溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
大數據處理架構Hadoop
1.概述
1.1 Hadoop 簡介
hadoop是apache軟件基金會旗下的一個開源分布式計算平臺,為用戶提供系統底層細節透明的分布式基礎架構。hadoop基于java語言
開發。跨平臺性能好,可以部署在廉價的計算機集群中。hadoop核心是HDFS(分布式文件系統,解決了海量數據的存儲)和mapreduce
(解決了海量數據的處理)。hadoop被公認為行業大數據標準開源軟件,在分布式環境下提供了海量數據段 處理能力。
2008年4月,hadoop打破當時的世界記錄成為最快排序1TB數據的系統,他采用901個節點構成的集群運算,排序時間只用209S。
1.2 Hadoop的發展簡史
hadoop最初由apache Lucene項目的創始人Doug Cutting 開發的文本索引庫。2002年的時候,Nutch項目(Lucene項目一部分)遇到
了該框架無法擴展到擁有數十億網頁的網絡。2003年的時候Google 發布了分布式文件系統GFS的論文,2004年Nutch項目模仿GFS開發了
NDFS(HDFS前身)。2004年,谷歌公司有發布了MapReduce分布式編程思想的論文。2005年Nutch 項目開源了谷歌的MapReduce。
至此。hadoop的兩個核心HDFS和MapReduce ,受谷歌論文的影響,成就了hadoop在海量數據處理靈域的頭羊領袖地位。2008年一月,
Hadoop正式成為apache頂級的項目。
1.3 hadoop 特性
高可用性 : 采用冗余存儲方式
高效性:采用分布式存儲和分布式處理,搞笑的處理PB級數據
高可擴展性:hadoop設計目的:高效穩定運行在廉價的計算機集群上。
高容錯性:采用冗余數據存儲方式。
低成本:采用廉價的計算機集群。
運行在linux平臺。
支持多種編程語言。
1.4 hadoop的版本
apache hadoop版本分為兩代,第一代hadoop包含0.20x ,0.21.x和0.22.x三個版本。其中,0.20x最后演變成1.0.x,成為穩定版。
0.21.x和0.22.x增加了HDFS HA(高可用)等重要特性。第二代hadoop包含0.23.x和2.x兩個版本。
第二代hadoop比第一代hadoop做了較大的改進:主要是拆分了MapReduce的職能,減輕了系統負載。增加了YARN資源調度框架,
mapreduce 運行在YARN框架(負責系統資源的調度的基礎上,不在負責系統資源的調度,只專心于分布式計算。做為hadoop另一個核心
的HDFS也增加了 federation 和HA(高可用和熱備份)(HDFS中的namenode需要高可用)
apache的各個版本的比較:
除了免費開源apache hadoop版本提供標準,還有一些商業化公司陸續退出hadoop版本。
2014年進入上海的 cloudera 與apache hadoop功能同步部分開源,具有自主研發產品,impala、navigator
hortonwork 與apache 功能同步也完全開源(是apache hadoop平臺最大的貢獻者。產品:Tez構架,下一代hadoop查詢處理框架)
MapR 在apache hadoop基礎上修改優化了許多,也形成了自己的 產品。
國產的有 星環。核心組件與apache 同步,底層較多,完全封閉閉源,也又自己的hadoop產品 Inceptor 、Hyperbase.
1.41 hadoop在企業的應用構架分為3層:數據源的流向依次是數據來源 ==》大數據層==》訪問層
在大數據層以HDFS分布式存儲為基礎;分為三部分。分別為訪問層的3個功能即:數據分析、數據實時查詢、數據挖掘提供運算。
其中大數據層的: mapreduce (hive, pig) 提供了離線數據分析
Hbase(solr redis) 提供了數據的實時查詢
Mahout BI分析 完成 數據挖掘
1.5 hadoop生態系統
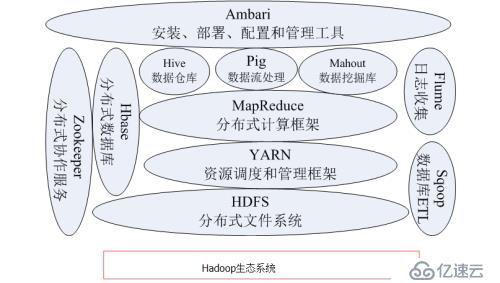
1.51 HDFS
分布式文件系統(Hadoop Distributed File System HDFS)是Hadoop項目的核心。針對谷歌文件系統GFS的開源。
具有處理超大數據、流式處理運行在廉價服務器等優點。在設計之初,吧硬件故障作為常態考慮,保證在部分硬件發生故障的時候
仍能保障整體的可用性和可靠性。此外,HDFS放寬了POSIX(可移植操作系統接口)實現了流的形式訪問系統數據。提高系統的
吞吐率。
1.52 HBase
針對谷歌BigTable的開源實現。具有強大的非結構化數據存儲能力。采用HDFS作為底層數據存儲,與傳統數據庫基于列的存儲
方式不同,HBase是基于行的存儲。可橫向擴展。是一個提供高可靠性、高性能、可伸縮、實時讀寫、分布式的列式數據庫。
1.53 MapReduce
針對谷歌的MapReduce的開源實現。是一種編程模型。高度抽象到兩個函數上 Map 和 Reduce 。在不了解底層細節情況下開發
并行應用程序,運行在廉價計算機集群,完成海量數據(大于1T)處理核心思想是:將數據分成若干獨立的數據塊。分發給一個節點
管理下的各個分界點來共同并行完成,最后最后整合各個節點中間結果得到最終結果。
1.54 Hive
基于hadoop的數據倉庫工具。針對hadoop文件中的數據集進行數據整理、特殊查詢和分析存儲。使用類SQL語言的Hive-QL
快速實現簡單MapReduce統計。
1.55 Pig
簡化了Hadoop常見的工作任務。為hadoop程序提供一種更加接近SQL的接口。在大型數據集中搜索滿足某個給定搜索條件的記
錄時,Pig 只需要編寫一個簡單的腳本在集群中自動并行處理與分發,而MapReduce需要編寫一個單獨程序。
1.56 Mahout
提供可擴展的機器學習領域經典算法。用于數據挖掘。
1.57 Zookeeper
針對谷歌Chubby的一個開源實現、是高效和可靠的協同工作系統,用于構建分布式應用,減輕分布式應用程序所承擔的協調任務。
1.58 Flume
是 Cloudera提供的一個高可用的,高可靠的、分布式海量日志采集、聚合和傳輸的系統。支持日志系統中定制各類數據發送方,
用于收集數據;同時,Flume 提供對數據進行簡單處理并寫到各種數據接受方的能力。
1.59 Sqoop
SQL-to-Hadoop的縮寫。用于Hadoop和關系數據庫間交換數據,通過Sqoop可以將數據從mysql 、Oracle、postgresql等關系
型數據中導入Hadoop(可以導入HDFS、HBase和Hive)也可以將數據從hadoop導出到關系數據庫。是數據遷移方便
1.510 Ambari
Web工具。支持Apache Hadoop 集群的安裝、部署、配置和管理
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





