用Framework+plugin架構構建。將數據源讀取和寫入抽象成為Reader和Writer插件,納入到整個同步框架中。

Reader
Reader為數據采集模塊,負責讀取采集數據源的數據,將數據發送給Framework。
Writer
Writer為數據寫入模塊,負責不斷向Framework取數據,并將數據寫入到目的端。
Framework
Framework用于連接reader和writer,作為兩者的數據傳輸通道,并處理緩沖,流控,并發,數據轉換等核心技術問題。
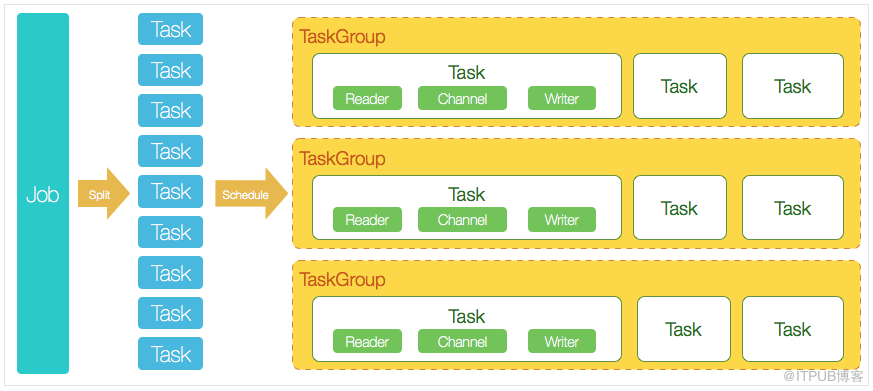
Job
DataX完成單個數據同步的作業,稱為Job,DataX接受到一個Job之后,將啟動一個進程來完成整個作業同步過程。Job模塊是單個作業的中樞管理節點,承擔了數據清理、子任務切分(將單一作業計算轉化為多個子Task)、TaskGroup管理等功能。
Split
DataXJob啟動后,會根據不同的源端切分策略,將Job切分成多個小的Task(子任務),以便于并發執行。Task便是DataX作業的最小單元,每一個Task都會負責一部分數據的同步工作。
Scheduler
切分多個Task之后,Job會調用Scheduler模塊,根據配置的并發數據量,將拆分成的Task重新組合,組裝成TaskGroup(任務組)。
TaskGroup
每一個TaskGroup負責以一定的并發運行完畢分配好的所有Task,默認單個任務組的并發數量為5。每一個Task都由TaskGroup負責啟動,Task啟動后,會固定啟動Reader—>Channel—>Writer的線程來完成任務同步工作。DataX作業運行起來之后,Job監控并等待多個TaskGroup模塊任務完成,等待所有TaskGroup任務完成后Job成功退出。否則,異常退出,進程退出值非0。
推薦Python2.6+,Jdk1.8+(腦補安裝流程)。
# yum -y install wget # wget https://www.python.org/ftp/python/2.7.15/Python-2.7.15.tgz # tar -zxvf Python-2.7.15.tgz
# yum install gcc openssl-devel bzip2-devel [root@ctvm01 Python-2.7.15]# ./configure --enable-optimizations # make altinstall # python -V
# pwd /opt/module # ll datax # cd /opt/module/datax/bin -- 測試環境是否正確 # python datax.py /opt/module/datax/job/job.json
-- PostgreSQL
CREATE TABLE sync_user (
id INT NOT NULL,
user_name VARCHAR (32) NOT NULL,
user_age int4 NOT NULL,
CONSTRAINT "sync_user_pkey" PRIMARY KEY ("id")
);
CREATE TABLE data_user (
id INT NOT NULL,
user_name VARCHAR (32) NOT NULL,
user_age int4 NOT NULL,
CONSTRAINT "sync_user_pkey" PRIMARY KEY ("id")
);[root@ctvm01 job]# pwd /opt/module/datax/job [root@ctvm01 job]# vim postgresql_job.json
{
"job": {
"setting": {
"speed": {
"channel": "3"
}
},
"content": [
{
"reader": {
"name": "postgresqlreader",
"parameter": {
"username": "root01",
"password": "123456",
"column": ["id","user_name","user_age"],
"connection": [
{
"jdbcUrl": ["jdbc:postgresql://192.168.72.131:5432/db_01"],
"table": ["data_user"]
}
]
}
},
"writer": {
"name": "postgresqlwriter",
"parameter": {
"username": "root01",
"password": "123456",
"column": ["id","user_name","user_age"],
"connection": [
{
"jdbcUrl": "jdbc:postgresql://192.168.72.131:5432/db_01",
"table": ["sync_user"]
}
],
"postSql": [],
"preSql": []
}
}
}
]
}
}# /opt/module/datax/bin/datax.py /opt/module/datax/job/postgresql_job.json
2020-04-23 18:25:33.404 [job-0] INFO JobContainer - 任務啟動時刻 : 2020-04-23 18:25:22 任務結束時刻 : 2020-04-23 18:25:33 任務總計耗時 : 10s 任務平均流量 : 1B/s 記錄寫入速度 : 0rec/s 讀出記錄總數 : 2 讀寫失敗總數 : 0
注意:這里源碼只貼出核心流程,如果要看完整源碼,可以自行從Git上下載。
核心入口:PostgresqlReader
啟動讀任務
public static class Task extends Reader.Task {
@Override
public void startRead(RecordSender recordSender) {
int fetchSize = this.readerSliceConfig.getInt(com.alibaba.datax.plugin.rdbms.reader.Constant.FETCH_SIZE);
