溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了HDFS Federation怎么用,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
我們先回顧一下HDFS功能。HDFS實際上具有兩個功能:命名空間管理(Namespace management)和塊/存儲管理服務(block/storage management)。
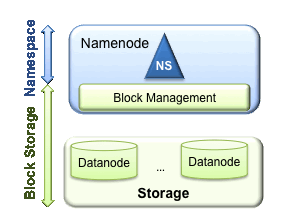
HDFS的命名空間包含目錄、文件和塊。命名空間管理:是指命名空間支持對HDFS中的目錄、文件和塊做類似文件系統的創建、修改、刪除、列表文件和目錄等基本操作。
在塊存儲服務中包含兩部分工作:塊管理和物理存儲。這是一個更通用的存儲服務。其他的應用可以直接建立在Block Storage上,如HBase,Foreign Namespaces等。
A) 處理Data Node向Name Node注冊的請求,處理datanode的成員關系,處理來自Data Node周期性的心跳。
B) 處理來自塊的報告信息,維護塊的位置信息。
C) 處理與塊相關的操作:塊的創建、刪除、修改及獲取塊信息。
D) 管理副本放置(replica placement)和塊的復制及多余塊的刪除。
所謂物理存儲就是:Data Node把塊存儲到本地文件系統中,對本地文件系統的讀、寫。
在當前的HDFS架構中(Hadoop v0.23之前),在整個HDFS集群中只有一個命名空間,并且只有單獨的一個Name Node,這個Name Node負責對這單獨的一個命名空間進行管理。這也正是單點失效(Single Point Failure)的隱患所在。本文所講的HDFS Federation就是針對當前HDFS架構上的缺陷所做的改進,簡單說HDFS Federation就是使得HDFS支持多個命名空間,并且允許在HDFS中同時存在多個Name Node。
簡單回顧一下目前HDFS的架構,如下圖所示。在整個HDFS集群中只有一個Namenode,還有一個Backup Namenode。Namenode會實時將變化的HDFS的信息同步給Backup Namenode。Backup Namenode顧名思義是用來做Namenode的備份的。Namenode中命名空間以層次結構組織中存儲著文件名和BlockID的對應關系、 BlockID和具體Block位置的對應關系。這個單獨的Namenode管理著數個Datanode,Block分布在各個Datanode中,每個 Datanode會周期性的向此Namenode發送心跳消息,報告自己所在Datanode的使用狀態。Block是用來存儲數據的最小單元,通常一個 文件會存儲在一個或者多個Block中,默認Block大小為64MB。
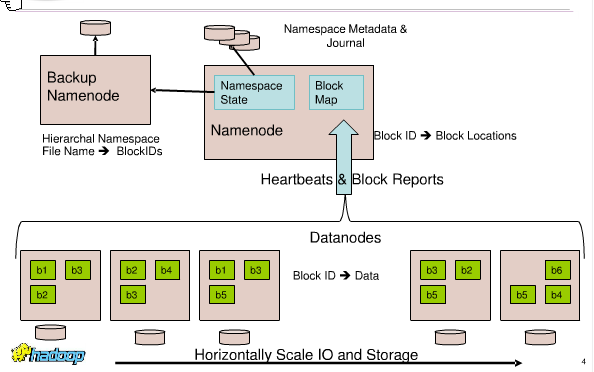
由于Namenode在內存中存儲所有的元數據(metadata),因此單個Namenode所能存儲的對象(文件+塊)數目受到 Namenode所在JVM的heap size的限制。50G的heap能夠存儲20億(200 million)個對象,這20億個對象支持4000個datanode,12PB的存儲(假設文件平均大小為40MB)。
隨著數據的飛速增長,存儲的需求也隨之增長。單個datanode從4T增長到36T,集群的尺寸增長到8000個datanode。存儲的需求從12PB增長到大于100PB。
由于是單個Namenode的HDFS架構,因此整個HDFS文件系統的吞吐量受限于單個Namenode的吞吐量。毫無疑問,這將成為下一代MapReduce的瓶頸。
由于HDFS僅有一個Namenode,無法隔離各個程序,因此HDFS上的一個實驗程序就很有可能影響整個HDFS上運行的程序。那么在 HDFS Federation中,可以用不同的Namespace來隔離不同的用戶應用程序,使得不同Namespace Volume中的程序相互不影響。
在只有一個Namenode的HDFS中,此Namenode的宕機無疑會導致整個集群不可用。
當前在Namenode中的Namespace和Block Management組合的緊密耦合關系會導致如果想要實現另外一套Namenode方案比較困難,而且也限制了其他想要直接使用塊存儲的應用。
這樣縱向擴展帶來的第一個問題就是啟動問題,啟動花費的時間太長。當前具有50GB Heap Namenode的HDFS啟動一次大概需要30分鐘到2小時,那512GB的需要多久?
