溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關Apache Flink 1.11 功能有哪些呢,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
下面將詳細介紹 1.11 版本的新功能、改進、重要變化及未來的發展計劃。
在集群部署方面
1.[FLIP-85] Flink 支持 Application Mode
目前 Flink 是通過一個單獨的客戶端來創建 JobGraph 并提交作業的,在實際使用時,會產生下載作業 jar 包占用客戶端機器大量帶寬、需要啟動單獨進程(占用不受管理的資源)作為客戶端等問題。為了解決這些問題,在 Flink-1.11 中提供了一種新的 Application 模式,它將 JobGraph 的生成以及作業的提交轉移到 Master 節點進行。
用戶可以通過 bin/flink run-application 來使用 application 模式。目前 Application 模式支持 Yarn 和 K8s 的部署方式,Yarn Application 模式會在客戶端將運行任務需要的依賴都通過 Yarn Local Resource 傳遞到 Flink Master,然后在 Master 端進行任務的提交。K8s Application 允許用戶構建包含用戶 Jar 與依賴的鏡像,同時會根據 job 自動創建 TaskManager,并在結束后銷毀整個 Cluster。
2. [Flink-13938] [Flink-17632] Flink Yarn 支持遠程 Flink lib Jar 緩存和使用遠程 Jar 創建作業
1.11 之前 Flink 在 Yarn 上每提交一個作業都需要上傳一次 Flink lib 下的 Jars,從而耗費額外的存儲空間和通信帶寬。Flink-1.11 允許用戶提供多個遠程的 lib 目錄,這些目錄下的文件會被緩存到 Yarn 的節點上,從而避免不必要的 Jar 包上傳與下載,使提交和啟動更快:
./bin/flink run -m yarn-cluster -d \-yD yarn.provided.lib.dirs=hdfs://myhdfs/flink/lib,hdfs://myhdfs/flink/plugins \examples/streaming/WindowJoin.jar
此外,1.11 還允許用戶直接使用遠程文件系統上的 Jar 包來創建作業,從而進一步減少 Jar 包下載的開銷:
./bin/flink run-application -p 10 -t yarn-application \-yD yarn.provided.lib.dirs="hdfs://myhdfs/flink/lib" \hdfs://myhdfs/jars/WindowJoin.jar
3. [Flink-14460] Flink K8s 功能增強
在 1.11 中,Flink 對 K8s 除支持 FLIP-85 提出的 Application 模式,相比于 Session 模式,它具有更好的隔離性。
此外,Flink 還新增了一些功能用以支持 K8s 的特性,例如 Node Selector,Label,Annotation,Toleration 等。為了更方便的與 Hadoop 集成,也支持根據環境變量自動掛載 Hadoop 配置的功能。
4. [FLIP-111] docker 鏡像統一
之前 Flink 項目中提供了多個不同的 Dockerfile 用來創建 Flink 的 Docker 鏡像,現在他們被統一到了 apache/flink-docker [1] 項目中。
5. [Flink-15911][Flink-15154] 支持分別配置用于本地監聽綁定的網絡接口和外部訪問的地址和端口
在部分使用場景中(例如 Docker、NAT 端口映射),JM/TM 進程看到的本地網絡地址、端口,和其他進程用于從外部訪問該進程的地址、端口可能是不一樣的。之前 Flink 不允許用戶為 TM/JM 設置不同的本地和遠程地址,使 Flink 在 Docker 等使用的 NAT 網絡中存在問題,并且不能限制監聽端口的暴露范圍。
