溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關SARIF在應用過程中對深層次需求的實現是怎樣的,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
摘要:為了降低各種分析工具的結果匯總到通用工作流程中的成本和復雜性, 業界開始采用靜態分析結果交換格式(Static Analysis Results Interchange Format (SARIF))來解決這些問題。
目前DevSecOps已經成為構建企業級研發安全的重要模式。靜態掃描工具融入在DevSecOps的開發過程中,對提高產品的整體的安全水平發揮著重要的作用。為了獲取安全檢查能力覆蓋的最大化,開發團隊通常會引入多個安全掃描工具。但這也給開發人員和平臺帶來了更多的問題,為了降低各種分析工具的結果匯總到通用工作流程中的成本和復雜性, 業界開始采用靜態分析結果交換格式(Static Analysis Results Interchange Format (SARIF))來解決這些問題。小編將介紹SARIF在應用過程中對深層次需求的實現。
上次我們說了SARIF的一些基本應用,這里我們再來說下SARIF在更復雜的場景中的一些應用,這樣才能為靜態掃描工具提供一個完整的報告解決方案。
在業界著名的靜態分析工具Coverity最新的2021.03版本中,新增的功能就包括: 支持在GitHub代碼倉中以SARIF格式顯示Coverity的掃描結果。可見Covreity也完成了SARIF格式的適配。
為了避免掃描報告過大,對一些重復使用的信息,需要提取出來,做為元數據。例如:規則、規則的消息,掃描的內容等。
下面的例子中,將規則、規則信息在tool.driver.rules 中進行定義,在掃描結果(results)中直接使用規則編號ruleId來得到規則的信息,同時消息也采用了message.id的方式得到告警信息。 這樣可以避免規則產生同樣告警的大量的重復信息,有效的縮小報告的大小。
vscode 中顯示如下:
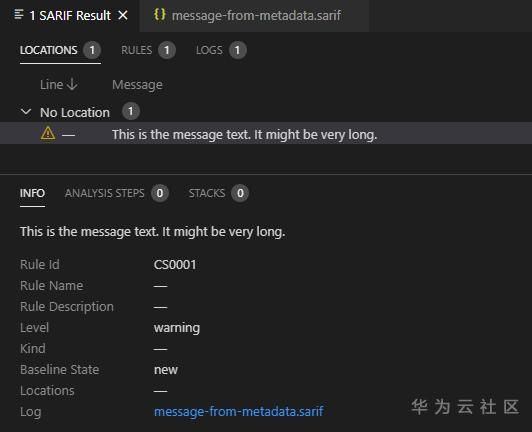
{
"version": "2.1.0",
"runs": [
{
"tool": {
"driver": {
"name": "CodeScanner",
"rules": [
{
"id": "CS0001",
"messageStrings": {
"default": {
"text": "This is the message text. It might be very long."
}
}
}
]
}
},
"results": [
{
"ruleId": "CS0001",
"ruleIndex": 0,
"message": {
"id": "default"
}
}
]
}
]
}掃描結果的告警往往需要,根據具體的代碼問題,在提示消息中給出具體的變量或函數的相關信息,便于用戶對問題的理解。這個時候可以采用消息參數的方式,提供可變動缺陷消息。
下例中,對規則的消息中采用占位符的方式("{0}")提供信息模板,在掃描結果(results)中,通過arguments數組,提供對應的參數。 在vscode中顯示如下:
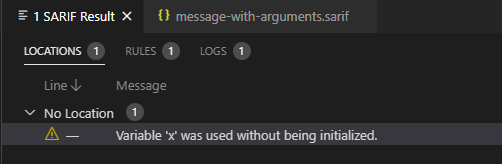
{
"version": "2.1.0",
"runs": [
{
"tool": {
"driver": {
"name": "CodeScanner",
"rules": [
{
"id": "CS0001",
"messageStrings": {
"default": {
"text": "Variable '{0}' was used without being initialized."
