溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
我們上篇文章中講了,RDD的持久化是spark優化中必須掌握的,并且,在內存不足的情況下,我們可以將持久化類型選擇為MEMORY_ONLY_SER,減少內存的占用,持久化更多的partition,并且不同的序列化方法也會影響序列化性能。
下面,我們就來測試下,持久化級別和序列化方法的選擇對RDD持久化大小的影響。
我選擇了一個170.9MB的日志文件,傳到了百度網盤
提取碼:ffae
測試環境是windows,
IDEA參數配置

代碼為
case class CleanedLog(cdn:String,region:String,level:String,date:String,ip:String, domain:String, url:String, traffic:String)
object KyroTest {
def main(args: Array[String]) {
val inputPath=new Path(args(0))
val outputPath=new Path(args(1))
val fsConf=new Configuration()
val fs= FileSystem.get(fsConf)
if (fs.exists(outputPath)) {
fs.delete(outputPath,true)
val path=args(1).toString
println(s"已刪除已存在的路徑$path")
}
val conf = new SparkConf().setMaster("local[2]").setAppName("KyroTest")
//conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
//conf.set("spark.kryo.registrationRequired", "true")
val sc = new SparkContext(conf)
val logs = sc.textFile(args(0))
//logs.filter(_.split("\t").length==8).take(10).foreach(println(_))
val logsCache=logsCahe(logs)
//序列化的方式將rdd存到內存
saveAtLocal(logsCache,args(1))
Thread.sleep(100000)
}
def logsCahe(logs:RDD[String]): RDD[CleanedLog] ={
logs.filter(_.split("\t").length==8).map(x=>{
