溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“怎么理解LinkedList源碼”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“怎么理解LinkedList源碼”吧!
LinkedList是也是非常常見的集合類,LinkedList是基于鏈表實現的集合。它擁有List集合的特點:
存取有序
帶索引
允許重復元素
還擁有Deque集合的特點:
先入先出
雙端操作
它本身的特點是:
對元素進行插入或者刪除,只需要更改一些數據,不需要元素進行移動。
依然是通過源碼來看看LinkedList如何實現自己的特性的。
Doubly-linked list implementation of the {@code List} and {@code Deque} interfaces. Implements all optional list operations,and permits all elements (including {@code null}).
對于List接口和Deque接口的雙鏈表實現。實現了所有List接口的操作并且能存儲所有的元素。
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable
可以看到LinkedList實現了一個Deque接口,其實是說,LinkedList除了有List的特性,還有Deque的特性,那么Deque是什么呢?
public interface Deque<E> extends Queue<E> public interface Queue<E> extends Collection<E>
原來是繼承了Collection集合的另一個接口。
Queue就是我們常說的隊列,它的特性是FIFO( First In First Out )先進先出,它的操作只有兩個:
把元素存進隊列尾部
從頭部取出元素
就像排隊辦事一樣的。
而它的子接口Deque除了這兩操作以外,還能比Queue隊列有更多的功能
既可以添加元素到隊尾,也可以添加元素到隊頭
既可以從隊尾取元素,也可以從隊頭取元素
如此看來就像兩邊都可以當隊頭和隊尾一樣,所以Deque又叫雙端隊列 。
理所應當的,LinkedLisk也實現了這些特性,并且有Doubly-linked(雙鏈表的特性)。
那么什么又是鏈表呢?
其實鏈表是一種線性的存儲結構,意思是將要存儲的數據存在一個存儲單元里面,這個存儲單元里面除了存放有待存儲的數據以外,還存儲有其下一個存儲單元的地址。
雙鏈表顧名思義,存儲單元除了存儲其下一個存儲單元的地址,還存儲了上一個存儲單元的地址。每次查找數據的時候,就通過存儲單元里存儲的地址信息進行查找。
成員變量:
transient int size = 0; transient Node<E> first; transient Node<E> last;
只有三個,size代表LinkedList存儲的元素個數。那這個Node是什么?
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}它是LinkedList內部的數據結構Node,作為LinkedList的基本存儲單元,也最能體現LinkedList雙鏈表的特性。
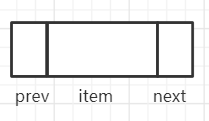 像這樣的。
像這樣的。
其中prev存儲上一個節點的引用(地址),next存儲下一個單元的引用,item就是具體要存的數據。
First和Last用來標明隊頭跟隊尾。
添加數據:
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}默認是調用添加到尾部的方法。前面說過,LinkedList的基本存儲單元是Node,所以添加進來的數據會被封裝進Node的item屬性里,而且這個新Node的prev會指向前一個Node,前一個Node的next會指向這個新Node。