}
}
}
]
}
},
"results": [
{
"ruleId": "CS0001",
"ruleIndex": 0,
"message": {
"id": "default",
"arguments": [
"x"
]
}
}
]
}
]
}在有些時候,為了更好的說明這個告警的發生原因,需要給用戶提供更多的參考信息,幫助他們理解問題。比如,給出這個變量的定義位置,污染源的引入點,或者其他輔助信息。
下例中,通過定義問題的發生位置(locations)的關聯位置(relatedLocations)給出了,污染源的引入位置。 在vscode中顯示如下, 但用戶點擊“here”時,工具就可以跳轉到變量expr引入的位置。
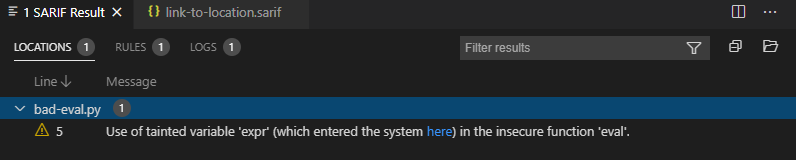
{
"ruleId": "PY2335",
"message": {
"text": "Use of tainted variable 'expr' (which entered the system [here](1)) in the insecure function 'eval'."
},
"locations": [
{
"physicalLocation": {
"artifactLocation": {
"uri": "3-Beyond-basics/bad-eval.py"
},
"region": {
"startLine": 4
}
}
}
],
"relatedLocations": [
{
"id": 1,
"message": {
"text": "The tainted data entered the system here."
},
"physicalLocation": {
"artifactLocation": {
"uri": "3-Beyond-basics/bad-eval.py"
},
"region": {
"startLine": 3
}
}
}
]
}缺陷的分類對于工具和掃描結果的分析是非常重要的。工具可以依托對缺陷的分類進行規則的管理,方便用戶選取需要的規則;另一方面用戶在查看分析報告時,也可以通過對缺陷的分類,快速對分析結果進行過濾。 工具可以參考業界的標準,例如我們常用的Common Weakness Enumeration (CWE), 也可以自定義自己的分類,這些SARIF都提供了支持。
缺陷分類的例子
{
"version": "2.1.0",
"runs": [
{
"taxonomies": [
{
"name": "CWE",
"version": "3.2",
"releaseDateUtc": "2019-01-03",
"guid": "A9282C88-F1FE-4A01-8137-E8D2A037AB82",
"informationUri": "https://cwe.mitre.org/data/published/cwe_v3.2.pdf/",
"downloadUri": "https://cwe.mitre.org/data/xml/cwec_v3.2.xml.zip",
"organization": "MITRE",
"shortDescription": {
"text": "The MITRE Common Weakness Enumeration"
},
"taxa": [
{
"id": "401",
"guid": "10F28368-3A92-4396-A318-75B9743282F6",
"name": "Memory Leak",
"shortDescription": {
"text": "Missing Release of Memory After Effective Lifetime"
},
"defaultConfiguration": {
"level": "warning"
}
}
],
"isComprehensive": false
}
],
"tool": {
"driver": {
"name": "CodeScanner",
"supportedTaxonomies": [
{
"name": "CWE",
"guid": "A9282C88-F1FE-4A01-8137-E8D2A037AB82"
}
],
"rules": [
{
"id": "CA2101",
"shortDescription": {
"text": "Failed to release dynamic memory."
},
"relationships": [
{
"target": {
"id": "401",
"guid": "A9282C88-F1FE-4A01-8137-E8D2A037AB82",
"toolComponent": {
"name": "CWE",
"guid": "10F28368-3A92-4396-A318-75B9743282F6"
}
},
"kinds": [
"superset"
]
}
]
}
]
}
},
"results": [
{
"ruleId": "CA2101",
"message": {
"text": "Memory allocated in variable 'p' was not released."