val fields=x.split("\t")
CleanedLog(fields(0),fields(1),fields(2),fields(3),fields(4),fields(5),fields(6),fields(7))
}).cache()
}
def saveAtLocal(logsCache: RDD[CleanedLog], outputPath: String) = {
logsCache.map(x=>{
x.cdn+"\t"+x.region+"\t"+x.level+"\t"+x.date+"\t"+x.ip+"\t"+x.domain+"\t"+x.url+"\t"+x.traffic
}).repartition(1).saveAsTextFile(outputPath)
}
}代碼邏輯就是輸入是什么內容,輸就是什么內容,在中間我將輸入的文本RDD進行了memory_only持久化,我們就看這個持久化內存占多少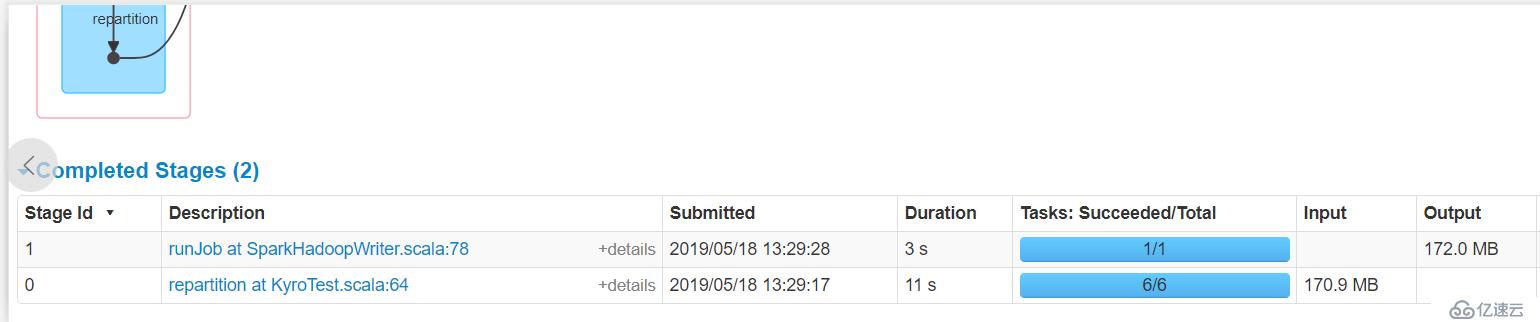

顯然,input size大小是170.9 MB,但是持久化之后是908.5 MB,顯然占據內存空間增大了好幾倍,如果在生產上,內存資源不足的情況下,這種方式顯然緩存不了不少partition
時間耗費14s
def logsCahe(logs:RDD[String]): RDD[CleanedLog] ={
logs.filter(_.split("\t").length==8).map(x=>{
val fields=x.split("\t")
CleanedLog(fields(0),fields(1),fields(2),fields(3),fields(4),fields(5),fields(6),fields(7))
}).persist(StorageLevel.MEMORY_ONLY_SER)代碼僅更改了persist(StorageLevel.MEMORY_ONLY_SER)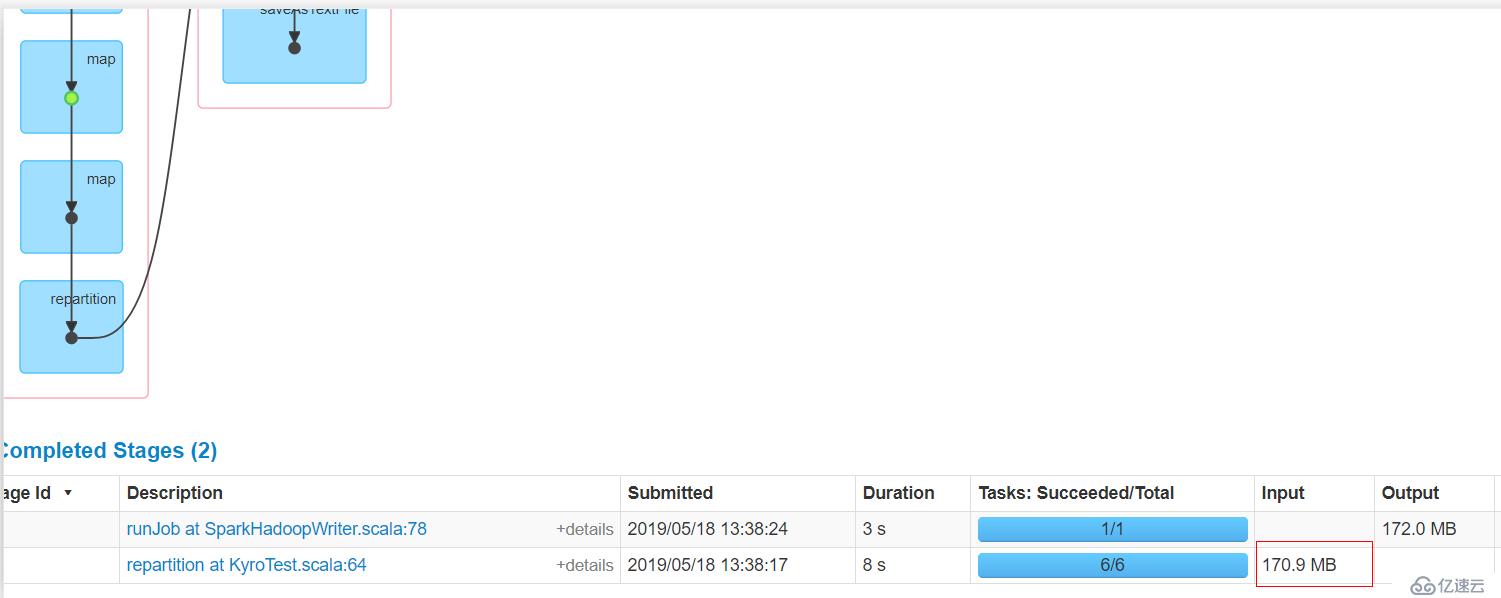

顯然,input size大小是170.9 MB,但是持久化之后是有204.9MB,所以序列化對于節約內存空間是很有幫助的。
時間耗費11s
val conf = new SparkConf().setMaster("local[2]").setAppName("KyroTest")
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")與上一代碼相比,為SparkConf設置了開啟kryo序列化,不是默認的java序列化了,但是沒有進行具體的類注冊!

