溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何讓Python爬取招聘網站數據并做數據可視化處理,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
基本開發環境
Python 3.6
Pycharm
相關模塊使用
爬蟲模塊
import requests import re import parsel import csv
詞云模塊
import jieba import wordcloud
目標網頁分析
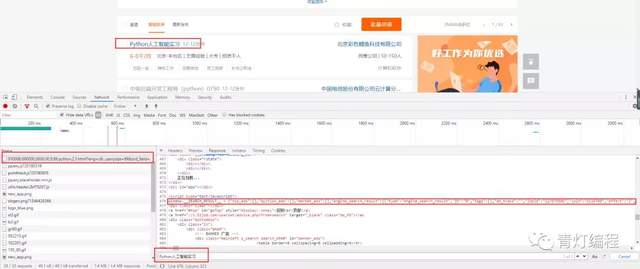
'https://jobs.51job.com/beijing-ftq/127676506.html?s=01&t=0'
每一個招聘信息的詳情頁都是有對應的ID,只需要正則匹配提取ID值,通過拼接URL,然后再去招聘詳情頁提取招聘數據即可。
response = requests.get(url=url, headers=headers)
lis = re.findall('"jobid":"(\d+)"', response.text)
for li in lis:
page_url = 'https://jobs.51job.com/beijing-hdq/{}.html?s=01&t=0'.format(li)雖然網站是靜態網頁,但是網頁編碼是亂碼,在爬取的過程中需要轉碼。
f = open('招聘.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['標題', '地區', '工作經驗', '學歷', '薪資', '福利', '招聘人數', '發布日期'])
csv_writer.writeheader()
response = requests.get(url=page_url, headers=headers)
response.encoding = response.apparent_encoding
selector = parsel.Selector(response.text)
title = selector.css('.cn h2::text').get() # 標題
salary = selector.css('div.cn strong::text').get() # 薪資
welfare = selector.css('.jtag div.t1 span::text').getall() # 福利
welfare_info = '|'.join(welfare)
data_info = selector.css('.cn p.msg.ltype::attr(title)').get().split(' | ')
area = data_info[0] # 地區
work_experience = data_info[1] # 工作經驗
educational_background = data_info[2] # 學歷
number_of_people = data_info[3] # 招聘人數
release_date = data_info[-1].replace('發布', '') # 發布日期
all_info_list = selector.css('div.tCompany_main > div:nth-child(1) > div p span::text').getall()
all_info = '\n'.join(all_info_list)
dit = {
'標題': title,
'地區': area,
'工作經驗': work_experience,
'學歷': educational_background,
'薪資': salary,
'福利': welfare_info,
'招聘人數': number_of_people,
'發布日期': release_date,
}
csv_writer.writerow(dit)
with open('招聘信息.txt', mode='a', encoding='utf-8') as f:
f.write(all_info)
以上步驟即可完成關于招聘的相關數據爬取。
簡單粗略的數據清洗
薪資待遇
content = pd.read_csv(r'D:\python\demo\數據分析\招聘\招聘.csv', encoding='utf-8') salary = content['薪資'] salary_1 = salary[salary.notnull()] salary_count = pd.value_counts(salary_1)

學歷要求
content = pd.read_csv(r'D:\python\demo\數據分析\招聘\招聘.csv', encoding='utf-8')
educational_background = content['學歷']
educational_background_1 = educational_background[educational_background.notnull()]
educational_background_count = pd.value_counts(educational_background_1).head()
print(educational_background_count)
bar = Bar()
bar.add_xaxis(educational_background_count.index.tolist())
bar.add_yaxis("學歷", educational_background_count.values.tolist())
bar.render('bar.html')
顯示招聘人數為無要求
工作經驗
content = pd.read_csv(r'D:\python\demo\數據分析\招聘\招聘.csv', encoding='utf-8')
work_experience = content['工作經驗']
work_experience_count = pd.value_counts(work_experience)
print(work_experience_count)
bar = Bar()
bar.add_xaxis(work_experience_count.index.tolist())
bar.add_yaxis("經驗要求", work_experience_count.values.tolist())
bar.render('bar.html')詞云分析,技術點要求
py = imageio.imread("python.png")
f = open('python招聘信息.txt', encoding='utf-8')
re_txt = f.read()
result = re.findall(r'[a-zA-Z]+', re_txt)
txt = ' '.join(result)
# jiabe 分詞 分割詞匯
txt_list = jieba.lcut(txt)
string = ' '.join(txt_list)
# 詞云圖設置
wc = wordcloud.WordCloud(
width=1000, # 圖片的寬
height=700, # 圖片的高
background_color='white', # 圖片背景顏色
font_path='msyh.ttc', # 詞云字體
mask=py, # 所使用的詞云圖片
scale=15,
stopwords={' '},
# contour_width=5,
# contour_color='red' # 輪廓顏色
)
# 給詞云輸入文字
wc.generate(string)
# 詞云圖保存圖片地址
wc.to_file(r'python招聘信息.png')
總結:
數據分析是真的粗糙,屬實辣眼睛。
看完上述內容,你們掌握如何讓Python爬取招聘網站數據并做數據可視化處理的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





