溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關HBase中BloomFilter是什么的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
先簡單的介紹下Bloom Filter(布隆過濾器)是1970年由布隆提出的。它實際上是一個很長的二進制向量和一系列隨機映射函數。布隆過濾器可以用于檢索一個元素是否在一個集合中。它的優點是空間效率和查詢時間都遠遠超過一般的算法,缺點是有一定的誤識別率和刪除困難。
在計算機科學中,我們常常會碰到時間換空間或者空間換時間的情況,即為了達到某一個方面的最優而犧牲另一個方面。Bloom Filter在時間空間這兩個因素之外又引入了另一個因素:錯誤率。在使用Bloom Filter判斷一個元素是否屬于某個集合時,會有一定的錯誤率。也就是說,有可能把不屬于這個集合的元素誤認為屬于這個集合(False Positive),但不會把屬于這個集合的元素誤認為不屬于這個集合(False Negative)。在增加了錯誤率這個因素之后,Bloom Filter通過允許少量的錯誤來節省大量的存儲空間。簡單地說就是寧可放過也不殺錯。
它的用法其實是很容易理解的,我們拿個HBase中應用的例子來說下,我們已經知道rowKey存放在HFile中,那么為了從一系列的HFile中查詢某個rowkey,我們就可以通過 Bloom Filter 快速判斷 rowkey 是否在這個HFile中,從而過濾掉大部分的HFile,減少需要掃描的Block。
BloomFilter對于HBase的隨機讀性能至關重要,對于get操作以及部分scan操作可以剔除掉不會用到的HFile文件,減少實際IO次數,提高隨機讀性能。在此簡單地介紹一下Bloom Filter的工作原理,Bloom Filter使用位數組來實現過濾,初始狀態下位數組每一位都為0,如下圖所示:

假如此時有一個集合S = {x1, x2, … xn},Bloom Filter使用k個獨立的hash函數,分別將集合中的每一個元素映射到{1,…,m}的范圍。對于任何一個元素,被映射到的數字作為對應的位數組的索引,該位會被置為1。比如元素x1被hash函數映射到數字8,那么位數組的第8位就會被置為1。下圖中集合S只有兩個元素x和y,分別被3個hash函數進行映射,映射到的位置分別為(0,3,6)和(4,7,10),對應的位會被置為1:
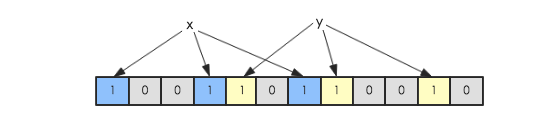
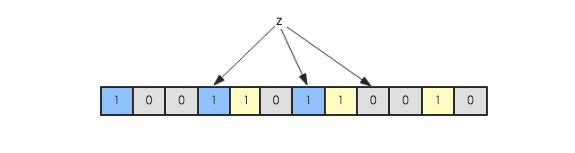
現在假如要判斷另一個元素是否是在此集合中,只需要被這3個hash函數進行映射,查看對應的位置是否有0存在,如果有的話,表示此元素肯定不存在于這個集合,否則有可能存在。下圖所示就表示z肯定不在集合{x,y}中:
從上面的內容我們可以得知,Bloom Filter有兩個很重要的參數
哈希函數個數
位數組的大小
我們來理一下 HFile 中和 Bloom Filter 相關的Block,
Scanned Block Section(掃描HFile時被讀取):Bloom Block
Load-on-open-section(regionServer啟動時加載到內存):BloomFilter Meta Block、Bloom Index Block
Bloom Block:Bloom數據塊,存儲Bloom的位數組
Bloom Index Block:Bloom數據塊的索引
BloomFilter Meta Block:從HFile角度看bloom數據塊的一些元數據信息,大小個數等等。
HBase中每個HFile都有對應的位數組,KeyValue在寫入HFile時會先經過幾個hash函數的映射,映射后將對應的數組位改為1,get請求進來之后再進行hash映射,如果在對應數組位上存在0,說明該get請求查詢的數據不在該HFile中。
HFile中的Bloom Block中存儲的就是上面說得位數組,當HFile很大時,Data Block 就會很多,同時KeyValue也會很多,需要映射入位數組的rowKey也會很多,所以為了保證準確率,位數組就會相應越大,那Bloom Block也會越大,為了解決這個問題就出現了Bloom Index Block,作用和 Data Index Block 類似,一個HFile中有多個Bloom Block(位數組),根據rowKey拆分,一部分連續的Key使用一個位數組。這樣查詢rowKey就要先經過Bloom Index Block(在內存中)定位到Bloom Block,再把Bloom Block加載到內存,進行過濾。
謂詞下推
1.Bloom Filter 在小表處生成;
2.廣播到大表處;
3.大表根據 Bloom Filter 進行過濾;
4.剩下的數據傳入 JoinNode 進行關聯。
注意:Bloom Filter 處理 join 并不是總是有效地,如果JOIN兩邊的表并不能過濾到很多數據,例如左表和右表中Join鍵的差集并不大,這種情況下反而浪費了資源計算Bloom Filter和應用Bloom Filter
Google Guava library為我們提供了Bloom Filter的實現,直接用就可以啦:com.google.common.hash.BloomFilter
private final BloomFilter<String> bloomFilter = BloomFilter.create(new Funnel<String>() {
private static final long serialVersionUID = 1L;
@Override
public void funnel(String arg0, PrimitiveSink arg1) {
arg1.putString(arg0, Charsets.UTF_8);
}
}, 1024*1024*32);
public synchronized boolean contains(String id){
if(StringUtils.isEmpty(id)){
return true;
}
boolean exists = bloomFilter.mightContain(id); //布隆過濾器是否包含這個id
if(!exists){
bloomFilter.put(id); //添加進布隆過濾器
}
return exists;
}感謝各位的閱讀!關于“HBase中BloomFilter是什么”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