1.11 中為本地和遠程的監聽地址和端口引入了不同的參數。其中:
* jobmanager.rpc.address
* jobmanager.rpc.port
* taskmanager.host
* taskmanager.rpc.port
* taskmanager.data.port
用來配置遠程的監聽地址和端口,
* jobmanager.bind-host
* jobmanager.rpc.bind-port
* taskmanager.bind-host
* taskmanager.rpc.bind-port
* taskmanager.data.bind-port
用來配置本地的監聽地址和端口。
在資源管理方面
1. [Flink-16614] 統一 JM 端內存資源配置
Flink-1.10 中的一個大的改動是重新定義了 TM 內存模型與配置規則[2]。Flink 1.11 進一步對 JM 內存模型與配置規則進行了調整,使 JM 的內存配置方式與 TM 統一:
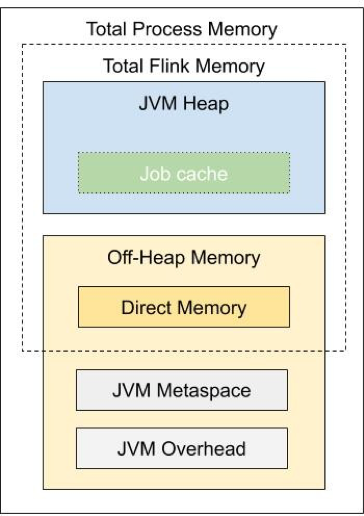
具體的內存配置方式可以參考相應的用戶文檔[3]。
2. [FLIP-108] 增加對擴展資源(如 GPU)的調度支持
隨著機器學習和深度學習的發展,越來越多的 Flink 作業會嵌入機器學習或深度學習模型,從而產生對 GPU 資源的需求。1.11 之前 Flink 不支持對 GPU 這樣的擴展資源進行管理。為了解決這一部分,在 1.11 中,Flink 提供了對擴展資源的統一管理框架,并基于這一框架內置了對 GPU 資源的支持。
關于擴展資源管理框架和 GPU 資源管理的進一步配置,可以參考相應的 FLIP 頁面:https://cwiki.apache.org/confluence/display/FLINK/FLIP-108%3A+Add+GPU+support+in+Flink的Publlic interface 部分(相應的用戶文檔社區正在編寫中,后續可以參考對應的用戶文檔)。
3. [FLINK-16605] 允許用戶限制 Batch 作業的最大 slot 數量
為了避免 Flink Batch 作業占用過多的資源,Flink-1.11 引入了一個新的配置項:slotmanager.number-of-slots.max,它可以限定整個 Flink 集群 Slot 的最大數量。這一參數只推薦用于使用了 Blink Planner 的 Batch Table / SQL 作業。
Flink-1.11 WEB UI 的增強
1. [FLIP-103] 改善 Web UI 上 JM/TM 日志的展示
之前用戶只能通過 Web UI 讀取 .log 和 .out 日志,但是實際上在日志目錄下可能還存在著其它文件,如 GC log 等。新版界面允許用戶訪問日志目錄下的所有日志。此外,還增加了日志重新加載、下載和全屏展示的功能。
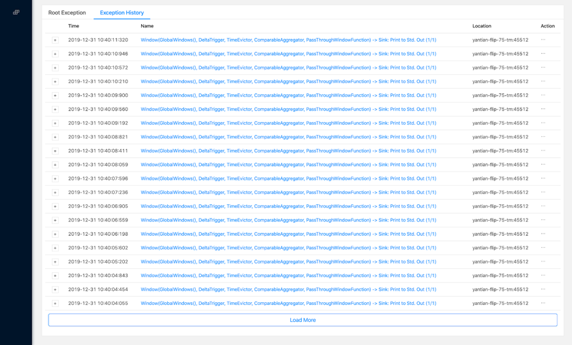
2. [FLIP-99] 允許展示更多的歷史 Failover 異常
之前對于單個作業,Web UI 只能展示單個 20 條歷史 Failover 異常,在作業頻繁 Failover 時,最開始的異常(更有可能是 root cause)很快會被淹沒,從而增加排查的難度。新版的 WEB UI 支持分頁展示更多的歷史異常。
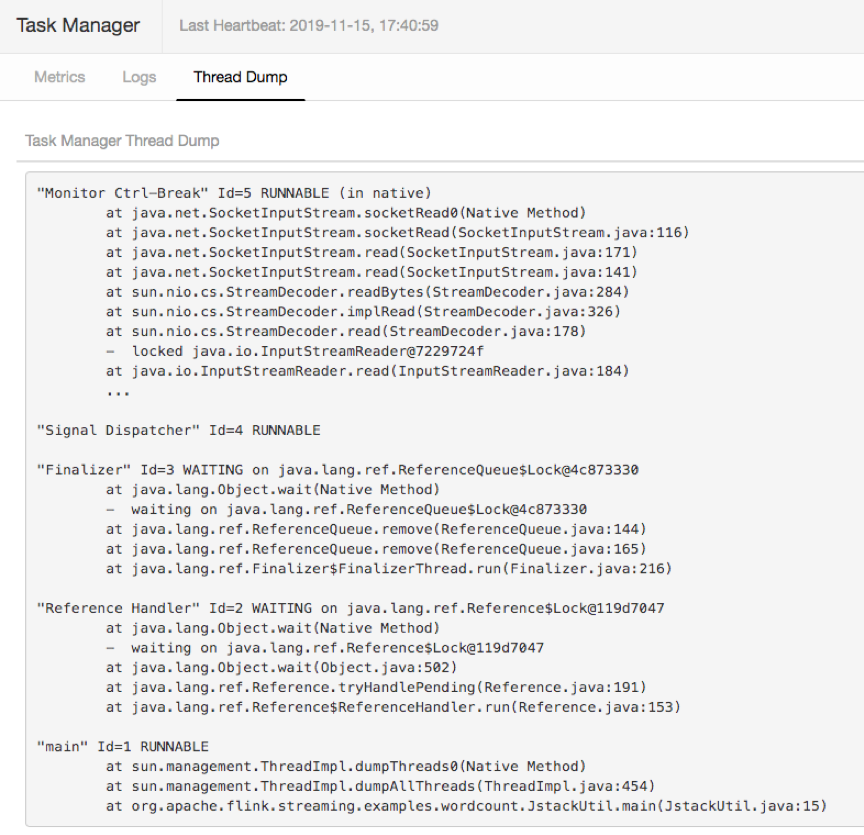
3. [Flink-14816] 允許用戶直接在頁面上進行 Thread Dump
Thread Dump 對一些作業的問題定位非常有幫助,1.11 之前用戶必須要登錄到 TM 所在機器來執行 Thread Dump 操作。1.11 的 WEB UI 集成了這一功能,它增加了 Thread dump 標簽頁,允許用戶直接通過 WEB UI 來獲得 TM 的 Thread Dump。
Source & Sink