},
"taxa": [
{
"id": "401",
"guid": "A9282C88-F1FE-4A01-8137-E8D2A037AB82",
"toolComponent": {
"name": "CWE",
"guid": "10F28368-3A92-4396-A318-75B9743282F6"
}
}
]
}
]
}
]
}taxonomies 的定義
"taxonomies": {
"description": "An array of toolComponent objects relevant to a taxonomy in which results are categorized.",
"type": "array",
"minItems": 0,
"uniqueItems": true,
"default": [],
"items": {
"$ref": "#/definitions/toolComponent"
}
},taxonomies節點是個數組節點,可以定義多個分類標準。 同時taxonomies的定義參考定義組節點definitions下的toolComponent的定義。這與我們前面的工具掃描引擎(tool.driver)和工具擴展(tool.extensions)保持了一致. 這樣設計的原因是引擎和結果的強相關性,可以通過這樣的方法使之保持屬性上的一致。
業界標準分類(standard taxonomy)的定義
例子中通過runs.taxonomies節點,聲明了業界的分類標準CWE。 在節點taxonomies中通過屬性節點給出了該規范的描述,下面的只是樣例, 具體的參考SARIF的規范說明:
name: 規范的名字;
version: 版本;
releaseDateUtc: 發布日期;
guid: 唯一標識,便于其他地方引用此規范;
informationUri: 規則的文檔信息;
downloadUri:下載地址;
organization:發布組織
shortDescription:規范的短描述。
taxa是個數組節點,為了縮小報告的尺寸,沒有必要將所有自定義的分類信息都放在taxa節點下面,只需要列出和本次掃描相關的分類信息就夠了。 這也是為什么后面標識是否全面(isComprehensive)節點的默認值是false的原因。
例子中通過taxa節點引入了一個工具需要的分類:CWE-401 內存泄漏,并用guid 和id,做了這個分類的唯一標識,便于后面工具在規則或缺陷中引用這個標識。
工具對象通過tool.driver.supportedTaxonomies節點和定義的業界分類標準關聯。supportedTaxonomies的數組元素是toolComponentReference對象,因為分類法taxonomies本身是toolComponent對象。 toolComponentReference.guid屬性與run.taxonomies []中定義的分類法的對象的guid屬性匹配。
例子中supportedTaxonomies.name:CWE, 它表示此工具支持CWE分類法,并用引用了taxonomies[0]中的guid:A9282C88-F1FE-4A01-8137-E8D2A037AB82,使之與業界分類標準CWE關聯。
規則是在tool.driver.rules節點下定義,rules是個數組節點,規則通過數組元素中的reportingDescriptor對象定義;
每個規則(ReportingDescriptor)中的relationships是個數組元素,每個元素都是一個reportingDescriptorRelationship對象,該對象建立了從該規則到另一個reportingDescriptor對象的關系。關系的目標可以是分類法中的分類單元(如本例中所示),也可以是另一個工具組件中的另一個規則;
關系(ReportingDescriptorRelationship)中的target屬性標識關系的目標,它的值是一個reportingDescriptorReference對象,由此引用對象toolComponent中的reportingDescriptor;
reportingDescriptorReference對象中的toolComponent是一個toolComponentReference對象, 指向工具supportedTaxonomies中定義的分類。
下圖為例子中的規則與缺陷分類的關聯圖:
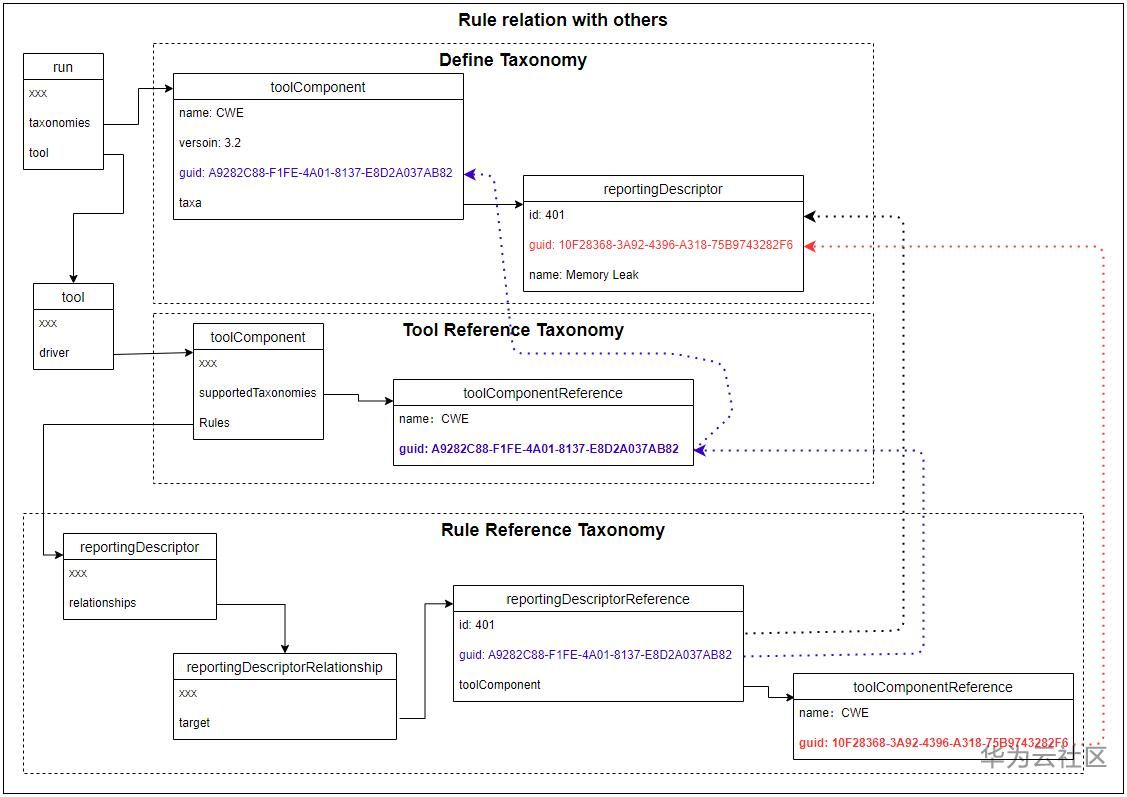
在掃描結果(run.results)中, 每一個結果(result)下,有一個屬性分類(taxa), taxa是一個數組元素,數組中的每個元素指向reportingDescriptorReference對象,用于指定該缺陷的分類。 這個與規則對應分類的方式一樣。從這一點也可以看出,我們可以省略result下的taxa,而是通過規則對應到缺陷的分類。
一些工具通過模擬程序的執行來檢測問題,有時跨多個執行線程。 SARIF通過一組位置信息模擬執行過程,像代碼流(Code Flow)一樣。 SARIF代碼流包含一個或多個線程流,每個線程流描述了單個執行線程上按時間順序排列的代碼位置。
由于缺陷中,可能存在不止一個代碼流,因此可選的result.codeFlows屬性是一個數組形式的codeFlow對象。