顯然,input size大小是170.9 MB,但是持久化之后是有230.8MB,使用未注冊的kryo序列化竟然比使用java序列化還臃腫!原因是:每一個對象實例的序列化結果都會包含一份完整的類名,造成了大量的空間浪費!
時間是9s,比java序列化快了一些。
val conf = new SparkConf().setMaster("local[2]").setAppName("KyroTest")
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
conf.registerKryoClasses(Array(classOf[CleanedLog], classOf[String]))添加了String類和自定義樣例類的kryo注冊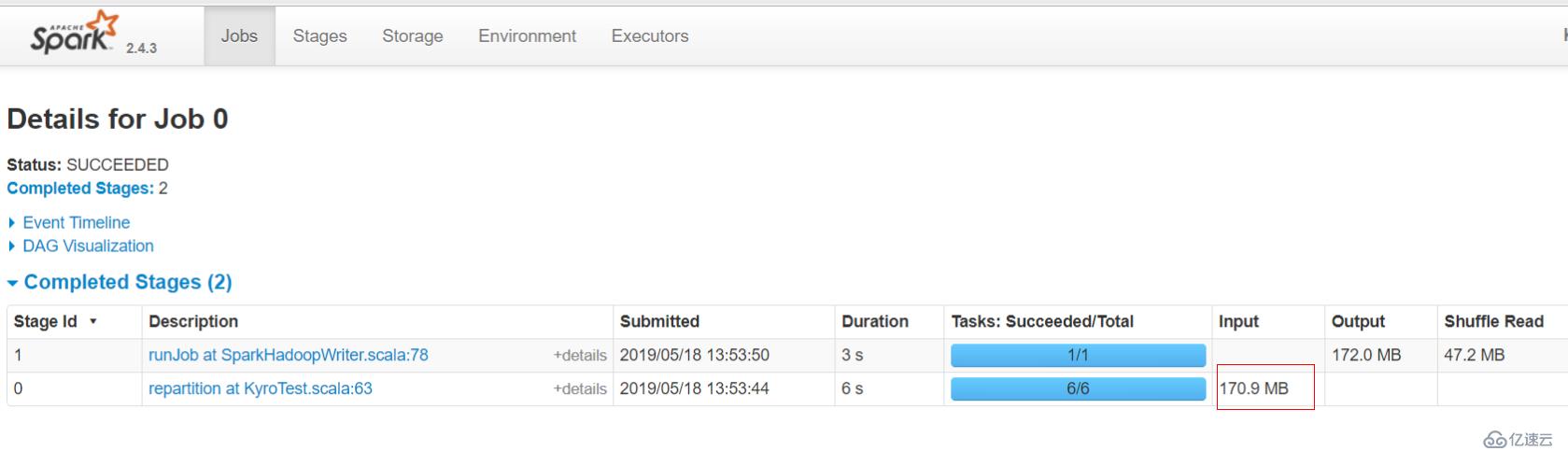
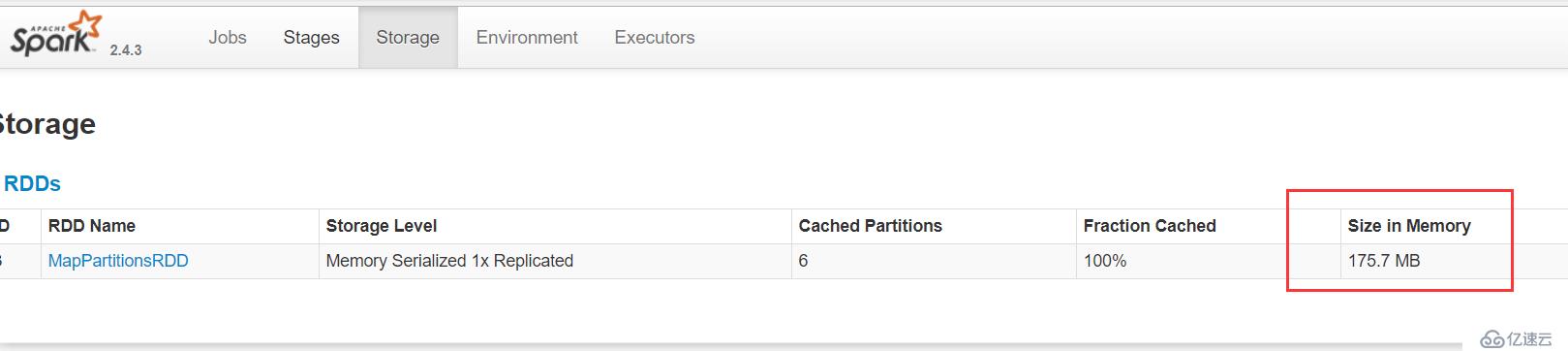
顯然,input size大小是170.9 MB,使用注冊的kryo序列化之后,只有175.7MB,時間也才9秒,很舒服!
所以在目前為止,使用kryo序列化并注冊是性能最好得了!!!
