溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何讓Python爬取招聘網站數據并實現可視化交互大屏,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
隨著科技的飛速發展,數據呈現爆發式的增長,任何人都擺脫不了與數據打交道,社會對于“數據”方面的人才需求也在不斷增大。因此了解當下企業究竟需要招聘什么樣的人才?需要什么樣的技能?不管是對于在校生,還是對于求職者來說,都顯得很有必要。
本文基于這個問題,針對51job招聘網站,爬取了全國范圍內大數據、數據分析、數據挖掘、機器學習、人工智能等相關崗位的招聘信息。分析比較了不同崗位的薪資、學歷要求;分析比較了不同區域、行業對相關人才的需求情況;分析比較了不同崗位的知識、技能要求等。
做完以后的項目效果如下:
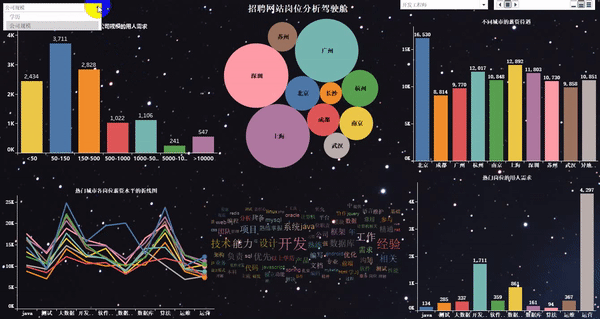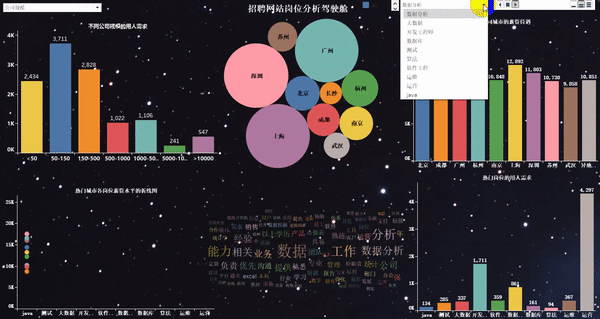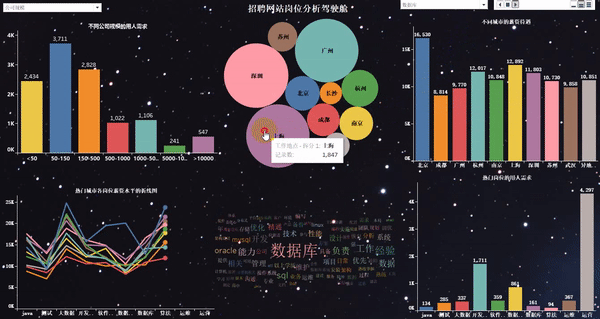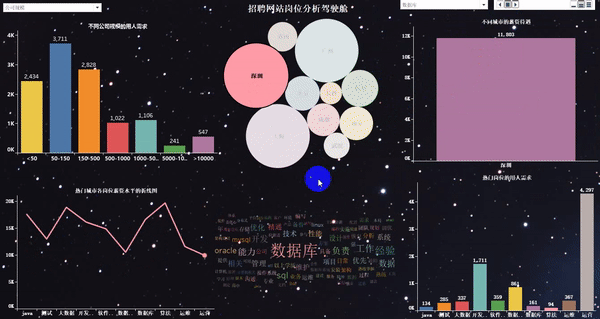
爬取崗位:大數據、數據分析、機器學習、人工智能等相關崗位;
爬取字段:公司名、崗位名、工作地址、薪資、發布時間、工作描述、公司類型、員工人數、所屬行業;
說明:基于51job招聘網站,我們搜索全國對于“數據”崗位的需求,大概有2000頁。我們爬取的字段,既有一級頁面的相關信息,還有二級頁面的部分信息;
爬取思路:先針對某一頁數據的一級頁面做一個解析,然后再進行二級頁面做一個解析,最后再進行翻頁操作;
使用工具:Python+requests+lxml+pandas+time
網站解析方式:Xpath
1、導入相關庫
import requests
import pandas as pd
from pprint import pprint
from lxml import etree
import time
import warnings
warnings.filterwarnings("ignore")2、關于翻頁的說明
# 第一頁的特點 https://search.51job.com/list/000000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE,2,1.html? # 第二頁的特點 https://search.51job.com/list/000000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE,2,2.html? # 第三頁的特點 https://search.51job.com/list/000000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE,2,3.html?