"result": {
"description": "A result produced by an analysis tool.",
"additionalProperties": false,
"type": "object",
"properties": {
... ...
"codeFlows": {
"description": "An array of 'codeFlow' objects relevant to the result.",
"type": "array",
"minItems": 0,
"uniqueItems": false,
"default": [],
"items": {
"$ref": "#/definitions/codeFlow"
}
},
}
}codeFlow的定義可以看到,每個代碼流有,由一個線程組(threadFlows)構成,且線程組(threadFlows)是必須的。
"codeFlow": {
"description": "A set of threadFlows which together describe a pattern of code execution relevant to detecting a result.",
"additionalProperties": false,
"type": "object",
"properties": {
"message": {
"description": "A message relevant to the code flow.",
"$ref": "#/definitions/message"
},
"threadFlows": {
"description": "An array of one or more unique threadFlow objects, each of which describes the progress of a program through a thread of execution.",
"type": "array",
"minItems": 1,
"uniqueItems": false,
"items": {
"$ref": "#/definitions/threadFlow"
}
},
},
"required": [ "threadFlows" ]
},在每個線程流(threadFlow)中,一個數組形式的位置組(locations)來描述工具對代碼的分析過程。
線程流(threadFlow)定義:
"threadFlow": {
"description": "Describes a sequence of code locations that specify a path through a single thread of execution such as an operating system or fiber.",
"type": "object",
"additionalProperties": false,
"properties": {
"id": {
...
"message": {
...
"initialState": {
...
"immutableState": {
...
"locations": {
"description": "A temporally ordered array of 'threadFlowLocation' objects, each of which describes a location visited by the tool while producing the result.",
"type": "array",
"minItems": 1,
"uniqueItems": false,
"items": {
"$ref": "#/definitions/threadFlowLocation"
}
},
"properties": {
...
},
"required": [ "locations" ]
},線程流位置(threadFlowLocation)定義:
位置組(locations)中的每個元素, 又是通過threadFlowLocation來表示工具的對代碼位置的訪問。 最終通過location類型的location屬性給出分析的位置信息。location可以包含物理和邏輯位置信息,因此codeFlow也可以用于二進制的分析流的表示。
在threadFlowLocation還有一個state屬性的節點,我們可以通過它來存儲變量、表達式的值或者符號表信息,或者用于狀態機的表述。
"threadFlowLocation": {
"description": "A location visited by an analysis tool while simulating or monitoring the execution of a program.",
"additionalProperties": false,
"type": "object",
"properties": {
"index": {
"description": "The index within the run threadFlowLocations array.",
...
