溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關Hadoop1.x和Hadoop2.x有什么區別的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
Hadoop 2.0 產生背景
Hadoop 1.0 中HDFS和MapReduce在高可用、擴展性等方面存在問題
JobTracker訪問壓力大,影響系統擴展性;
難以支持除MapReduce之外的計算框架,比如Spark、Storm等。
NameNode單點故障,難以應用于在線場景;
NameNode壓力過大,且內存受限,影響系統擴展性。
HDFS 存在的問題
MapReduce存在的問題

HDFS 2.x
解決HDFS 1.0 單點故障和內存受限問題。
解決單點故障
參考 HDFS High Availability Using the Quorum Journal Manager
參考 ZooKeeper Getting Started Guide
HDFS HA:通過準備NameNode解決;
如果住NameNode發生故障,則切換到備NameNode。
解決內存受限問題
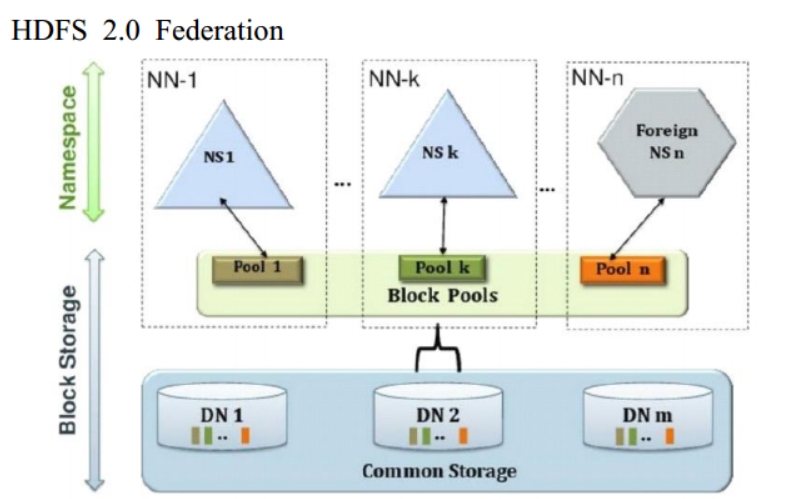
HDFS Federation (聯邦)
水平擴展,支持多個NameNode;
每個NameNode分管一部分目錄;
所有NameNode共享所有DataNode存儲的資源。
2.x僅是架構上發生了改變,使用方式不變
對HDFS使用者透明
HDFS 1.x 中的命令和API仍可以使用
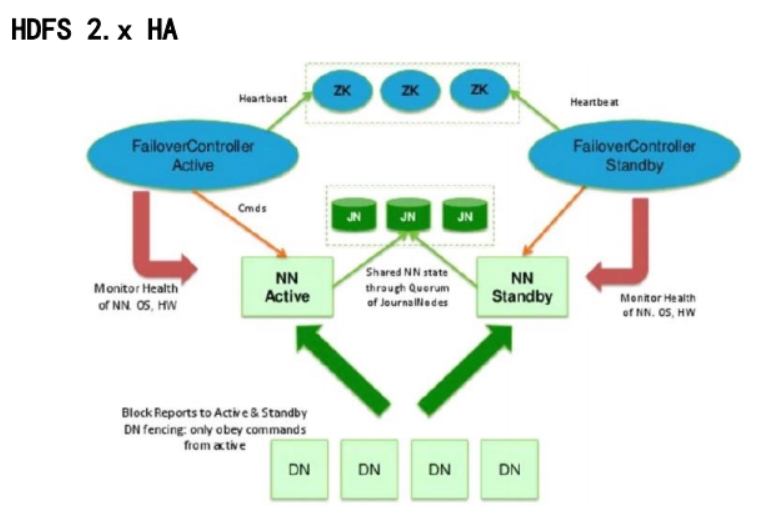
主備NameNode
解決單點故障
主NameNode對外提供服務,備NameNode同步主NameNode元數據,以待切換;
所有DataNode同時向兩個NameNode匯報數據塊信息。
兩種切換選擇
手動切換:通過命令實現準備之間的切換,可以用HDFS升級等場合;(X)
自動切換:基于Zookeeper實現。 (√)
基于Zookeeper自動切換方案
Zookeeper Failove Controller:監控Namenode健康狀態,并向Zookeeper 注冊 Namenode
NameNode掛掉后,ZKFC為NameNode競爭鎖,獲得ZKFC鎖的NameNode變為active
HDFS 2.x Federation
通過多個namenode/namespace把元數據的存儲和管理分散到多個節點中,使namenode/namespace可以通過增加機器來進行水平擴張。
能把單個namenode的負載分散到多個節點中,在HDFS數據規模較大的時候也不會降低HDFS的性能。可以通過多個namsespace來隔離不同類型的應用,把不同類型應用的HDFS的存儲和管理分派到不同的namenode中。
YARN
YARN - Yet Another Resource Negotiator;
Hadoop 2.0 新引入的資源管理系統,直接從MRv1演化而來;
核心思想:將MRv1中JobTracker的資源管理和任務調度兩個功能分開,分別由ResourceManager和ApplicationMaster進程實現; -ResourceManager:負責整個集群的資源管理和調度;整個集群只有一個;
ApplicationMaster:負責應用程序相關的事務,比如任務調度、任務監控和容錯等;一個應用程序對應一個ApplicationMaster;
YARN的引入,是的多個計算框架可運行在一個集群中
每個應用程序對應一個ApplicationMaster;
目前多個計算框架可以運行在YARN上,比如MapReduce、Spark、Storm等。
MapReduce On YARN
運行在YARN之上的MapReduce稱為MRv2;
將MapReduce作業直接運行在YARN上,而不是運行在由JobTracker和TaskTracker構建的MRv1系統中;
在Hadoop2.0中并不存在JobTracker和TaskTracker;
MRv2的模塊基本功能:
YARN:負責資源管理和調度;
MRAppMaster:負責一個應用程序/作業的任務切分、任務調度、任務監控和容錯;
Map/Reduce Task:任務驅動引擎,與MRv1一致;
每個應用程序/作業(MapReduce作業)對應一個MRAppMaster
單個應用程序/作業運行失敗,不會影響其他應用程序/作業,由YARN重新啟動;
任務失敗后,MRAppMaster重新申請資源;
負責應用程序/作業相關的事務,包括將從YARN分配得到的資源二次分配給內部的任務、任務切分、任務健康和容錯等;
感謝各位的閱讀!關于“Hadoop1.x和Hadoop2.x有什么區別”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