FLIP-27 是 1.11 中一個較大的 Feature。Flink 傳統的 Source 接口存在一定的問題,例如需要為流作業和批作業分別實現不同的 Source、沒有統一的數據分區發現邏輯、需要 Source 實現者自己處理加鎖邏輯以及沒有提供公共架構使得 Source 開發者必須要手動處理多線程等問題。這些問題增加了 Flink 中實現 Source 的難度。
FLIP-27 引入了一套全新的 Source 的接口。這套接口提供了統一的數據分區發現和管理等功能,用戶只需要集中在分區信息讀取和數據讀取等邏輯,而不需要再處理復雜線程同步問題,從而極大的簡化了 Source 實現的負擔,也為后續為 Source 提供更多內置功能提供了基礎。
2. [FLINK-11395][Flink-10114] Streaming File Sink 新增對 Avro 和 ORC 格式的支持
對于常用的 StreamingFileSink,1.11 新增了對 Avro 和 ORC 兩種常用文件格式的支持。
Avro:
stream.addSink(StreamingFileSink.forBulkFormat( Path.fromLocalFile(folder), AvroWriters.forSpecificRecord(Address.class)).build());
ORC:
OrcBulkWriterFactory<Record> factory = new OrcBulkWriterFactory<>( new RecordVectorizer(schema), writerProps, new Configuration());Stream.addSink(StreamingFileSink .forBulkFormat(new Path(outDir.toURI()), factory) .build());
State 管理
Flink-1.11 將 Savepoint 中的文件絕對路徑替換為相對路徑,從而使用戶可以直接移動 Savepoint 的位置,而不需要再手動修改 meta 中的路徑(注:在 S3 文件系統中啟用 Entropy Injection 后不支持該功能)。
2. [FLINK-8871] 增加 Checkpoint 失敗的回調并通知 TM 端
Flink 1.11之前提供了Checkpoint成功的通知。在1.11中新增了Checkpoint失敗時通知TM端的機制,一方面可以取消正在進行中的Checkpoint,另外用戶通過CheckpointListener新增的notifyCheckpointAborted接口也可以收到對應的通知。
3. [FLINK-12692] heap keyed Statebackend 支持溢出數據到磁盤
(該功能實際并未合并到 Flink 1.11 代碼,但是用戶可以從 https://flink-packages.org/packages/spillable-state-backend-for-flink下載試用。)
對于 Heap Statebackend,由于它將 state 直接以 Java 對象的形式維護,因此它可以獲得較好的性能。但是,之前它 Heap State backend 占用的內存是不可控的,因引可以導致嚴重的 GC 問題。
為了解決這一問題,SpillableKeyedStateBackend 支持將數據溢出到磁盤,從而允許 Statebackend 限制所使用的內存大小。關于 SpillableKeyedStateBackend 的更多信息,可以參考 https://flink-packages.org/packages/spillable-state-backend-for-flink。
4. [Flink-15507] 對 Rocksdb Statebackend 默認啟用 Local Recovery
默認啟用 Local Recovery 后可以加速 Failover 的速度。
5. 修改 state.backend.fs.memory-threshold 參數默認值到 20k
(這部分工作還在進行中,但是應該會包含在 1.11 中)
state.backend.fs.memory-threshold 決定了 FS Statebackend 中什么時候需要將 State 數據寫出去內存中。之前默認的 1k 在許多情況下會導致大量小文件的問題并且會影響 State 訪問的性能,因此在 1.11 中該值被提高到了 20k。需要特別注意的是,這一改動可能會提高JM內存的使用量,尤其是在算子并發較大或者使用了UnionState的情況下。[4]