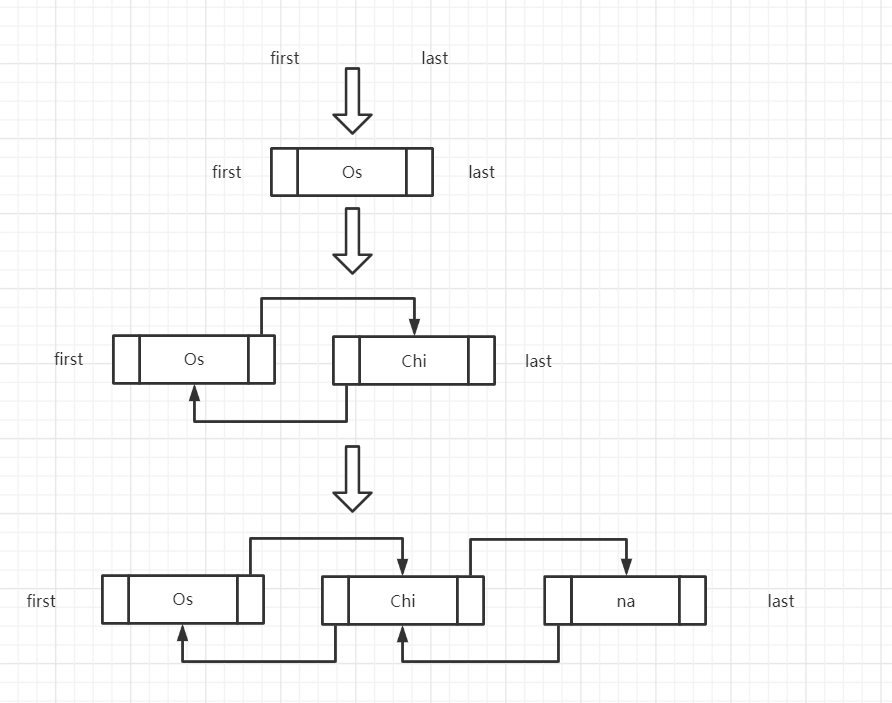
類似這樣,但是注意畫線只是一種形象的表達方法,就如上面所說,在Node里的prev屬性和next屬性是用來存儲引用的,通過這個引用就能找到前一個Node或者后一個Node。
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
public void addLast(E e) {
linkLast(e);
}
public boolean offerLast(E e) {
addLast(e);
return true;
}其實LinkedList很多不同名的方法,但是實現方式都是類似的,這是因為我們有可能用LinkedList表達不同的數據結構,雖然都是添加元素到隊首/隊尾,但是清晰的描述對代碼的可讀性是有好處的。像如果要用LinkedList表示Stack(棧)數據結構時候用push()/pop()/peek()等方法來描述,用LinkedList表示Queue(隊列)數據結構時候用add()/offer()等方法來描述。(當然,更好的實現方式是多態。)
刪除數據:
//刪除頭Node
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
//刪除操作
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
//刪除尾Node
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
//刪除操作
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
//拿到最后一個元素存放的數據
final E element = l.item;
//拿到最后一個元素的prev前元素的引用
final Node<E> prev = l.prev;
//將它們賦值為null
l.item = null;
l.prev = null; // help GC
//現在前元素是list(最后一個Node)
last = prev;
//如果前元素已經是null說明沒有Node了
if (prev == null)
first = null;
else
//說明前面還有元素,那么前元素的next就存放null
prev.next = null;
size--;
modCount++;
return element;
}先看看簡單的刪除, 這里是指定刪除最前跟最后的元素,所以只要判斷刪除后Node的prev或者next是否還有值,有就說明還有Node,沒有就說明LinkedList已經為空了。
怎樣才算刪除了頭/尾Node,只要它的next/prev為空,說明沒有引用指向它了,那么我們就認為它從LinkedList里刪除了,因為我們無法通過存儲單元的引用找到這個Node,所以GC很快也會來回收掉這個Node。
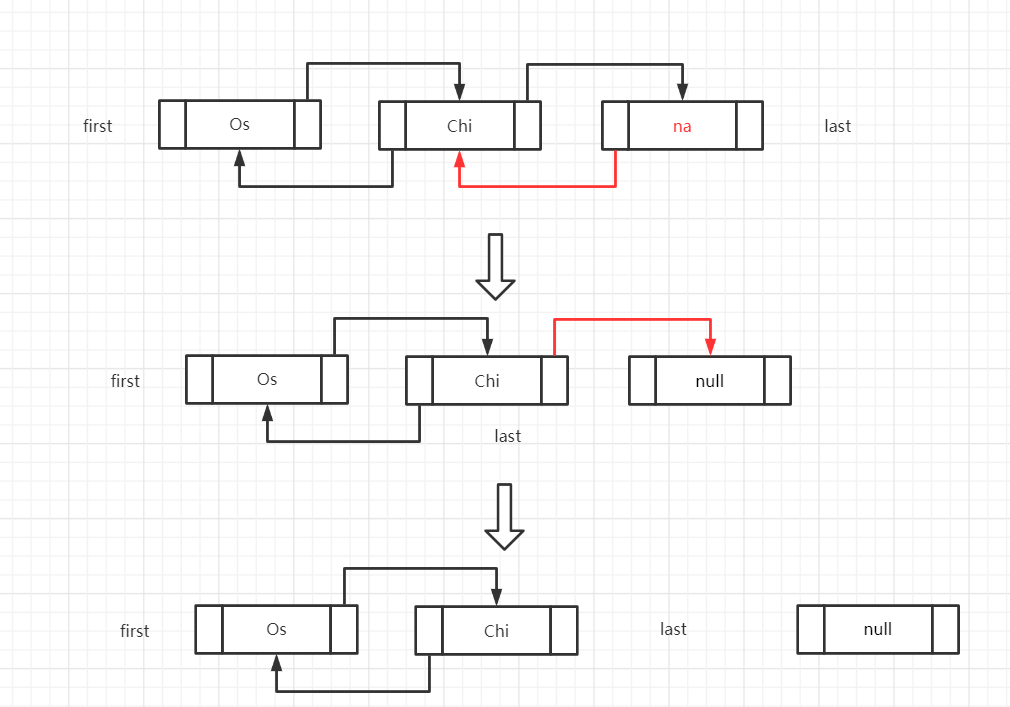
這只是刪除頭尾Node,那要是刪除中間的Node呢?這要跟下面的查找和插入一起看。
查找元素:
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
// assert isElementIndex(index);
//如果索引小于元素個數的一半,就從前遍歷
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {//否則從后遍歷
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}數組默認是有下標的,可以一次就取出所在位置的元素,但是LinkedList底層可沒有維護這么一個數組,那怎么知道第幾個元素是什么呢?
