溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Redis中的BloomFilter簡介及使用方法”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Redis中的BloomFilter簡介及使用方法”吧!
介紹以及場景使用
BloomFilter 中文名就是 布隆過濾器,作為過濾器,有沒有感覺很像 LOL 中布隆的 E技能(堅不可摧) ?
布隆過濾器是一個叫 布隆 的人提出來的,它是通過一個 大型位數組和幾個不同的hash函數 來實現的,我們可以把布隆過濾器理解為一個 不精確的set 。我們都知道 set 可以去重,使用 set 可以幫我們判斷集合中是否已經存在某些元素并且或者幫我們實現去重功能。
但是,set 提供精確的去重功能的同時也給我們帶來了一個更大的問題——空間消耗。
比如這個時候我們進行網頁爬蟲,需要對爬過的 url 進行去重以避免爬到已經爬過的網站,如果我們使用 set 那么也就意味著我們需要將所有爬過的 url 放入集合中,假設一個 url 64字節,那么一億個 url 意味著我們需要占用 6GB,十億就是 60GB 左右。
請注意,是內存。
比如這個時候我們要進行垃圾郵件或者垃圾短信的過濾,我們需要從數十億個垃圾郵件列表或者垃圾電話列表中進行判斷此時的郵件或者短信是否是垃圾的。如果我們此時使用 set 那么占用空間不用我多說了,也是 百GB級別 的。
上面的面試中我提到了 緩存穿透 ,用戶故意請求數據庫本來就不存在的(比如ID = -1),這個時候如果不做處理那么肯定會穿透緩存去查詢數據庫,一個查詢還好,如果幾千,幾萬個同時進來呢?你的數據庫頂得住嗎?那么此時我們使用 set 進行處理,占用那么多內存空間,你覺得值得嗎???或者說,還有沒有更好的方法了?
上面所講的三個典型場景,網站去重,垃圾郵件過濾,緩存穿透 ,這三個只要使用 BloomFilter 就能完美解決。
你有沒有發現,上面三個場景其實對精度要求都不是很高,尤其是垃圾郵件過濾,其實偶爾收到幾個垃圾郵件也無所謂的。像緩存穿透,也正好符合了 BloomFilter 的一個特性 他說有的不一定有,他說沒有的肯定沒有,我說你這個 ID 在數據庫不存在那就真的不存在,老子把你過濾了就是這么自信,怎么,你打我???
聊了這么久的概念和應用場景,是不是還對 BloomFilter 怎么能進行去重的還是一臉懵逼? 下面我們就聊一聊 BloomFilter 的實現原理。首先給大家放一張結構圖。
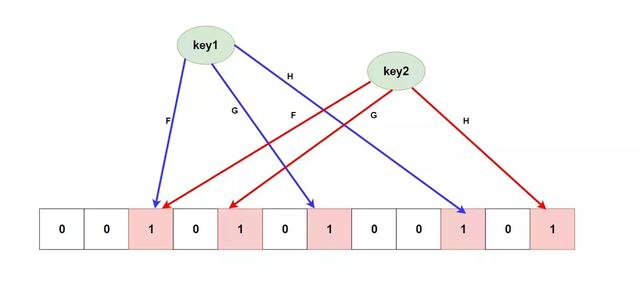
其中 F、G、H 是幾種 無偏 Hash 函數,底下是一個 大型的位數組,當我們向 BloomFilter 添加數據的時候,它首先會將我們的數據(key)做幾次hash運算(這里就是FGH),每個hash運算都會得到一個不用的位數組索引下標,此時我們就將算出的幾個下標的位置的值改成1就行。如果判斷元素是否存在,只要 判斷所在的所有索引下標的值都是1 就行了。
其實你也發現了,在 BloomFilter 中會出現不同key所算出的下標重復了,如上圖所示,這就是誤差的來源( 你可以配置初始大小和錯誤率來控制誤差 )也是他說有的不一定有,他說沒有的肯定沒有 這一特性的根本原因,因為如果全是0或者存在0那么肯定不存在,如果全是1也有可能是別的幾個key給放進去的1。
因為 BloomFilter 是 Redis 的擴展模塊,所以需要額外下載,你可以使用 Docker 進行拉取。安裝步驟我不做詳細解釋,你可以到它的github上學習怎么安裝
安裝完之后我們就可以愉快的使用啦。
bf.add key element 添加
bf.exists key element 判斷是否存在
bf.madd key element1 element2 ... 批量添加
bf.mexists key element1 element2 ... 批量判斷
命令很簡單,你可以自己去嘗試。
介紹以及場景使用
在 Redis 中還有一個會存在誤差的數據結構 HyperLogLog。
我們首先思考一個場景,當老板讓我們計算頁面的 UV 我們該怎么辦?