第二個潛在的問題就是Namenode在Full GC時,如果發生錯誤將會導致整個集群宕機。
第三個問題是對大JVM Heap進行調試比較困難。優化Namenode的內存使用性價比比較低。
因此Federation(聯盟)是未來可選的方案之一。在Federation架構中可以無縫的支持目前單Namenode架構中的配置。
HDFS Federation使用了多個獨立的Namenode/namespace來使得HDFS的命名服務能夠水平擴展。在HDFS Federation中的Namenode之間是聯盟關系,他們之間相互獨立且不需要相互協調。HDFS Federation中的Namenode提供了提供了命名空間和塊管理功能。HDFS Federation中的datanode被所有的Namenode用作公共存儲塊的地方。每一個datanode都會向所在集群中所有的 Namenode注冊,并且會周期性的發送心跳和塊信息報告,同時處理來自Namenode的指令。
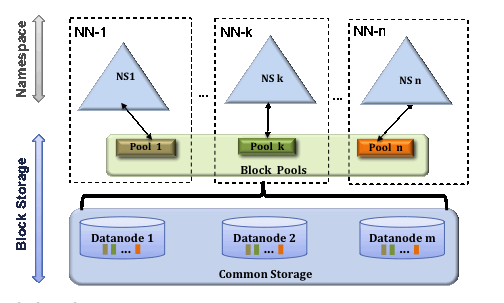
當前HDFS只有一個命名空間(Namespace),它使用全部的塊。而Federation HDFS中有多個獨立的命名空間(Namespace),并且每一個命名空間使用一個塊池(block pool)。
當前HDFS中只有一組塊。而Federation HDFS中有多組獨立的塊。塊池(block pool)就是屬于同一個命名空間的一組塊。
當前HDFS由一個Namenode和一組datanode組成。而Federation HDFS由多個Namenode和一組datanode,每一個datanode會為多個塊池(block pool)存儲塊。
所謂Block pool(塊池)就是屬于單個命名空間的一組block(塊)。每一個datanode為所有的block pool存儲塊。Datanode是一個物理概念,而block pool是一個重新將block劃分的邏輯概念。同一個datanode中可以存著屬于多個block pool的多個塊。Block pool允許一個命名空間在不通知其他命名空間的情況下為一個新的block創建Block ID。同時,一個Namenode失效不會影響其下的datanode為其他Namenode的服務。
當datanode與Namenode建立聯系并開始會話后自動建立Block pool。每個block都有一個唯一的標識,這個標識我們稱之為擴展的塊ID(Extended Block ID)= BlockID+BlockID。這個擴展的塊ID在HDFS集群之間都是唯一的,這為以后集群歸并創造了條件。
Datanode中的數據結構都通過塊池ID(BlockPoolID)索引,即datanode中的BlockMap,storage等都通過BPID索引。
在HDFS中,所有的更新、回滾都是以Namenode和BlockPool為單元發生的。即同一HDFS Federation中不同的Namenode/BlockPool之間沒有什么關系。
Hadoop V0.23版本中Block Pool的管理功能依然放在了Namenode中,將來的版本中會將Block Pool的管理功能移動的新的功能節點中。
在datanode中,對應于每個Namnode都有一條相應的線程。每個datanode會去每一個Namenode注冊,并且周期性的給所有的 Namenode發送心跳及datanode的使用報告。Datanode還會給Namenode發送其所在的block pool的block report(塊報告)。由于有多個Namenode同時存在,因此任何一個Namenode都可以隨時動態加入、刪除和更新。
提供了工具,對于Namenode的初始化和退役的監控和管理。
允許在datanode級別或者block pool級別的負載均衡。
Datanode的后臺守護進程,為Federation所做的磁盤和目錄掃描。
提供了顯示Namenode的Block pool的使用狀態的Web UI。
還提供了對全部集群存儲使用狀態的UI展示。
在Web UI中列出了所有的Namenode及其細節,如Namenode-BlockPoolID和存儲的使用狀態,失去聯系的、活的和死的塊信息。還有前往各個Namenode Web UI的鏈接。
Datanode退役狀態的展示。
在一個集群中需要唯一的命名空間還是多個命名空間,核心問題命名空間中數據的共享和訪問的問題。使用全局唯一的命名空間是解決數據共享和訪問的一種方法。在多命名空間下,我們還可以使用Client Side Mount Table方式做到數據共享和訪問。

如上圖所示,每個深色三角形代表一個獨立的命名空間,上方淺色的三角形代表從客戶角度去訪問下方的子命名空間。各個深色的命名空間Mount到淺色 的表中,客戶可以訪問不同的掛載點來訪問不同的命名空間,這就如同在Linux系統中訪問不同掛載點一樣。這就是HDFS Federation中命名空間管理的基本原理:將各個命名空間掛載到全局mount-table中,就可以做將數據到全局共享;同樣的命名空間掛載到個人的mount-table中,這就成為應用程序可見的命名空間視圖。
一個Namespace和它的Block Pool合在一起稱作Namespace Volume。Namespace Volume是一個獨立完整的管理單元。當一個Namenode/Namespace被刪除,與之相對應的Block Pool也也被刪除。在升級時每一個Namespace Volume也會整體作為一個單元。
在HDFS Federation中添加了Cluster ID用來區分集群中的每個節點。當格式化一個Namenode時,這個ClusterID會自動生成或者手動提供。在格式化同一集群中其他Namenode時會用到這個ClusterID。
這種兼容性可以使得已有的Namenode配置不需要任何改變繼續工作。
感謝你能夠認真閱讀完這篇文章,希望小編分享的“HDFS Federation怎么用”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