Table & SQL
相對于之前的類型推斷機制,新版的類型推斷機制可以提供關于輸入參數的更多類型信息,從而允許用戶實現更靈活的處理邏輯。目前這一功能提供了對 UDF 和 UTF 的支持,但暫時還不支持 UDAF。
2. [FLIP-84] 優化 TableEnvironment 的接口
Flink-1.11 對于 TableEnv 在以下方面進行了增強:
3. [FLIP-93] 支持基于 JDBC 和 Postgres的Catalog
1.11 之前用戶使用Flink讀取/寫入關系型數據庫或讀取 Change Log 時,需要手動將數據庫的表模式復制到 Flink 中。這一過程枯燥乏味且容易錯,從而較大的的提高了用戶的使用成本。1.11 提供了基于 JDBC 和 Postgres 的 Catalog 管理,使 Flink 可以自動讀取表模式,從而減少了用戶的手工操作。
4. [FLIP-105] 增加對 ChangeLog 源的支持
通過 Change Data Capture 機制(CDC)來將外部系統的動態數據(如 Mysql BinLog,Kafka Compacted Topic)導入 Flink,以及將 Flink 的 Update/Retract 流寫出到外部系統中是用戶一直希望的功能。Flink-1.11 實現了對 CDC 數據讀取和寫出的支持。目前 Flink 可以支持 Debezium 和 Canal 兩種 CDC 格式。
5. [FLIP-95] 新的 TableSource 和 TableSink 接口
簡化了當前 Table Source/Sink 的接口結構,為支持 CDC 功能提供了基礎,避免了對 DataStream API 的依賴以及解決只有 Blink Planner 可以支持高效的 Source/Sink 實現的問題。
更具體接口變化可以參考:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-95%3A+New+TableSource+and+TableSink+interfaces
6. [FLIP-122] 修改 Connector 配置項
FLIP-122 重新整理了 Table/SQL Connector 的”With”配置項。由于歷史原因,With 配置項有一些冗余或不一致的地方,例如所有的配置項都以 connector. 開頭以及不同的配置項名稱模式等。修改后的配置項解決了這些冗余和不一致的問題。(需要強調的是,現有的配置項仍然可以正常使用)。
關于新的配置項的列表,可以參考:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-122%3A+New+Connector+Property+Keys+for+New+Factory
7. [FLIP-113] Flink SQL 支持動態 Table 屬性
動態 Table 屬性允許用戶在使用表時動態的修改表的配置項,從而避免用戶由于配置項變化而需要重新聲明表的 DDL 的麻煩。如下所示,動態屬性允許用戶在執行查詢時通過 /*+ OPTIONS(‘k1’=’v1’)*/ 的語法來覆蓋 DDL 中的屬性值。
SELECT *FROM EMP /*+ OPTIONS('k1'='v1', 'k2'='v2') */ JOIN DEPT /*+ OPTIONS('a.b.c'='v3', 'd.e.f'='v4') */ON EMP.deptno = DEPT.deptno
8. [FLIP-115] 增加 Flink SQL 對 Hive 的支持
對于 FileSystem Connector 提供了對 csv/orc/parquet/json/avro 五種格式的支持,以及對 Batch 和 Streaming FileSystem Connector 的完整支持。
提供了對 Hive Streaming Sink 的支持。
9. [FLIP-123] 支持兼容 Hive 的 DDL 和 DML 語句
