溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何用python代碼爬取全國所有必勝客餐廳信息,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
當我剛接觸 Python 時,我已經被 Python 深深所吸引。Python 吸引我的地方不僅僅能用其編寫網絡爬蟲,而且能用于數據分析。我能將大量的數據中以圖形化方式呈現出來,更加直觀的解讀數據。
數據分析的前提是有數據可分析。如果沒有數據怎么辦?一是可以去一些數據網站下載相關的數據,不過數據內容可能不是自己想要的。二是自己爬取一些網站數據。
今天,我就爬取全國各地所有的必勝客餐廳信息,以便后續做數據分析。
01抓取目標
我們要爬取的目標是必勝客中國。打開必勝客中國首頁,進入“餐廳查詢”頁面。
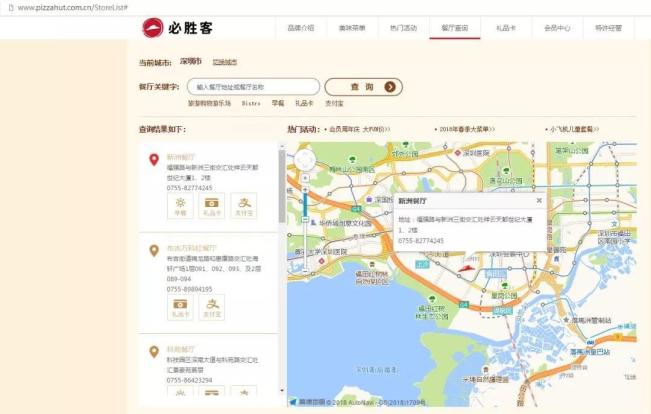
我們要爬取的數據內容有城市、餐廳名字、餐廳地址以及餐廳聯系電話。因為我看到頁面中有地圖,所以頁面一定有餐廳地址的經緯度。因此,餐廳的經緯度也是我們需要爬取的數據。
至于全國有必勝客餐廳的城市列表,我們可以通過頁面的“切換城市”獲取。
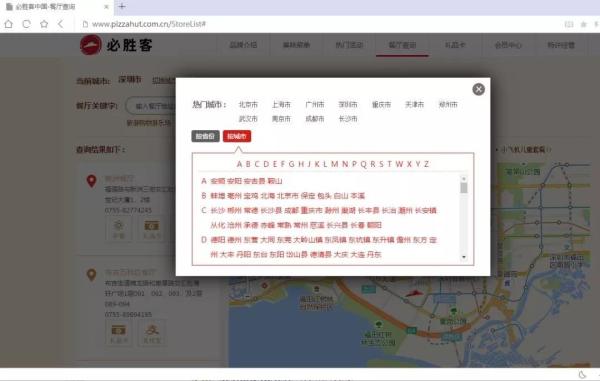
02分析目頁面
在編寫爬蟲程序之前,我都是先對頁面進行簡單分析,然后指定爬取思路。而且對頁面結構進行分析往往會有一些意想不到的收獲。
我們使用瀏覽器的開發者工具對頁面結構進行簡單分析。
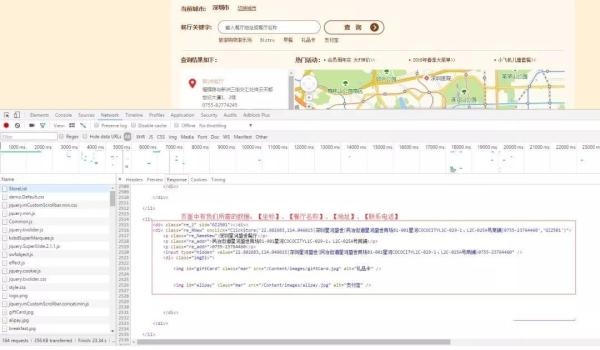
我們在 StoreList 頁面中能找到我們所需的數據。這個能確定數據提取的 Xpath 語法。
StoreList 頁面的 Response 內容比較長。我們先不著急關閉頁面,往下看看,找找看是否有其他可利用的內容。***,我們找到調用獲取餐廳列表信息的 JavaScript 函數代碼。
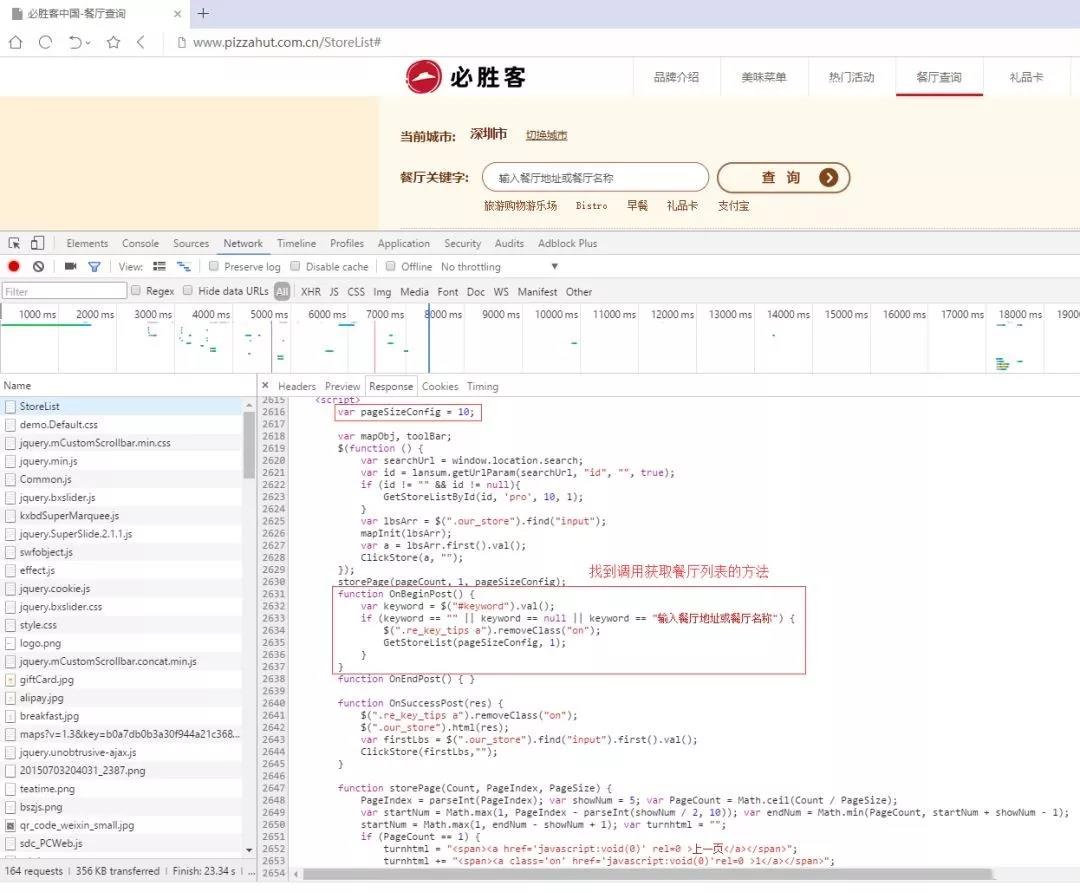
我們接著搜索下GetStoreList函數,看看瀏覽器如何獲取餐廳列表信息的。
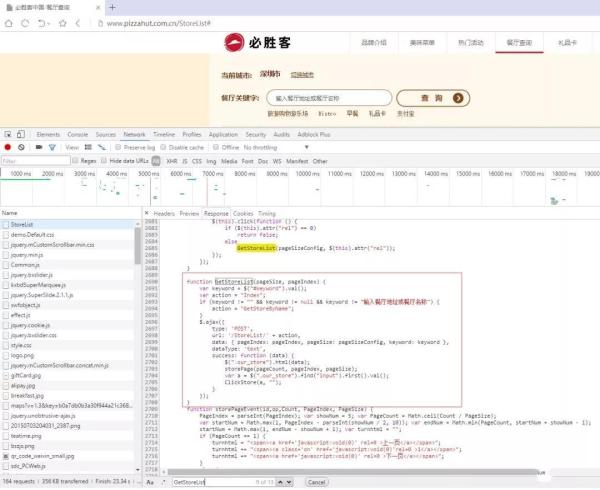
從代碼中,我們可以了解到頁面使用 Ajax 方式來獲取數據。頁面以 POST 方式請求地址http://www.pizzahut.com.cn/StoreList/Index。同時,請求還攜帶參數 pageIndex 和 pageSize。
03爬取思路
經過一番頁面結構分析之后,我們指定爬取思路。首先,我們先獲取城市信息。然后將其作為參數,構建 HTTP 請求訪問必勝客服務器來獲取當前城市中所有餐廳數據。
為了方便數據爬取,我將所有城市全部寫入到 cities.txt 中。等要爬取數據時,我們再從文件中讀取城市信息。
爬取思路看起來沒有錯,但是還是有個難題沒有搞定。我們每次打開必勝客的官網,頁面每次都會自動定位到我們所在的城市。如果無法破解城市定位問題,我們只能抓取一個城市數據。
