溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
R語言如何實現分層抽樣Stratified ,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
1.觀察數據集
head(iris)
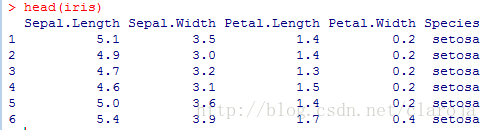
選取數據集中前6個數據,我們可以看出iris數據集一共有5個字段。
dim(iris)

iris數據集一共有150條數據,5個字段
summary(iris)
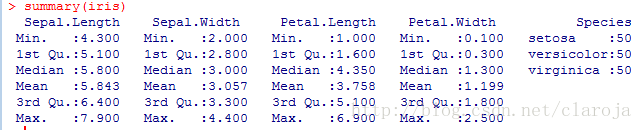
觀察各個變量的內容,可以看出前四個變量(Sepal.Length Sepal.Width Petal.Length Petal.Width)都是定量變量,而最后一個(Species)是定性變量,我們將依據最后一個變量作為分層抽樣的依據。
library(sampling)
載入分層抽樣的包sampling
n=round(3/5*nrow(iris)/3)
計算每一個種類的抽樣數目。這里我們按照每種“Species”抽取3/5個樣本進行抽樣。
sub_train=strata(iris,stratanames=("Species"),size=rep(n,3),method="srswor")head(sub_train)stratanames參數是抽樣依據的變量,size參數是每個種類抽樣的數目,這里我們用上一步計算出來的n作為抽樣數目,method是抽樣方法,我們選擇srswor。
data_train=iris[sub_train$ID_unit,] data_test=iris[-sub_train$ID_unit,]
將抽樣結果分別定義為訓練集(data_train)和測試集(data_test)。
dim(data_train); dim(data_test)

觀察訓練集和測試集的字段和數據數目。符合我們的抽樣預期。
head(data_train);head(data_test)

觀察訓練集和測試集的前幾條數據。
data_train;data_test
查看總的抽樣結果,這里數據量太大不再給出。
write.csv(data_train,"C:/Users/cnrozh/Desktop/iris_data_train.csv")write.csv(data_test,"C:/Users/cnrozh/Desktop/iris_data_test.csv")
保存數據集
關于 R語言如何實現分層抽樣Stratified 問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