FLIP-123 提供了對 Hive 方言的支持,它使用戶可以使用 Hive 的 DDL 和 DML 來進行操作。
DataStream API
(注意這部分工作已經完成,但是是否要包括在 1.11 中仍在討論中)
新的 WatermarkAssigner 接口將之前的 AssignerWithPunctuatedWatermarks 和 AssignerWithPeriodicWatermarks 的兩類 Watermark 的接口進行了整合,從而簡化了后續開發支持插入 Watermark 的 Source 實現復雜度。
2. [FLIP-92] 支持超過兩個輸入的 Operator
Flink 1.11 提供了對多輸入 Operator 的支持。但是,目前這一功能并沒有提供完整的 DataStream API 的接口,用戶如果想要使用的話,需要通過手動創建 MultipleInputTransformation 與 MultipleConnectedStreams 的方式進行:
MultipleInputTransformation<Long> transform = new MultipleInputTransformation<>("My Operator",new SumAllInputOperatorFactory(),BasicTypeInfo.LONG_TYPE_INFO,1);env.addOperator(transform.addInput(source1.getTransformation()).addInput(source2.getTransformation()).addInput(source3.getTransformation()));new MultipleConnectedStreams(env).transform(transform).addSink(resultSink);
PyFlink & ML
1. [FLINK-15636] 在 Flink Planner 的 batch 模式下支持 Python UDF 的運行
在此之前,Python UDF 可以運行在 Blink Planner 的流、批和 Flink Planner 的流模式下。支持后,兩個 Planner 的流批模式都支持 Python UDF 的運行。
2. [FLINK-14500] Python UDTF 的支持
UDTF 支持單條寫入多條輸出。兩個 Planner 的流批模式都支持 Python UDTF 的運行。
3. [FLIP-121] 通過 Cython 來優化 Python UDF 的執行效率
用 Cython 優化了 Coder(序列化、反序列化)和 Operation 的計算邏輯,端到端的性能比 1.10 版本提升了數十倍。
4. [FLIP-97] Pandas UDF 的支持
Pandas UDF 以 pandas.Series 作為輸入和輸出類型,支持批量處理數據。一般而言,Pandas UDF 比普通 UDF 的性能要更好,因為減少了 Java 和 Python 進程之間數據交互的序列化和反序列化開銷,同時由于可以批量處理數據,也減少了 Python UDF 調用次數和調用開銷。除此之外,用戶使用 Pandas UDF 時,可以更方便自然地使用 Pandas 相關的 Python 庫。
5. [FLIP-120] 支持 PyFlink Table 和 Pandas DataFrame 之間的轉換
用戶可以使用 Table 對象上的 to_pandas() 方法返回一個對應的 Pandas DataFrame 對象,或通過 from_pandas() 方法將一個 Pandas DataFrame 對象轉換成一個 Table 對象。
import pandas as pdimport numpy as np# Create a PyFlink Tablepdf = pd.DataFrame(np.random.rand(1000, 2))table = t_env.from_pandas(pdf, ["a", "b"]).filter("a > 0.5")# Convert the PyFlink Table to a Pandas DataFramepdf = table.to_pandas()