注意:通過對于頁面的觀察,可以看出,就一個地方的數字變化了,因此只需要做字符串拼接,然后循環爬取即可。
3、完整的爬取代碼
import requests
import pandas as pd
from pprint import pprint
from lxml import etree
import time
import warnings
warnings.filterwarnings("ignore")
for i in range(1,1501):
print("正在爬取第">這里可以看到,我們爬取了1000多頁的數據做最終的分析。因此每爬取一頁的數據,做一次數據存儲,避免最終一次性存儲導致失敗。同時根據自己的測試,有一些頁數進行數據存儲,會導致失敗,為了不影響后面代碼的執行,我們使用了“try-except”異常處理。
在一級頁面中,我們爬取了“崗位名稱”,“公司名稱”,“工作地點”,“工資”,“發布日期”,“二級網址的url”這幾個字段。
在二級頁面中,我們爬取了“經驗、學歷信息”,“崗位描述”,“公司類型”,“公司規模”,“所屬行業”這幾個字段。
從爬取到的數據中截取部分做了一個展示,可以看出數據很亂。雜亂的數據并不利于我們的分析,因此需要根據研究的目標做一個數據預處理,得到我們最終可以用來做可視化展示的數據。
1、相關庫的導入及數據的讀取
df = pd.read_csv(r"G:\8泰迪\python_project\51_job\job_info1.csv",engine="python",header=None) # 為數據框指定行索引 df.index = range(len(df)) # 為數據框指定列索引 df.columns = ["崗位名","公司名","工作地點","工資","發布日期","經驗與學歷","公司類型","公司規模","行業","工作描述"]
2、數據去重
我們認為一個公司的公司名和和發布的崗位名一致,就看作是重復值。因此,使用drop_duplicates(subset=[])函數,基于“崗位名”和“公司名”做一個重復值的剔除。
# 去重之前的記錄數
print("去重之前的記錄數",df.shape)
# 記錄去重
df.drop_duplicates(subset=["公司名","崗位名"],inplace=True)
# 去重之后的記錄數
print("去重之后的記錄數",df.shape)3、崗位名字段的處理
① 崗位名字段的探索
df["崗位名"].value_counts() df["崗位名"] = df["崗位名"].apply(lambda x:x.lower())
說明:首先我們對每個崗位出現的頻次做一個統計,可以看出“崗位名字段”太雜亂,不便于我們做統計分析。接著我們將崗位名中的大寫英文字母統一轉換為小寫字母,也就是說“AI”和“Ai”屬于同一個東西。
② 構造想要分析的目標崗位,做一個數據篩選
job_list = ['數據分析', "數據統計","數據專員",'數據挖掘', '算法',
'大數據','開發工程師', '運營', '軟件工程', '前端開發',
'深度學習', 'ai', '數據庫', '數據庫', '數據產品',
'客服', 'java', '.net', 'andrio', '人工智能', 'c++',
'數據管理',"測試","運維"]
job_list = np.array(job_list)
def rename(x=None,job_list=job_list):
index = [i in x for i in job_list]
if sum(index) > 0:
return job_list[index][0]
else:
return x
job_info["崗位名"] = job_info["崗位名"].apply(rename)
job_info["崗位名"].value_counts()
# 數據統計、數據專員、數據分析統一歸為數據分析
job_info["崗位名"] = job_info["崗位名"].apply(lambda x:re.sub("數據專員","數據分析",x))
job_info["崗位名"] = job_info["崗位名"].apply(lambda x:re.sub("數據統計","數據分析",x))說明:首先我們構造了如上七個目標崗位的關鍵字眼。然后利用count()函數統計每一條記錄中,是否包含這七個關鍵字眼,如果包含就保留這個字段,不過不包含就刪除這個字段。最后查看篩選之后還剩余多少條記錄。
③ 目標崗位標準化處理(由于目標崗位太雜亂,我們需要統一一下)
job_list = ['數據分析', "數據統計","數據專員",'數據挖掘', '算法',
'大數據','開發工程師', '運營', '軟件工程', '前端開發',
'深度學習', 'ai', '數據庫', '數據庫', '數據產品',
'客服', 'java', '.net', 'andrio', '人工智能', 'c++',
'數據管理',"測試","運維"]
job_list = np.array(job_list)
def rename(x=None,job_list=job_list):
index = [i in x for i in job_list]
if sum(index) > 0:
return job_list[index][0]
else:
return x
job_info["崗位名"] = job_info["崗位名"].apply(rename)
job_info["崗位名"].value_counts()