于是乎,我們再次瀏覽首頁,看看能不能找到一些可用的信息。最終,我們發現頁面的 cookies 中有個 iplocation 字段。我將其進行 Url 解碼,得到 深圳|0|0 這樣的信息。
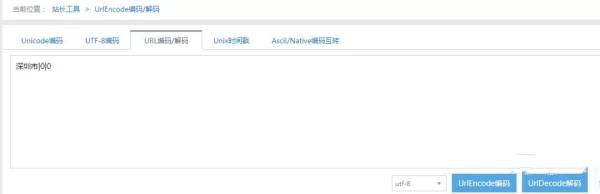
看到這信息,我恍然大悟。原來必勝客網站根據我們的 IP 地址來設置初始城市信息。如果我們能偽造出 iplocation 字段信息,那就可以隨便修改城市了。
04代碼實現
***步是從文件中讀取城市信息。
# 全國有必勝客餐廳的城市, 我將城市放到文件中, 一共 380 個城市 cities = [] def get_cities(): """ 從文件中獲取城市 """ file_name = 'cities.txt' with open(file_name, 'r', encoding='UTF-8-sig') as file: for line in file: city = line.replace(' ', '') cities.append(city)第二步是依次遍歷 cities 列表,將每個城市作為參數,構造 Cookies 的 iplocation 字段。
# 依次遍歷所有城市的餐廳 for city in cities: restaurants = get_stores(city, count) results[city] = restaurants count += 1 time.sleep(2)
然后,我們再以 POST 方式攜帶 Cookie 去請求必勝客服務器。***再對返回頁面數據進行提取。
def get_stores(city, count): """ 根據城市獲取餐廳信息 """ session = requests.Session() # 對【城市|0|0】進行 Url 編碼 city_urlencode = quote(city + '|0|0') # 用來存儲首頁的 cookies cookies = requests.cookies.RequestsCookieJar() headers = { 'User-agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.3964.2 Safari/537.36', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Host': 'www.pizzahut.com.cn', 'Cache-Control': 'max-age=0', 'Connection': 'keep-alive', } print('============第', count, '個城市:', city, '============') resp_from_index = session.get('http://www.pizzahut.com.cn/', headers=headers) # print(resp_from_index.cookies) # 然后將原來 cookies 的 iplocation 字段,設置自己想要抓取城市。 