溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“如何理解LinkedList源碼”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“如何理解LinkedList源碼”吧!
LinkedList類圖如下:
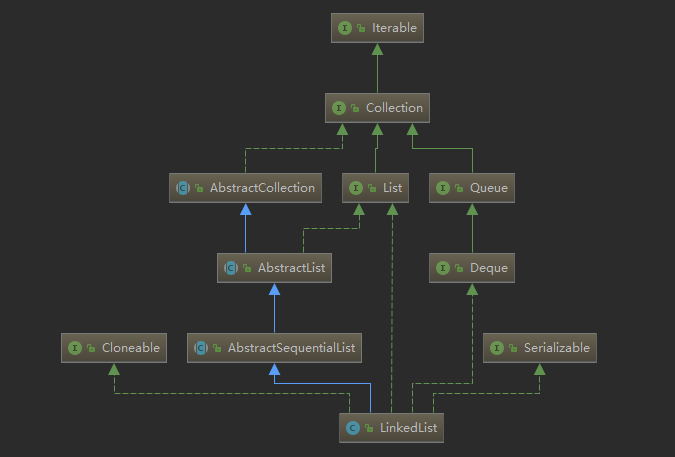
LinkedList底層是由雙向鏈表實現的。鏈表好比火車,每節車廂包含了車廂和連接下一節車廂的連接點。而雙向鏈表的每個節點不僅有指向下一個節點的指針,還有指向上一個節點的指針。 在LinkedList源碼中有一個Node靜態類,源碼如下:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}一個Node節點包含三個部分,分別是
item:數據
next:下一個節點的指針
prev:上一個節點的指針
LinkedList的主要變量如下:
// 集合中的元素數量 transient int size = 0; /** * 首節點的指針. * Invariant: (first == null && last == null) || * (first.prev == null && first.item != null) */ transient Node<E> first; /** * 尾結點的指針. * Invariant: (first == null && last == null) || * (last.next == null && last.item != null) */ transient Node<E> last;
LinkedList支持想任意節點位置添加元素,不僅提供了集合常用的add()方法,還提供了addFirst()和addLast(),add()方法默認調用addLast()方法,也就是默認是往鏈表尾部插入元素的。
add()方法源碼:
public boolean add(E e) {
linkLast(e);
return true;
}linkLast()源碼如下:
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}我們來畫張圖演示一下如何給鏈表尾部插入元素:
假如鏈表中沒有元素
對應源碼中的if語句,如果沒有元素則新增的這個節點為鏈表中唯一的一個元素,既是首節點,又是尾結點,前一個元素的指針和后一個元素的指針都是null。這里注意head節點不是第一個節點,head節點只是標識了這個鏈表的地址。

假如鏈表中有元素
對應源碼中else語句。先將新增的元素當成Last節點,然后將原來的Last節點的next指向新節點。
else l.next = newNode;
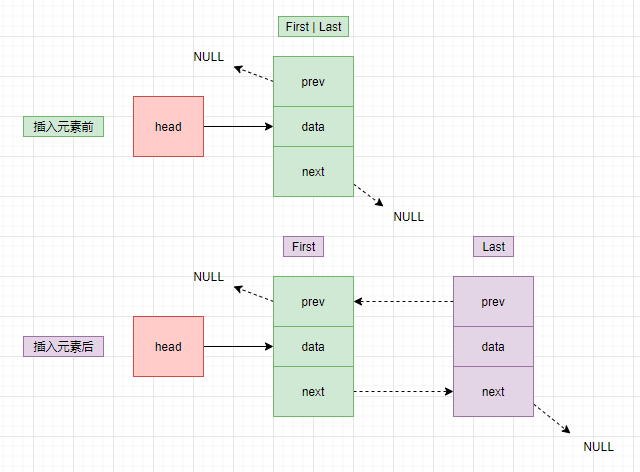
一圖勝前言,畫個圖是不是什么都明白了。
linkFirst()源碼如下:
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}還是根據上面的圖來解讀一下源碼,先將第一個節點賦值給中間變量f,將新節點newNode賦值給first節點。如果鏈表沒有元素,則Last節點和First節點都是新插入的節點newNode,否則,將原來的First節點的頭指針指向新節點。
LinkedList提供的刪除方法有根據索引和元素刪除,除此之外還提供刪除第一個元素和最后一個元素的方法,這里我們只分析一下根據索引刪除的方法。
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}checkElementIndex(index)方法就是用來判斷傳輸的索引值是否合法,不合法則拋出數組越界異常。重點來看一下unlink(node(index))方法是如何刪除元素的。
node(index)方法源碼:
node(index)方法就是根據索引獲取該索引位置的節點
Node<E> node(int index) {
// assert isElementIndex(index);
// 如果指定下標 < 一半元素數量,則從首結點開始遍歷
// 否則,從尾結點開始遍歷
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}unlink(Node<E> x)源碼如下:
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}畫張圖分析一下刪除是如何進行的:

假設刪除的是第一個元素:則它的prev==NULL,我們需要將他的后一個元素(圖中的second)作為第一個元素
假設刪除的是最后一個元素,則它的next==null,我們需要將他的前一個元素(途中的second)作為最后一個元素
如果是中間的任意元素,則需要將它的前一個元素的next指針指向它的后一個元素,同時將它的后一個元素的prev指針指向它的前一個元素。
到此,相信大家對“如何理解LinkedList源碼”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