笨方法,我有size個元素,我不知道你指定的index在哪,那我一個一個找過去不就完事了?畢竟我的存儲單元Node記得它旁邊的單元的引用(地址)。
如果你的index比我size的一半還大,那我就從后面找,因為我是雙端隊列,有Last的引用(地址),所以可以調換兩頭。
所以,在LinkedList里面找元素可不容易,最多可能要找size/2次才能找到。
只要找到了想要的位置,那么插入和刪除指定的這個Node就很簡單了。
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
E unlink(Node<E> x) {
// assert x != null;
//拿到所要刪除的Node的item
final E element = x.item;
//后一個Node
final Node<E> next = x.next;
//前一個Node
final Node<E> prev = x.prev;
//如果前一個Node為null(說明是第一個Node)
if (prev == null) {
//那么后一個Node作為first
first = next;
} else {//否則說明前面有Node
//那前一個Node的下一個Node引用變為后一個Node
prev.next = next;
//當前的前引用變成null
x.prev = null;
}
//如果后一個Node為null(說明是最后一個Node)
if (next == null) {
//那么前一個Node作為last
last = prev;
} else {//否則說明后面還有Node
//那后一個Node的下一個Node引用變為前一個Node
next.prev = prev;
//當前的后引用變為null
x.next = null;
}
//保存的元素也設為null
x.item = null;
//元素-1
size--;
//修改次數+1
modCount++;
return element;
}
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
//要插入位置的前一個Node
final Node<E> pred = succ.prev;
//新Node,前引用是前一個Node,后引用是當前位置的Node
final Node<E> newNode = new Node<>(pred, e, succ);
//后一個Node的前引用變為這個新Node
succ.prev = newNode;
//如果沒有前一個Node
if (pred == null)
//說明添加的就是第一個Node了
first = newNode;
else//說明前面還有Node
//將前一個Node的后引用變為這個新的Node
pred.next = newNode;
//元素+1
size++;
modCount++;
}只是改變了存儲單元Node里的prev和next,我們就可以認為這個Node被插入/刪除了。
代碼的注釋配合著下圖看,就會方便理解很多,其中注意區分源代碼中的命名,最好拿筆記一下容易區分一些。
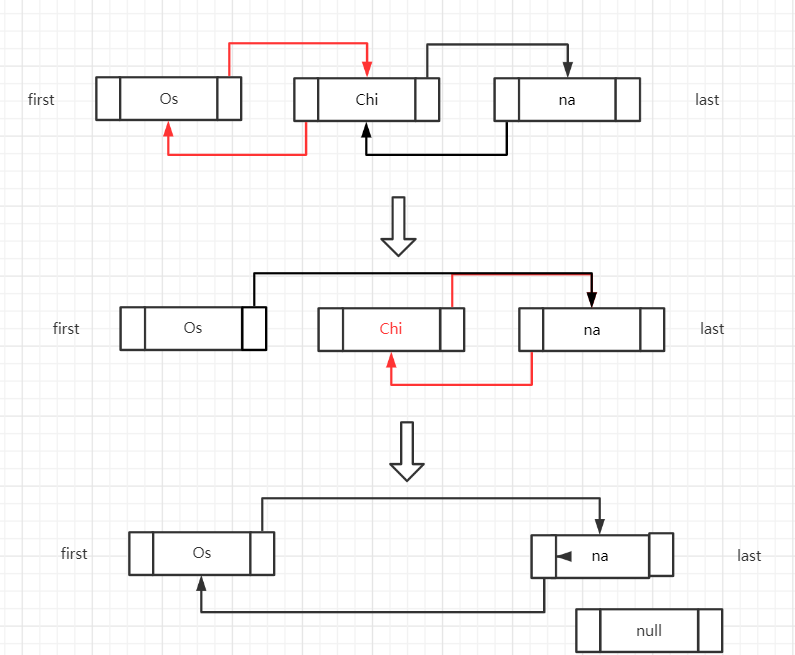
如果是插入元素,倒著看就可以了。
關于遍歷:
我們可以了解到,LinkedList最大的性能消耗就在node(index)這步,這會需要去查找大量的元素。但是只要找到了這個元素所在的Node,插入跟刪除就非常的方便了。
所以對于get(index)這個方法,我們需要非常小心的去使用,如果只想看一看這個位置的元素,可以用這個方法,但是如果是遍歷LinkedList,千萬不可以這樣寫:
for (int i = 0; i < linkedList.size(); i++) {
linkedList.get(i).equals(Obj);
}這樣對于每次循環,get總會從前或者從后走i次,不考慮get方法中>>1的優化的話,這是一種O(n^2)時間復雜度的做法,效率十分低下。
所以LinkedList提供了內部的Iterator迭代器供我們使用:
private class ListItr implements ListIterator<E> {
private Node<E> lastReturned;
private Node<E> next;
private int nextIndex;
private int expectedModCount = modCount;
ListItr(int index) {
// assert isPositionIndex(index);
next = (index == size) ? null : node(index);
nextIndex = index;
}
public boolean hasNext() {
return nextIndex < size;
}
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}其實就是通過不斷調用next()方法取得Node,然后再對Node做操作,這樣時間復雜度就是O(n)了,不會有大量重復無用的遍歷。
到此,相信大家對“怎么理解LinkedList源碼”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