# 數據統計、數據專員、數據分析統一歸為數據分析
job_info["崗位名"] = job_info["崗位名"].apply(lambda x:re.sub("數據專員","數據分析",x))
job_info["崗位名"] = job_info["崗位名"].apply(lambda x:re.sub("數據統計","數據分析",x))說明:首先我們定義了一個想要替換的目標崗位job_list,將其轉換為ndarray數組。然后定義一個函數,如果某條記錄包含job_list數組中的某個關鍵詞,那么就將該條記錄替換為這個關鍵詞,如果某條記錄包含job_list數組中的多個關鍵詞,我們只取第一個關鍵詞替換該條記錄。接著使用value_counts()函數統計一下替換后的各崗位的頻次。最后,我們將“數據專員”、“數據統計”統一歸為“數據分析”。
4、工資水平字段的處理
工資水平字段的數據類似于“20-30萬/年”、“2.5-3萬/月”和“3.5-4.5千/月”這樣的格式。我們需要做一個統一的變化,將數據格式轉換為“元/月”,然后取出這兩個數字,求一個平均值。
job_info["工資"].str[-1].value_counts()
job_info["工資"].str[-3].value_counts()
index1 = job_info["工資"].str[-1].isin(["年","月"])
index2 = job_info["工資"].str[-3].isin(["萬","千"])
job_info = job_info[index1 & index2]
def get_money_max_min(x):
try:
if x[-3] == "萬":
z = [float(i)*10000 for i in re.findall("[0-9]+\.?[0-9]*",x)]
elif x[-3] == "千":
z = [float(i) * 1000 for i in re.findall("[0-9]+\.?[0-9]*", x)]
if x[-1] == "年":
z = [i/12 for i in z]
return z
except:
return x
salary = job_info["工資"].apply(get_money_max_min)
job_info["最低工資"] = salary.str[0]
job_info["最高工資"] = salary.str[1]
job_info["工資水平"] = job_info[["最低工資","最高工資"]].mean(axis=1)說明:首先我們做了一個數據篩選,針對于每一條記錄,如果最后一個字在“年”和“月”中,同時第三個字在“萬”和“千”中,那么就保留這條記錄,否則就刪除。接著定義了一個函數,將格式統一轉換為“元/月”。最后將最低工資和最高工資求平均值,得到最終的“工資水平”字段。
5、工作地點字段的處理
由于整個數據是關于全國的數據,涉及到的城市也是特別多。我們需要自定義一個常用的目標工作地點字段,對數據做一個統一處理。
#job_info["工作地點"].value_counts() address_list = ['北京', '上海', '廣州', '深圳', '杭州', '蘇州', '長沙', '武漢', '天津', '成都', '西安', '東莞', '合肥', '佛山', '寧波', '南京', '重慶', '長春', '鄭州', '常州', '福州', '沈陽', '濟南', '寧波', '廈門', '貴州', '珠海', '青島', '中山', '大連','昆山',"惠州","哈爾濱","昆明","南昌","無錫"] address_list = np.array(address_list) def rename(x=None,address_list=address_list): index = [i in x for i in address_list] if sum(index) > 0: return address_list[index][0] else: return x job_info["工作地點"] = job_info["工作地點"].apply(rename)
說明:首先我們定義了一個目標工作地點列表,將其轉換為ndarray數組。接著定義了一個函數,將原始工作地點記錄,替換為目標工作地點中的城市。
6、公司類型字段的處理
這個很容易,就不詳細說明了。
job_info.loc[job_info["公司類型"].apply(lambda x:len(x)<6),"公司類型"] = np.nan job_info["公司類型"] = job_info["公司類型"].str[2:-2]
7、行業字段的處理
每個公司的行業字段可能會有多個行業標簽,但是我們默認以第一個作為該公司的行業標簽。
# job_info["行業"].value_counts()
job_info["行業"] = job_info["行業"].apply(lambda x:re.sub(",","/",x))
job_info.loc[job_info["行業"].apply(lambda x:len(x)<6),"行業"] = np.nan
job_info["行業"] = job_info["行業"].str[2:-2].str.split("/").str[0]8、經驗與學歷字段的處理
關于這個字段的數據處理,我很是思考了一會兒,不太好敘述,放上代碼自己下去體會。
job_info["學歷"] = job_info["經驗與學歷"].apply(lambda x:re.findall("本科|大專|應屆生|在校生|碩士",x))
