溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Federation設計動機與基本原理是什么,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
HDFS Federation是Hadoop最新發布版本Hadoop-0.23.0中為解決HDFS單點故障而提出的namenode水平擴展方案。該方案允許HDFS創建多個namespace以提高集群的擴展性和隔離性。下面主要介紹了HDFS Federation的設計動機和基本原理。
當前HDFS包含兩層結構:
(1) Namespace 管理目錄,文件和數據塊。它支持常見的文件系統操作,如創建文件,修改文件,刪除文件等。
(2) Block Storage有兩部分組成:
Block Management維護集群中datanode的基本關系,它支持數據塊相關的操作,如:創建數據塊,刪除數據塊等,同時,它也會管理副本的復制和存放。
Physical Storage存儲實際的數據塊并提供針對數據塊的讀寫服務。
【Block Storage的這兩部分分別在namenode和datanode上實現,所以該模塊由namenode和datanode分工完成】
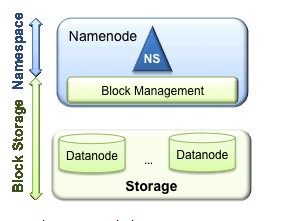
當前HDFS架構只允許整個集群中存在一個namespace,而該namespace被僅有的一個namenode管理。這個架構使得HDFS非常容易實現,但是,它(見上圖)在具體實現過程中會出現一些模糊點,進而導致了很多局限性(下面將要詳細說明),當然這些局限性只有在擁有大集群的公司,像baidu,騰訊等出現。
當前namenode中的namespace和block management的結合使得這兩層架構耦合在一起,難以讓其他可能namenode實現方案直接使用block storage。
HDFS的底層存儲是可以水平擴展的(解釋:底層存儲指的是datanode,當集群存儲空間不夠時,可簡單的添加機器已進行水平擴展),但namespace不可以。當前的namespace只能存放在單個namenode上,而namenode在內存中存儲了整個分布式文件系統中的元數據信息,這限制了集群中數據塊,文件和目錄的數目。
文件操作的性能制約于單個namenode的吞吐量,單個namenode當前僅支持約60K的task,而下一代Apache MapReduce將支持多余100K的并發任務,這隱含著要支持多個namenode。
現在大部分公司的集群都是共享的,每天有來自不同group的不同用戶提交作業。單個namenode難以提供隔離性,即:某個用戶提交的負載很大的job會減慢其他用戶的job,單一的namenode難以像HBase按照應用類別將不同作業分派到不同namenode上。
采用Federation的最主要原因是簡單,Federation能夠快速的解決了大部分單Namenode的問題。
Federation 整個核心設計實現大概用了4個月。大部分改變是在Datanode、Config和Tools,而Namenode本身的改動非常少,這樣 Namenode原先的魯棒性不會受到影響。這使得該方案與之前的HDFS版本兼容。
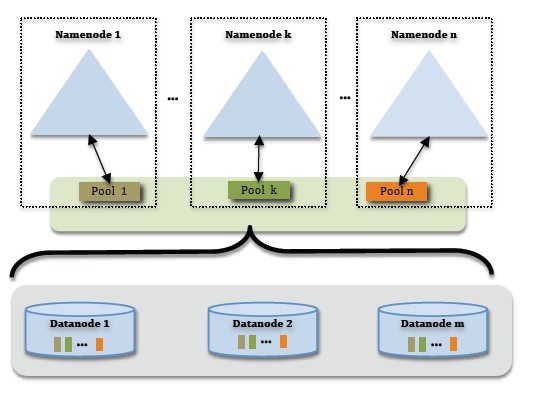
為了水平擴展namenode,federation使用了多個獨立的namenode/namespace。這些namenode之間是聯合的,也就是說,他們之間相互獨立且不需要互相協調,各自分工,管理自己的區域。分布式的datanode被用作通用的數據塊存儲存儲設備。每個datanode要向集群中所有的namenode注冊,且周期性地向所有namenode發送心跳和塊報告,并執行來自所有namenode的命令。
一個block pool由屬于同一個namespace的數據塊組成,每個datanode可能會存儲集群中所有block pool的數據塊。
每個block pool內部自治,也就是說各自管理各自的block,不會與其他block pool交流。一個namenode掛掉了,不會影響其他namenode。
某個namenode上的namespace和它對應的block pool一起被稱為namespace volume。它是管理的基本單位。當一個namenode/nodespace被刪除后,其所有datanode上對應的block pool也會被刪除。當集群升級時,每個namespace volume作為一個基本單元進行升級。
Federation中存在多個命名空間,如何劃分和管理這些命名空間非常關鍵。在Federation中并采用“文件名hash”的方法,因為該方法的locality非常差,比如:查看某個目錄下面的文件,如果采用文件名hash的方法存放文件,則這些文件可能被放到不同namespace中,HDFS需要訪問所有namespace,代價過大。為了方便管理多個命名空間,HDFS Federation采用了經典的Client Side Mount Table。
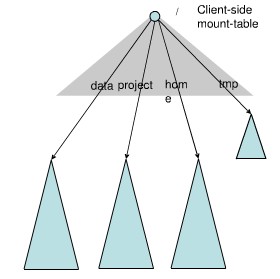
如上圖所示,下面四個深色三角形代表一個獨立的命名空間,上方淺色的三角形代表從客戶角度去訪問的子命名空間。各個深色的命名空間Mount到淺色的表中,客戶可以訪問不同的掛載點來訪問不同的命名空間,這就如同在Linux系統中訪問不同掛載點一樣。這就是HDFS Federation中命名空間管理的基本原理:將各個命名空間掛載到全局mount-table中,就可以做將數據到全局共享;同樣的命名空間掛載到個人的mount-table中,這就成為應用程序可見的命名空間視圖。
支持多個namenode水平擴展整個文件系統的namespace。可按照應用程序的用戶和種類分離namespace volume,進而增強了隔離性。
Block Pool抽象層為HDFS的架構開啟了創新之門。分離block storage layer使得:
<1> 新的文件系統(non-HDFS)可以在block storage上構建
<2> 新的應用程序(如HBase)可以直接使用block storage層
<3> 分離的block storage層為將來完全分布式namespace打下基礎
Federation 整個核心設計實現大概用了4個月。大部分改變是在Datanode、Config和Tools中,而Namenode本身的改動非常少,這樣 Namenode原先的魯棒性不會受到影響。雖然這種實現的擴展性比起真正的分布式的Namenode要小些,但是可以迅速滿足需求,另外Federation具有良好的向后兼容性,已有的單Namenode的部署配置不需要任何改變就可以繼續工作
HDFS Federation并沒有完全解決單點故障問題。雖然namenode/namespace存在多個,但是從單個namenode/namespace看,仍然存在單點故障:如果某個namenode掛掉了,其管理的相應的文件便不可以訪問。Federation中每個namenode仍然像之前HDFS上實現一樣,配有一個secondary namenode,以便主namenode掛掉一下,用于還原元數據信息。
HDFS Federation采用了Client Side Mount Table分攤文件和負載,該方法更多的需要人工介入已達到理想的負載均衡。
上述內容就是Federation設計動機與基本原理是什么,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