6. [FLIP-112] 支持在 Python UDF 里定義用戶自定義 Metric
目前支持 4 種自定義的 Metric 類型,包括:Counter, Gauges, Meters 和 Distributions。同時支持定義 Metric 相應的 User Scope 和 User Variables。
7. [FLIP-106][FLIP-114] 在 SQL DDL 和 SQL client 里支持 Python UDF 的使用
在此之前,Python UDF 只能在 Python Table API 里使用。支持 DDL 的方式注冊 Python UDF 后,SQL 用戶也能方便地使用 Python UDF。除此之外,也對 SQL Client 進行了 Python UDF 的支持,支持 Python UDF 注冊及對 Python UDF 的依賴進行管理。
8. [FLIP-96] 支持 Python Pipeline API
Flink 1.9 里引入了一套新的 ML Pipeline API 來增強 Flink ML 的易用性和可擴展性。由于 Python 語言在 ML 領域的廣泛使用,FLIP-96 提供了一套相應的 Python Pipeline API,以方便 Python 用戶。
運行時優化
Flink 現有的 Checkpoint 機制下,每個算子需要等到收到所有上游發送的 Barrier 對齊后才可以進行 Snapshot 并繼續向后發送 barrier。在反壓的情況下,Barrier 從上游算子傳送到下游可能需要很長的時間,從而導致 Checkpoint 超時的問題。
針對這一問題,Flink 1.11 增加了 Unaligned Checkpoint 機制。開啟 Unaligned Checkpoint 后當收到第一個 barrier 時就可以執行 checkpoint,并把上下游之間正在傳輸的數據也作為狀態保存到快照中,這樣 checkpoint 的完成時間大大縮短,不再依賴于算子的處理能力,解決了反壓場景下 checkpoint 長期做不出來的問題。
可以通過 env.getCheckpointConfig().enableUnalignedCheckpoints();開啟unaligned Checkpoint 機制。
2. [FLINK-13417] 支持 Zookeeper 3.5
支持 Flink 與 ZooKeeper 3.5 集成。這將允許用戶使用一些新的 Zookeeper 功能,如 SSL 等。
3. [FLINK-16408] 支持 Slot 級別的 Classloder 復用
Flink 1.11 修改了 TM 端 ClassLoader 的加載邏輯:與之前每次 Failover 后都會創建新的 ClassLoader 不同,1.11 中只要有這個作業占用的 Slot,相應的 ClassLoader 就會被緩存。這一修改對作業 Failover 的語義有一定的影響,因為 Failover 后 Static 字段不會被重新加載,但是它可以避免大量創建 ClassLoader 導致 JVM meta 內存耗盡的問題。
4. [FLINK-15672] 升級日志系統到 log4j 2
Flink 1.11 將日志系統 Log4j 升級到 2.x,從而可以解決 Log4j 1.x 版本存在的一些問題并使用 2.x 的一些新功能。
5. [FLINK-10742] 減少 TM 接收端的數據拷貝次數和內存占用
Flink-1.11 在下游網絡接收數據時,通過復用 Flink 自身的 buffer 內存管理,減少了 netty 層向 Flink buffer 的內存拷貝以及因此帶來的 direct memory 的額外開銷,從而減少了線上作業發生 Direct Memory OOM 或者 Container 因為內存超用被 Kill 的機率。
上述就是小編為大家分享的Apache Flink 1.11 功能有哪些呢了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