"location": {
"description": "The code location.",
"$ref": "#/definitions/location"
},
"state": {
"description": "A dictionary, each of whose keys specifies a variable or expression, the associated value of which represents the variable or expression value. For an annotation of kind 'continuation', for example, this dictionary might hold the current assumed values of a set of global variables.",
"type": "object",
"additionalProperties": {
"$ref": "#/definitions/multiformatMessageString"
}
},
...
}
},參考代碼
1. # 3-Beyond-basics/bad-eval-with-code-flow.py
2.
3. print("Hello, world!")
4. expr = input("Expression> ")
5. use_input(expr)
6.
7. def use_input(raw_input):
8. print(eval(raw_input))上面是一個python代碼的代碼注入的一個案例。
在第四行,輸入信息賦值給變量expr;
在第五行,變量expr通過函數use_input的第一個參數,進入到函數use_input;
在第八行,通過函數print打印輸入結果,但這里使用了函數eval()對輸入參數進行了處理,由于參數在輸入后,未經過檢驗,就直接用于函數eval的處理, 這里可能會引入代碼注入的安全問題。
這個分析過程可以通過下面的掃描結果表現出來,便于用戶理解問題的發生過程。
掃描結果
{
"version": "2.1.0",
"runs": [
{
"tool": {
"driver": {
"name": "PythonScanner"
}
},
"results": [
{
"ruleId": "PY2335",
"message": {
"text": "Use of tainted variable 'raw_input' in the insecure function 'eval'."
},
"locations": [
{
"physicalLocation": {
"artifactLocation": {
"uri": "3-Beyond-basics/bad-eval-with-code-flow.py"
},
"region": {
"startLine": 8
}
}
}
],
"codeFlows": [
{
"message": {
"text": "Tracing the path from user input to insecure usage."
},
"threadFlows": [
{
"locations": [
{
"message": {
"text": "The tainted data enters the system here."
},
"location": {
"physicalLocation": {
"artifactLocation": {
"uri": "3-Beyond-basics/bad-eval-with-code-flow.py"
},
"region": {
"startLine": 4
}
}
},
"state": {
"expr": {
"text": "42"
}
},
"nestingLevel": 0
},
{
"message": {
"text": "The tainted data is used insecurely here."
},
"location": {
"physicalLocation": {
"artifactLocation": {
"uri": "3-Beyond-basics/bad-eval-with-code-flow.py"
},
"region": {
"startLine": 8
}
}
},
"state": {
"raw_input": {
"text": "42"
}
},
"nestingLevel": 1
}
]
}
]
}
]
}
]
}
]
}這里只是一個簡單的示例,通過SARIF的codeFLow,我們可以適應更加復雜的分析過程,從而讓用戶更好的理解問題,進而快速做出判斷和修改。
在大型軟件項目中,分析工具一次就可以產生成千上萬個結果。為了處理如此多的結果,在缺陷管理上,我們需要記錄現有缺陷,制定一個掃描基線,然后對現有問題進行處理。同時在后期的掃描中,需要將新的掃描結果與基線進行比較,以區分是否有新問題的引入。為了確定后續運行的結果在邏輯上是否與基線的結果相同,必須通過一種算法:使用缺陷結果中包含的特有信息來構造一個穩定的標識,我們將此標識稱為指紋。使用這個指紋來標識這個缺陷的特征以區別于其他缺陷,我們也稱這個指紋為這個缺陷的缺陷指紋。
缺陷指紋應該包含相對穩定不變的缺陷信息:
產生結果的工具的名稱;
規則編號;
分析目標的文件系統路徑;這個路徑應該是工程本身具有的相對路徑。不應該包含路徑前面工程存放位置信息,因為每臺機器存放工程的位置可能不同;
缺陷特征值(partialFingerprints)。
SARIF的每個掃描結果(result)中提供了一組這樣的屬性節點,用于缺陷指紋的存放,便于缺陷的管理系統通過這些標識,識別缺陷的唯一性。
"result": {
"description": "A result produced by an analysis tool.",
"additionalProperties": false,
"type": "object",
"properties": {
... ...