def func(x):
if len(x) == 0:
return np.nan
elif len(x) == 1 or len(x) == 2:
return x[0]
else:
return x[2]
job_info["學歷"] = job_info["學歷"].apply(func)9、工作描述字段的處理
對于每一行記錄,我們去除停用詞以后,做一個jieba分詞。
with open(r"G:\8泰迪\python_project\51_job\stopword.txt","r") as f: stopword = f.read() stopword = stopword.split() stopword = stopword + ["任職","職位"," "] job_info["工作描述"] = job_info["工作描述"].str[2:-2].apply(lambda x:x.lower()).apply(lambda x:"".join(x))\ .apply(jieba.lcut).apply(lambda x:[i for i in x if i not in stopword]) job_info.loc[job_info["工作描述"].apply(lambda x:len(x) < 6),"工作描述"] = np.nan
10、公司規模字段的處理
#job_info["公司規模"].value_counts() def func(x): if x == "['少于50人']": return "<50" elif x == "['50-150人']": return "50-150" elif x == "['150-500人']": return '150-500' elif x == "['500-1000人']": return '500-1000' elif x == "['1000-5000人']": return '1000-5000' elif x == "['5000-10000人']": return '5000-10000' elif x == "['10000人以上']": return ">10000" else: return np.nan job_info["公司規模"] = job_info["公司規模"].apply(func)
11、構造新數據
我們針對最終清洗干凈的數據,選取需要分析的字段,做一個數據存儲。
feature = ["公司名","崗位名","工作地點","工資水平","發布日期","學歷","公司類型","公司規模","行業","工作描述"] final_df = job_info[feature] final_df.to_excel(r"G:\8泰迪\python_project\51_job\詞云圖.xlsx",encoding="gbk",index=None)
由于我們之后需要針對不同的崗位名做不同的詞云圖處理,并且是在tableau中做可視化展示,因此我們需要按照崗位名分類,求出不同崗位下各關鍵詞的詞頻統計。
import numpy as np
import pandas as pd
import re
import jieba
import warnings
warnings.filterwarnings("ignore")
df = pd.read_excel(r"G:\8泰迪\python_project\51_job\new_job_info1.xlsx",encoding="gbk")
df
def get_word_cloud(data=None, job_name=None):
words = []
describe = data['工作描述'][data['崗位名'] == job_name].str[1:-1]
describe.dropna(inplace=True)
[words.extend(i.split(',')) for i in describe]
words = pd.Series(words)
word_fre = words.value_counts()
return word_fre
zz = ['數據分析', '算法', '大數據','開發工程師', '運營', '軟件工程','運維', '數據庫','java',"測試"]
for i in zz:
word_fre = get_word_cloud(data=df, job_name='{}'.format(i))
word_fre = word_fre[1:].reset_index()[:100]
word_fre["崗位名"] = pd.Series("{}".format(i),index=range(len(word_fre)))
word_fre.to_csv(r"G:\8泰迪\python_project\51_job\詞云圖\bb.csv", mode='a',index=False, header=None,encoding="gbk")1、熱門城市的用人需求TOP10
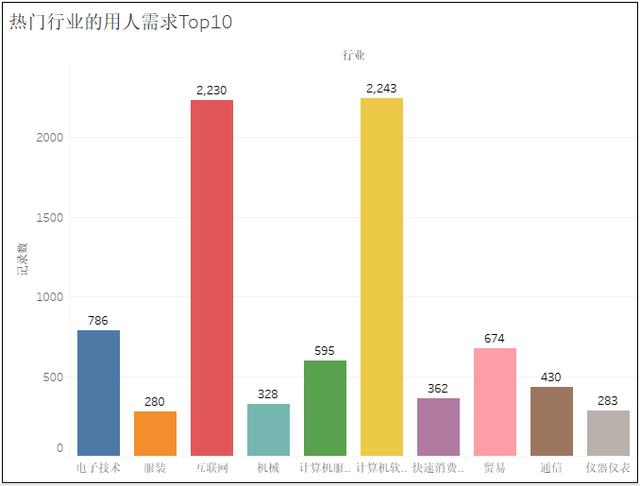
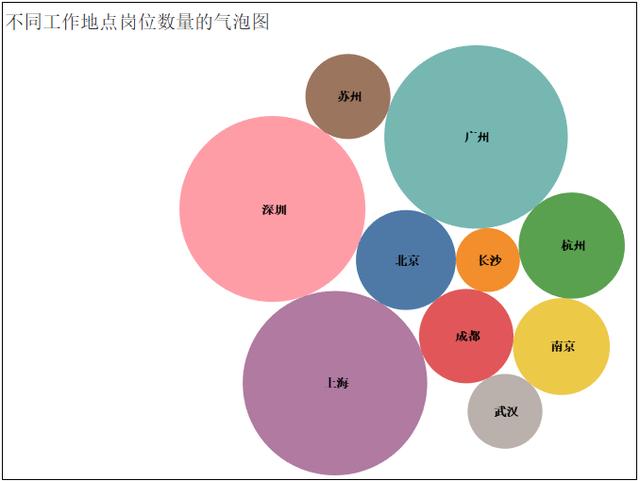
2、熱門城市的崗位數量TOP10
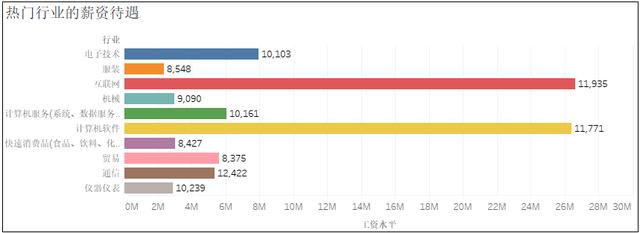
4、熱門崗位的薪資待遇
關于如何讓Python爬取招聘網站數據并實現可視化交互大屏問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





