溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了怎樣使用Apache Flink中的Table SQL APIx,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
雖然Flink已經支持了DataSet和DataStream API,但是有沒有一種更好的方式去編程,而不用關心具體的API實現?不需要去了解Java和Scala的具體實現。
Flink provides three layered APIs. Each API offers a different trade-off between conciseness and expressiveness and targets different use cases.
Flink提供了三層API,每一層API提供了一個在簡潔性和表達力之間的權衡 。
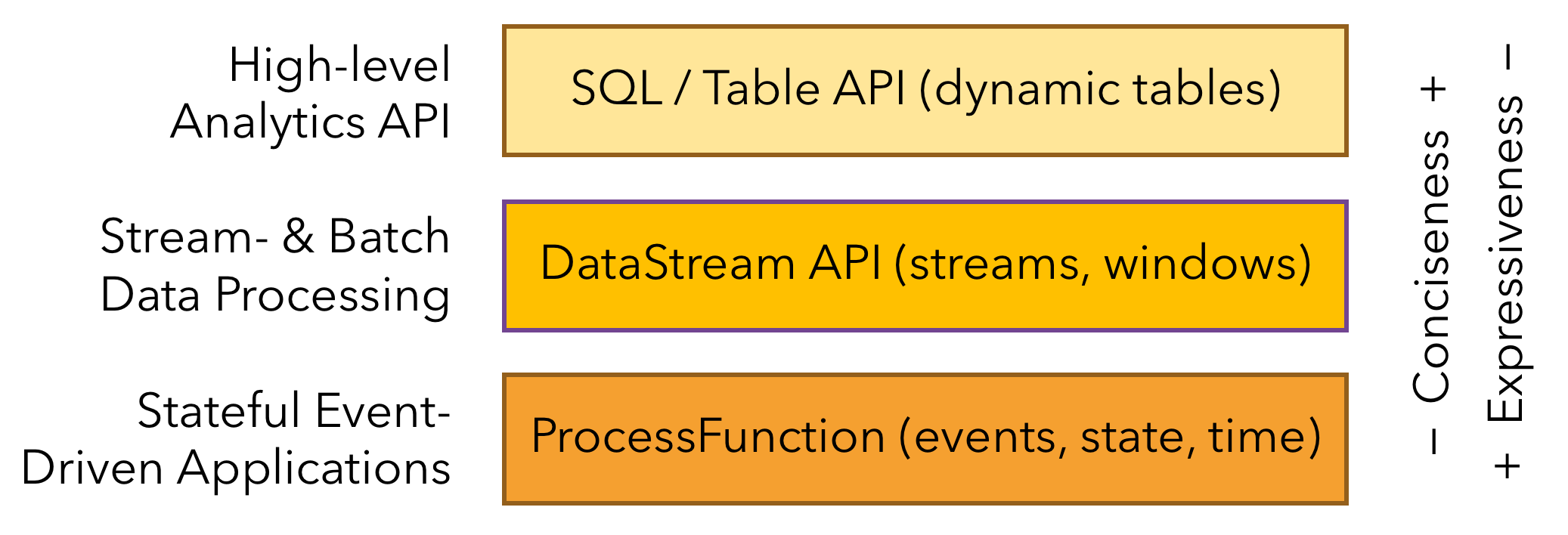
最低層是一個有狀態的事件驅動。在這一層進行開發是非常麻煩的。
雖然很多功能基于DataSet和DataStreamAPI是可以完成的,需要熟悉這兩套API,而且必須要熟悉Java和Scala,這是有一定的難度的。一個框架如果在使用的過程中沒法使用SQL來處理,那么這個框架就有很大的限制。雖然對于開發人員無所謂,但是對于用戶來說卻不顯示。因此SQL是非常面向大眾語言。
好比MapReduce使用Hive SQL,Spark使用Spark SQL,Flink使用Flink SQL。
雖然Flink支持批處理/流處理,那么如何做到API層面的統一?
這樣Table和SQL應運而生。
這其實就是一個關系型API,操作起來如同操作Mysql一樣簡單。
Apache Flink features two relational APIs - the Table API and SQL - for unified stream and batch processing. The Table API is a language-integrated query API for Scala and Java that allows the composition of queries from relational operators such as selection, filter, and join in a very intuitive way.
Apache Flink通過使用Table API和SQL 兩大特性,來統一批處理和流處理。 Table API是一個查詢API,集成了Scala和Java語言,并且允許使用select filter join等操作。
使用Table SQL API需要額外依賴
java:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>scala:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>首先導入上面的依賴,然后讀取sales.csv文件,文件內容如下:
transactionId,customerId,itemId,amountPaid 111,1,1,100.0 112,2,2,505.0 113,1,3,510.0 114,2,4,600.0 115,3,2,500.0 116,4,2,500.0 117,1,2,500.0 118,1,2,500.0 119,1,3,500.0 120,1,2,500.0 121,2,4,500.0 122,1,2,500.0 123,1,4,500.0 124,1,2,500.0
object TableSQLAPI {
def main(args: Array[String]): Unit = {
val bEnv = ExecutionEnvironment.getExecutionEnvironment
val bTableEnv = BatchTableEnvironment.create(bEnv)
val filePath="E:/test/sales.csv"
// 已經拿到DataSet
val csv = bEnv.readCsvFile[SalesLog](filePath,ignoreFirstLine = true)
// DataSet => Table
}
case class SalesLog(transactionId:String,customerId:String,itemId:String,amountPaid:Double
)
}首先拿到DataSet,接下來將DataSet轉為Table,然后就可以執行SQL了
// DataSet => Table
val salesTable = bTableEnv.fromDataSet(csv)
// 注冊成Table Table => table
bTableEnv.registerTable("sales", salesTable)
// sql
val resultTable = bTableEnv.sqlQuery("select customerId, sum(amountPaid) money from sales group by customerId")
bTableEnv.toDataSet[Row](resultTable).print()輸出結果如下:
4,500.0 3,500.0 1,4110.0 2,1605.0
這種方式只需要使用SQL就可以實現之前寫mapreduce的功能。大大方便了開發過程。
package com.vincent.course06;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.BatchTableEnvironment;
import org.apache.flink.types.Row;
public class JavaTableSQLAPI {
public static void main(String[] args) throws Exception {
ExecutionEnvironment bEnv = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment bTableEnv = BatchTableEnvironment.create(bEnv);
DataSource<Sales> salesDataSource = bEnv.readCsvFile("E:/test/sales.csv").ignoreFirstLine().
pojoType(Sales.class, "transactionId", "customerId", "itemId", "amountPaid");
Table sales = bTableEnv.fromDataSet(salesDataSource);
bTableEnv.registerTable("sales", sales);
Table resultTable = bTableEnv.sqlQuery("select customerId, sum(amountPaid) money from sales group by customerId");
DataSet<Row> rowDataSet = bTableEnv.toDataSet(resultTable, Row.class);
rowDataSet.print();
}
public static class Sales {
public String transactionId;
public String customerId;
public String itemId;
public Double amountPaid;
@Override
public String toString() {
return "Sales{" +
"transactionId='" + transactionId + '\'' +
", customerId='" + customerId + '\'' +
", itemId='" + itemId + '\'' +
", amountPaid=" + amountPaid +
'}';
}
}
}上述內容就是怎樣使用Apache Flink中的Table SQL APIx,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