"guid": {
"description": "A stable, unique identifier for the result in the form of a GUID.",
"type": "string",
"pattern": "^[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[1-5][0-9a-fA-F]{3}-[89abAB][0-9a-fA-F]{3}-[0-9a-fA-F]{12}$"
},
"correlationGuid": {
"description": "A stable, unique identifier for the equivalence class of logically identical results to which this result belongs, in the form of a GUID.",
"type": "string",
"pattern": "^[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[1-5][0-9a-fA-F]{3}-[89abAB][0-9a-fA-F]{3}-[0-9a-fA-F]{12}$"
},
"occurrenceCount": {
"description": "A positive integer specifying the number of times this logically unique result was observed in this run.",
"type": "integer",
"minimum": 1
},
"partialFingerprints": {
"description": "A set of strings that contribute to the stable, unique identity of the result.",
"type": "object",
"additionalProperties": {
"type": "string"
}
},
"fingerprints": {
"description": "A set of strings each of which individually defines a stable, unique identity for the result.",
"type": "object",
"additionalProperties": {
"type": "string"
}
},
... ...
}
}只通過缺陷的固有的信息特征,在某些情況下,不容易得到唯一識別結果的信息。這個時候我們需要增加一些與這個缺陷強相關的一些屬性值,做為附加信息來加入到缺陷指紋的計算中,使最后的計算得到的指紋唯一。這個有些像我們做加密算法時的鹽值,只是這個鹽值需要保證生成的唯一值具有可重復性,以確保下次掃描時,對于同一缺陷能夠得到相同的輸入值,從而得到和上次一樣的指紋。例如,工具在檢查文檔中是否存在敏感性的單詞,告警信息為:“ xxx不應在文檔中使用。”,這個時候就可以使用這個單詞作為這個缺陷的一個特征值。
SARIF格式就提供了這樣一個partialFingerprints屬性,用于保存這個特征值,以允許SARIF生態系統中的分析工具和其他組件使用這個信息。缺陷管理系統可以將其附加到為每個結果構造的指紋中。前面的例子中,該工具就可以會將partialFingerprints對象中的屬性的值設置為:禁止的單詞。缺陷管理系統應該在其指紋計算中將信息包括在partialFingerprints中。
對于partialFingerprints,應該只添加和缺陷特征強相關的屬性,而且屬性的值應該相對穩定。 比如,缺陷發生的代碼行號就不適合加入到指紋的的邏輯運算中,因為代碼行是一個會經常變動的值,在下次掃描的時候,很可能因為開發人員在問題行前添加或刪除了一些代碼行,而使同樣的問題在新的掃描報告中得到不一樣的代碼行,從而影響缺陷指紋的計算值,導致比對時發生差異。
盡管我們試圖為每個缺陷找到唯一的標識特征,還加入了一些可變的特征屬性,但還是很難設計出一種算法來構造一個真正穩定的指紋結果。比如剛才的例子,如果同一個文件中存在幾個同樣的敏感字,我們這個時后還是無法為每一個告警缺陷給出一個唯一的標識。當然這個時候還可以加入函數名作為一個指紋的計算因子,因為函數名在一個程序中是相對穩定的存在,函數名的加入有助于區分同一個文件中同一個問題的出現范圍,但還是會存在同一個函數內同樣問題的多個相同缺陷。 所以盡管我們盡量區分每一個告警, 但缺陷指紋相同的場景在實際的掃描中還是會存在的。
幸運的是,出于實際目的,指紋并不一定要絕對穩定。它只需要足夠穩定,就可以將錯誤報告為“新”的結果數量減少到足夠低的水平,以使開發團隊可以無需過多努力就可以管理錯誤報告的結果。
SARIF給出了靜態掃描工具的標準輸出的通用格式,能夠滿足靜態掃描工具報告輸出的各種要求;
對于各種靜態掃描工具整合到DevSecOps平臺,SARIF將降低掃描結果匯總到通用工作流程中的成本和復雜性;
SARIF也將為IDE整合各種掃描結果,提供統一的缺陷處理模塊提供了可能;掃描結果在IDE中的缺陷展示、修復等,這樣可以讓工具的開發商專注于問題的發現,而減少對各種IDE的適配的工作量;
SARIF已經成為OASIS的標準之一,并被微軟、GrammaTech等重要靜態掃描工具廠商在工具中提供支持;同時U.S. DHS, U.S. NIST在一些靜態檢查工具的評估和比賽中,也要求提供掃描報告的格式采用SARIF;
SARIF雖然目前主要是為靜態掃描工具的結果設計的,但由于其設計的通用性,一些動態分析工具廠商也給出了SARIF的成功應用。
關于SARIF在應用過程中對深層次需求的實現是怎樣的就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





