溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Hadoop的生態系統是什么”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Hadoop的生態系統是什么”吧!
hadoop生態系統,意思就是以hadoop為平臺的各種應用框架,相互兼容,組成了一個獨立的應用體系,也可以稱之為生態圈。
通過以下的圖:
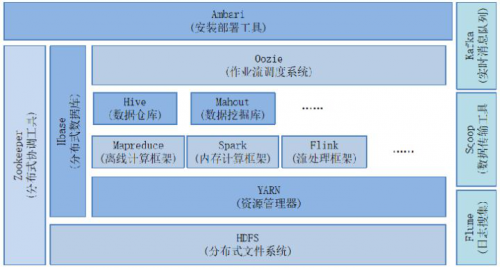
hadoop生態系統
我們可以可以總結如下常用的應用框架(圖中沒有的,我也列出了幾個):
1,HDFS(hadoop分布式文件系統)
是hadoop體系中數據存儲管理的基礎。他是一個高度容錯的系統,能檢測和應對硬件故障。
client:切分文件,訪問HDFS,與那么弄得交互,獲取文件位置信息,與DataNode交互,讀取和寫入數據。
namenode:master節點,在hadoop1.x中只有一個,管理HDFS的名稱空間和數據塊映射信息,配置副本策略,處理客戶 端請求。
DataNode:slave節點,存儲實際的數據,匯報存儲信息給namenode。
secondary namenode:輔助namenode,分擔其工作量:定期合并fsimage和fsedits,推送給namenode;緊急情況下和輔助恢復namenode,但其并非namenode的熱備。
2,mapreduce(分布式計算框架)
mapreduce是一種計算模型,用于處理大數據量的計算。其中map對應數據集上的獨立元素進行指定的操作,生成鍵-值對形式中間,reduce則對中間結果中相同的鍵的所有值進行規約,以得到最終結果。
jobtracker:master節點,只有一個,管理所有作業,任務/作業的監控,錯誤處理等,將任務分解成一系列任務,并分派給tasktracker。
tacktracker:slave節點,運行 map task和reducetask;并與jobtracker交互,匯報任務狀態。
map task:解析每條數據記錄,傳遞給用戶編寫的map()并執行,將輸出結果寫入到本地磁盤(如果為map—only作業,則直接寫入HDFS)。
reduce task:從map 它深刻地執行結果中,遠程讀取輸入數據,對數據進行排序,將數據分組傳遞給用戶編寫的reduce函數執行。
3, hive(基于hadoop的數據倉庫)
由Facebook開源,最初用于解決海量結構化的日志數據統計問題。
hive定于了一種類似sql的查詢語言(hql)將sql轉化為mapreduce任務在hadoop上執行。
4,hbase(分布式列存數據庫)
hbase是一個針對結構化數據的可伸縮,高可靠,高性能,分布式和面向列的動態模式數據庫。和傳統關系型數據庫不同,hbase采用了bigtable的數據模型:增強了稀疏排序映射表(key/value)。其中,鍵由行關鍵字,列關鍵字和時間戳構成,hbase提供了對大規模數據的隨機,實時讀寫訪問,同時,hbase中保存的數據可以使用mapreduce來處理,它將數據存儲和并行計算完美結合在一起。
5,zookeeper(分布式協作服務)
解決分布式環境下的數據管理問題:統一命名,狀態同步,集群管理,配置同步等。
6,sqoop(數據同步工具)
sqoop是sql-to-hadoop的縮寫,主要用于傳統數據庫和hadoop之間傳輸數據。數據的導入和導出本質上是mapreduce程序,充分利用了MR的并行化和容錯性。
7,pig(基于hadoop的數據流系統)
定義了一種數據流語言-pig latin,將腳本轉換為mapreduce任務在hadoop上執行。通常用于離線分析。
8,mahout(數據挖掘算法庫)
mahout的主要目標是創建一些可擴展的機器學習領域經典算法的實現,旨在幫助開發人員更加方便快捷地創建只能應用程序。mahout現在已經包含了聚類,分類,推薦引擎(協同過濾)和頻繁集挖掘等廣泛使用的數據挖掘方法。除了算法是,mahout還包含了數據的輸入/輸出工具,與其他存儲系統(如數據庫,mongoDB或Cassandra)集成等數據挖掘支持架構。
9,flume(日志收集工具)
cloudera開源的日志收集系統,具有分布式,高可靠,高容錯,易于定制和擴展的特點。他將數據從產生,傳輸,處理并寫入目標的路徑的過程抽象為數據流,在具體的數據流中,數據源支持在flume中定制數據發送方,從而支持收集各種不同協議數據。
10,資源管理器的簡單介紹(YARN和mesos)
隨著互聯網的高速發展,基于數據 密集型應用 的計算框架不斷出現,從支持離線處理的mapreduce,到支持在線處理的storm,從迭代式計算框架到 流式處理框架s4,...,在大部分互聯網公司中,這幾種框架可能都會采用,比如對于搜索引擎公司,可能的技術方法如下:網頁建索引采用mapreduce框架,自然語言處理/數據挖掘采用spark,對性能要求到的數據挖掘算法用mpi等。公司一般將所有的這些框架部署到一個公共的集群中,讓它們共享集群的資源,并對資源進行統一使用,這樣便誕生了資源統一管理與調度平臺,典型的代表是mesos和yarn。
11,其他的一些開源組件:
1)cloudrea impala:
一個開源的查詢引擎。與hive相同的元數據,SQL語法,ODBC驅動程序和用戶接口,可以直接在HDFS上提供快速,交互式SQL查詢。impala不再使用緩慢的hive+mapreduce批處理,而是通過與商用并行關系數據庫中類似的分布式查詢引擎。可以直接從HDFS或者Hbase中用select,join和統計函數查詢數據,從而大大降低延遲。
2)spark:
spark是個開源的數據 分析集群計算框架,最初由加州大學伯克利分校AMPLab,建立于HDFS之上。spark與hadoop一樣,用于構建大規模,延遲低的數據分析應用。spark采用Scala語言實現,使用Scala作為應用框架。
spark采用基于內存的分布式數據集,優化了迭代式的工作負載以及交互式查詢。
與hadoop不同的是,spark與Scala緊密集成,Scala象管理本地collective對象那樣管理分布式數據集。spark支持分布式數據集上的迭代式任務,實際上可以在hadoop文件系統上與hadoop一起運行(通過YARN,MESOS等實現)。
3)storm
storm是一個分布式的,容錯的計算系統,storm屬于流處理平臺,多用于實時計算并更新數據庫。storm也可被用于“連續計算”,對數據流做連續查詢,在計算時將結果一流的形式輸出給用戶。他還可被用于“分布式RPC”,以并行的方式運行昂貴的運算。
4)kafka
kafka是由Apache軟件基金會開發的一個開源流處理平臺,由Scala和Java編寫。Kafka是一種高吞吐量的分布式發布訂閱消息系統,它可以處理消費者規模的網站中的所有動作流數據。 這種動作(網頁瀏覽,搜索和其他用戶的行動)是在現代網絡上的許多社會功能的一個關鍵因素。 這些數據通常是由于吞吐量的要求而通過處理日志和日志聚合來解決。 對于像Hadoop的一樣的日志數據和離線分析系統,但又要求實時處理的限制,這是一個可行的解決方案。Kafka的目的是通過Hadoop的并行加載機制來統一線上和離線的消息處理,也是為了通過集群來提供實時的消息
感謝各位的閱讀,以上就是“Hadoop的生態系統是什么”的內容了,經過本文的學習后,相信大家對Hadoop的生態系統是什么這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