如果訪問量不大使用 set 進行用戶去重完全可以,但是訪問量如果有幾百萬,幾千萬,那么就會又遇到上面提到的 浪費空間 的問題。如果我們這個時候有一個能 進行去重且能進行計數的數據結構就好了。
這個時候 HyperLogLog 就閃亮登場了!它能提供不精確的去重計數方案(誤差值在 0.81% 左右),不精確就不精確哇,UV 要你多精確?0.81%我們也能接受。最重要的是 HyperLogLog 只占用 12KB 的內存。
使用方法和場景實踐
pfadd key element 添加
pfcount key 計算
pfmerge destkey sourcekey1 sourcekey2 ... 合并
命令都是 pf 開頭是因為這是一個名叫 Philippe Flajolet 的教授發明的。
可以看到就這三個基本命令,很簡單很容易掌握。那我們來動手實踐一下吧。

介紹和使用場景
首先我們再來思考一個比較有意思的場景,老板想讓你統計一年內多個用戶之間他們同時在線的天數,這個時候你怎么辦?
你可能會想到使用 hash 存儲,這太浪費空間了,有沒有更好的辦法呢?答案是有的,Redis 中使用了 bitmap位圖。

我們知道,字符串中一個字符是使用8個比特來表示的(如上圖),在 Redis 中 bitmap 底層就是 string,也可以說 string 底層就是 bitmap。
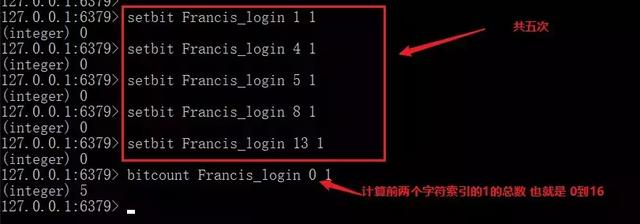
如果有了這個我們是不是可以用來計算一個用戶在指定時間內簽到的次數?也就是一個位置代表一天,0代表未簽到,1代表簽到,在上圖中,該用戶在八天內簽到了四次。
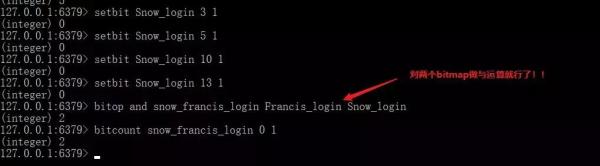
Redis 中的 bitmap 還提供了多個 bitmap 進行與,或,異或運算的命令,當然還有單個 bitmap 的 非 運算。這是不是給你提供了一點思路對于我們一開始的需求呢?
setbit key index 0/1 設置某位的值
getbit key index 獲取某位的值
bitcount key start end 獲取指定范圍內為1的數量
需要注意的是,這里的start 和 end是指的字符位置不是比特位置!!!包括下面的 bitpos 也是
bitpos key bit start end 獲取第一個值為bit的從start到end字符索引范圍的位置
bitop and/or/xor/not destkey key1 key2 對多個 bitmap 進行邏輯運算。
對于bitmap還有一個好玩的指令就是 bitfield ,這里我不做過多介紹,感興趣的同學自己可以了解一下。
我們首先來實現一下統計用戶簽到次數的功能。
還記得我們一開始的問題嗎?統計一年內多個用戶之間他們同時在線的天數,我們有了 bitmap 還怕什么。
介紹和場景運用
GeoHash 常用來計算 附近的人,附近的商店。
試想一下如果我們使用 關系數據庫 來存儲某個元素的地址 (id,經度,緯度) 。這個時候我們該如何計算附近的人?難道我們要遍歷所有元素位置并做距離計算?這顯然不可能。
當然你可以使用劃分區域并使用 SQL 語句圈出區域,然后建立 雙向復合索引 來提升性能,但是數據庫的并發能力畢竟有限,我們能不能使用 Redis 來做呢?
答案是可以的,Redis 中使用了 GeoHash 提供了很好的解決方案。具體原理是將地球看成一個平面,并把二維坐標映射成一維(精度損失的原因)。如果對其中的算法感興趣你可以自己額外去了解,篇幅有限不做過多說明。
基本命令和使用實戰
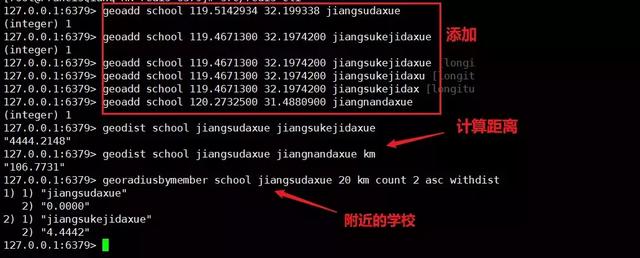
geoadd key longitude latitude element(后面可配置多個三元組) 添加元素
geodist key element1 element2 unit 計算兩個元素的距離
geopos key element [element] 獲取元素的位置
geohash key element 獲取元素hash
georadiusbymember key element distanceValue unit count countValue ASC/DESC [withdist] [withhash] [withcoord] 獲取元素附近的元素 可附加后面選項[距離][hash][坐標]
georadius key longitude latitude distanceValue unit count countValue ASC/DESC [withdist] [withhash] [withcoord] 和上面一樣只是元素改成了指定坐標值
到此,相信大家對“Redis中的BloomFilter簡介及使用方法”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