如果CPU還是那么悠閑的話,我們還有另外一個進一步優化點!
注意:RDD壓縮只能存在于序列化的情況下
val conf = new SparkConf().setMaster("local[2]").setAppName("KyroTest")
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
conf.registerKryoClasses(Array(classOf[CleanedLog], classOf[String]))
conf.set("spark.rdd.compress","true")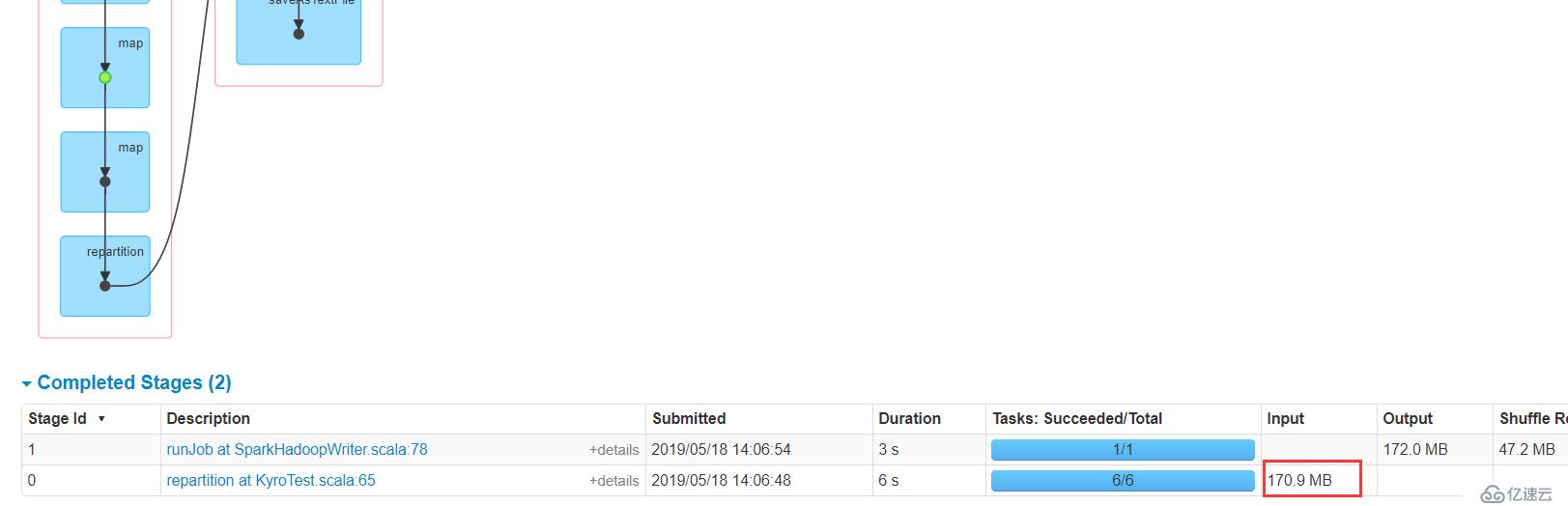
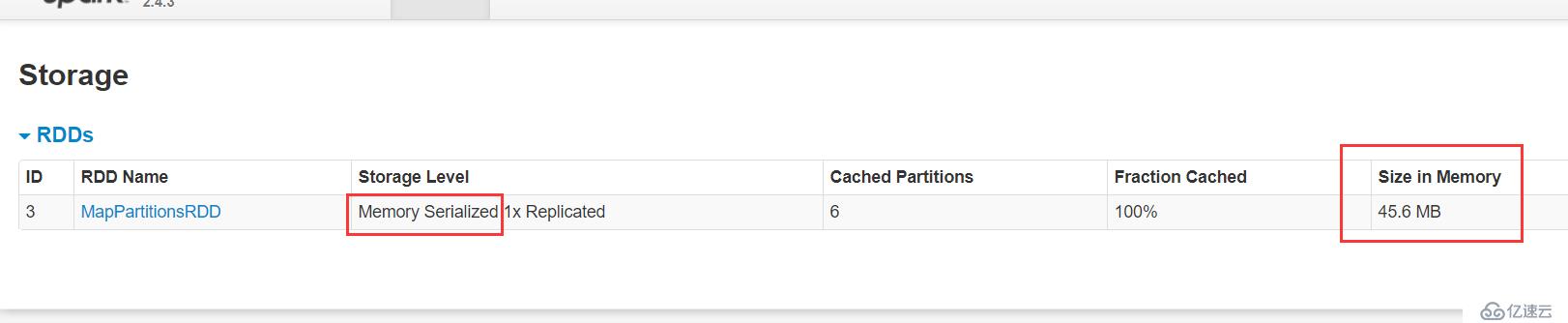
持久化的大小僅有45.6MB!!!
這個參數決定了RDD Cache的過程中,RDD數據在序列化之后是否進一步進行壓縮再儲存到內存或磁盤上。當然是為了進一步減小Cache數據的尺寸,對于Cache在磁盤上而言,絕對大小大概沒有太大關系,主要是考慮Disk的IO帶寬。而對于Cache在內存中,那主要就是考慮尺寸的影響,是否能夠Cache更多的數據,是否能減小Cache數據對GC造成的壓力等。
這兩者,前者通常不會是主要問題,尤其是在RDD Cache本身的目的就是追求速度,減少重算步驟,用IO換CPU的情況下。而后者,GC問題當然是需要考量的,數據量小,占用空間少,GC的問題大概會減輕,但是是否真的需要走到RDD Cache壓縮這一步,或許用其它方式來解決可能更加有效。
所以這個值默認是關閉的,但是如果在磁盤IO的確成為問題或者GC問題真的沒有其它更好的解決辦法的時候,可以考慮啟用RDD壓縮。
| 類型 | 輸入大小 | 持久化大小 | 時間 |
|---|---|---|---|
| MEMORY_ONLY | 170.9 MB | 908.5 MB | 14s |
| MEMORY_ONLY_SER | 170.9 MB | 204.9MB | 11s |
| kyro序列化未注冊 | 170.9 MB | 230.8MB | 9s |
| kyro序列化注冊 | 170.9 MB | 175.7MB | 9s |
| 注冊kryo序列化并開啟RDD壓縮 | 170.9 MB | 45.6MB | 9s |
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





