溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Hadoop生態系統的知識點有哪些”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Hadoop生態系統的知識點有哪些”吧!
1、Hadoop生態系統概況
Hadoop是一個能夠對大量數據進行分布式處理的軟件框架。具有可靠、高效、可伸縮的特點。
Hadoop的核心是HDFS和Mapreduce,hadoop2.0還包括YARN。
下圖為hadoop的生態系統:
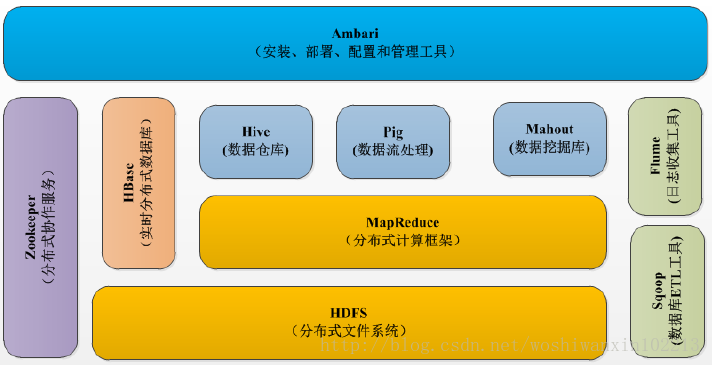
2、HDFS(Hadoop分布式文件系統)
源自于Google的GFS論文,發表于2003年10月,HDFS是GFS克隆版。
是Hadoop體系中數據存儲管理的基礎。它是一個高度容錯的系統,能檢測和應對硬件故障,用于在低成本的通用硬件上運行。HDFS簡化了文件的一致性模型,通過流式數據訪問,提供高吞吐量應用程序數據訪問功能,適合帶有大型數據集的應用程序。
Client:切分文件;訪問HDFS;與NameNode交互,獲取文件位置信息;與DataNode交互,讀取和寫入數據。
NameNode:Master節點,在hadoop1.X中只有一個,管理HDFS的名稱空間和數據塊映射信息,配置副本策略,處理客戶端請求。
DataNode:Slave節點,存儲實際的數據,匯報存儲信息給NameNode。
Secondary NameNode:輔助NameNode,分擔其工作量;定期合并fsimage和fsedits,推送給NameNode;緊急情況下,可輔助恢復NameNode,但Secondary NameNode并非NameNode的熱備。
3、Mapreduce(分布式計算框架)
源自于google的MapReduce論文,發表于2004年12月,Hadoop MapReduce是google MapReduce 克隆版。
源自于google的MapReduce論文
MapReduce是一種計算模型,用以進行大數據量的計算。其中Map對數據集上的獨立元素進行指定的操作,生成鍵-值對形式中間結果。Reduce則對中間結果中相同“鍵”的所有“值”進行規約,以得到最終結果。MapReduce這樣的功能劃分,非常適合在大量計算機組成的分布式并行環境里進行數據處理。
4、Hive(基于Hadoop的數據倉庫)
由facebook開源,最初用于解決海量結構化的日志數據統計問題。
Hive定義了一種類似SQL的查詢語言(HQL),將SQL轉化為MapReduce任務在Hadoop上執行。
5、Hbase(分布式列存數據庫)
源自Google的Bigtable論文,發表于2006年11月,HBase是Google Bigtable克隆版
HBase是一個針對結構化數據的可伸縮、高可靠、高性能、分布式和面向列的動態模式數據庫。和傳統關系數據庫不同,HBase采用了BigTable的數據模型:增強的稀疏排序映射表(Key/Value),其中,鍵由行關鍵字、列關鍵字和時間戳構成。HBase提供了對大規模數據的隨機、實時讀寫訪問,同時,HBase中保存的數據可以使用MapReduce來處理,它將數據存儲和并行計算完美地結合在一起。
數據模型:Schema-->Table-->Column Family-->Column-->RowKey-->TimeStamp-->Value
6、Zookeeper(分布式協作服務)
源自Google的Chubby論文,發表于2006年11月,Zookeeper是Chubby克隆版
解決分布式環境下的數據管理問題:統一命名,狀態同步,集群管理,配置同步等。
7、Sqoop(數據同步工具)
Sqoop是SQL-to-Hadoop的縮寫,主要用于傳統數據庫和Hadoop之前傳輸數據。
數據的導入和導出本質上是Mapreduce程序,充分利用了MR的并行化和容錯性。
8、Pig(基于Hadoop的數據流系統)
由yahoo!開源,設計動機是提供一種基于MapReduce的ad-hoc(計算在query時發生)數據分析工具
定義了一種數據流語言—Pig Latin,將腳本轉換為MapReduce任務在Hadoop上執行。
通常用于進行離線分析。
9、Mahout(數據挖掘算法庫)
Mahout起源于2008年,最初是Apache Lucent的子項目,它在極短的時間內取得了長足的發展,現在是Apache的頂級項目。
Mahout的主要目標是創建一些可擴展的機器學習領域經典算法的實現,旨在幫助開發人員更加方便快捷地創建智能應用程序。Mahout現在已經包含了聚類、分類、推薦引擎(協同過濾)和頻繁集挖掘等廣泛使用的數據挖掘方法。除了算法,Mahout還包含數據的輸入/輸出工具、與其他存儲系統(如數據庫、MongoDB 或Cassandra)集成等數據挖掘支持架構。
10、Flume(日志收集工具)
Cloudera開源的日志收集系統,具有分布式、高可靠、高容錯、易于定制和擴展的特點。
它將數據從產生、傳輸、處理并最終寫入目標的路徑的過程抽象為數據流,在具體的數據流中,數據源支持在Flume中定制數據發送方,從而支持收集各種不同協議數據。同時,Flume數據流提供對日志數據進行簡單處理的能力,如過濾、格式轉換等。此外,Flume還具有能夠將日志寫往各種數據目標(可定制)的能力。總的來說,Flume是一個可擴展、適合復雜環境的海量日志收集系統。
到此,相信大家對“Hadoop生態系統的知識點有哪些”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