this.commonRdbmsReaderSlave.startRead(this.readerSliceConfig, recordSender,
super.getTaskPluginCollector(), fetchSize);
}
}讀取任務啟動之后,執行讀取數據操作。
核心類:CommonRdbmsReader
public void startRead(Configuration readerSliceConfig,
RecordSender recordSender,
TaskPluginCollector taskPluginCollector, int fetchSize) {
ResultSet rs = null;
try {
// 數據讀取
rs = DBUtil.query(conn, querySql, fetchSize);
queryPerfRecord.end();
ResultSetMetaData metaData = rs.getMetaData();
columnNumber = metaData.getColumnCount();
PerfRecord allResultPerfRecord = new PerfRecord(taskGroupId, taskId, PerfRecord.PHASE.RESULT_NEXT_ALL);
allResultPerfRecord.start();
long rsNextUsedTime = 0;
long lastTime = System.nanoTime();
// 數據傳輸至交換區
while (rs.next()) {
rsNextUsedTime += (System.nanoTime() - lastTime);
this.transportOneRecord(recordSender, rs,metaData, columnNumber, mandatoryEncoding, taskPluginCollector);
lastTime = System.nanoTime();
}
allResultPerfRecord.end(rsNextUsedTime);
}catch (Exception e) {
throw RdbmsException.asQueryException(this.dataBaseType, e, querySql, table, username);
} finally {
DBUtil.closeDBResources(null, conn);
}
}核心接口:RecordSender(發送)
public interface RecordSender {
public Record createRecord();
public void sendToWriter(Record record);
public void flush();
public void terminate();
public void shutdown();
}核心接口:RecordReceiver(接收)
public interface RecordReceiver {
public Record getFromReader();
public void shutdown();
}核心類:BufferedRecordExchanger
class BufferedRecordExchanger implements RecordSender, RecordReceiver
核心入口:PostgresqlWriter
啟動寫任務
public static class Task extends Writer.Task {
public void startWrite(RecordReceiver recordReceiver) {
this.commonRdbmsWriterSlave.startWrite(recordReceiver, this.writerSliceConfig, super.getTaskPluginCollector());
}
}寫數據任務啟動之后,執行數據寫入操作。
核心類:CommonRdbmsWriter
public void startWriteWithConnection(RecordReceiver recordReceiver,
Connection connection) {
// 寫數據庫的SQL語句
calcWriteRecordSql();
List<Record> writeBuffer = new ArrayList<>(this.batchSize);
int bufferBytes = 0;
try {
Record record;
while ((record = recordReceiver.getFromReader()) != null) {
writeBuffer.add(record);
bufferBytes += record.getMemorySize();
if (writeBuffer.size() >= batchSize || bufferBytes >= batchByteSize) {
doBatchInsert(connection, writeBuffer);
writeBuffer.clear();
bufferBytes = 0;
}
}
if (!writeBuffer.isEmpty()) {
doBatchInsert(connection, writeBuffer);
writeBuffer.clear();
bufferBytes = 0;
}
} catch (Exception e) {
throw DataXException.asDataXException(
DBUtilErrorCode.WRITE_DATA_ERROR, e);
} finally {
writeBuffer.clear();
bufferBytes = 0;
DBUtil.closeDBResources(null, null, connection);
}
}以上是“DataX工具有什么用”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





