溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關使用Eclipse運行Hadoop 2.x MapReduce程序的常見問題有哪些,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
1、 當我們編寫好MapReduce程序,點擊Run on Hadoop的時候,Eclipse控制臺輸出如下內容:

這個信息告訴我們沒有找到log4j.properties文件。如果沒有這個文件,程序運行出錯的時候,就沒有打印日志,因此我們會很難調試。
解決方法:復制$HADOOP_HOME/etc/hadoop/目錄下的log4j.properties文件到MapReduce項目 src文件夾下。
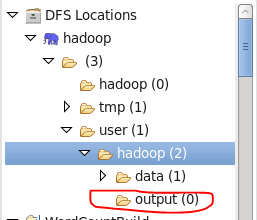
2、當執行MapReduce程序的時候,Eclipse可能會報告堆益處的錯誤。 此時,MapReduce程序執行的out目錄已經被創建,但是此時目錄為空,再重新運行程序之前我們需要刪除這個輸出目錄。如下圖所示:
分析:首先我們可以輸入命令(java -client -XX:+UnlockDiagnosticVMOptions -XX:+PrintFlagsFinal -version | grep -i heapsize),來查看當前JDK支持的最大堆。然后在此基礎上增加堆大小。
解決方案:在當前運行程序的運行配置中設置VM arguments參數,如下圖所示:

Hadoop是使用Java語言開發的,但是有一些需求和操作并不適合使用java,所以就引入了本地庫(Native Libraries)的概念,通過本地庫,Hadoop可以更加高效地執行某一些操作。
目前在Hadoop中,本地庫應用在文件的壓縮上面:
zlib
gzip
在使用這兩種壓縮方式的時候,Hadoop默認會從$HADOOP_HOME/lib/native/Linux-*目錄中加載本地庫。
如果加載成功,輸出為:
DEBUG util.NativeCodeLoader - Trying to load the custom-built native-hadoop library...
INFO util.NativeCodeLoader - Loaded the native-hadoop library
如果加載失敗,輸出為:
INFO util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
在Hadoop的配置文件core-site.xml中可以設置是否使用本地庫:
<property>
<name>hadoop.native.lib</name>
<value>true</value>
<description>Should native hadoop libraries, if present, be used.</description>
</property>
Hadoop默認的配置為啟用本地庫。
另外,可以在環境變量中設置使用本地庫的位置:
export JAVA_LIBRARY_PATH=/path/to/hadoop-native-libs
有的時候也會發現Hadoop自帶的本地庫無法使用,這種情況下就需要自己去編譯本地庫了。在$HADOOP_HOME目錄下,使用如下命令即可:
ant compile-native
編譯完成后,可以在$HADOOP_HOME/build/native目錄下找到相應的文件,然后指定文件的路徑或者移動編譯好的文件到默認目錄下即可。
上述就是小編為大家分享的使用Eclipse運行Hadoop 2.x MapReduce程序的常見問題有哪些了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