cookies.set('AlteonP', resp_from_index.cookies['AlteonP'], domain='www.pizzahut.com.cn') cookies.set('iplocation', city_urlencode, domain='www.pizzahut.com.cn') # print(cookies) page = 1 restaurants = [] while True: data = { 'pageIndex': page, 'pageSize': "50", } response = session.post('http://www.pizzahut.com.cn/StoreList/Index', headers=headers, data=data, cookies=cookies) html = etree.HTML(response.text) # 獲取餐廳列表所在的 div 標簽 divs = html.xpath("//div[@class='re_RNew']") temp_items = [] for div in divs: item = {} content = div.xpath('./@onclick')[0] # ClickStore('22.538912,114.09803|城市廣場|深南中路中信城市廣場二樓|0755-25942012','GZH519') # 過濾掉括號和后面的內容 content = content.split('('')[1].split(')')[0].split('','')[0] if len(content.split('|')) == 4: item['coordinate'] = content.split('|')[0] item['restaurant_name'] = content.split('|')[1] + '餐廳' item['address'] = content.split('|')[2] item['phone'] = content.split('|')[3] else: item['restaurant_name'] = content.split('|')[0] + '餐廳' item['address'] = content.split('|')[1] item['phone'] = content.split('|')[2] print(item) temp_items.append(item) if not temp_items: break restaurants += temp_items page += 1 time.sleep(5) return restaurants第三步是將城市以及城市所有餐廳信息等數據寫到 Json 文件中。
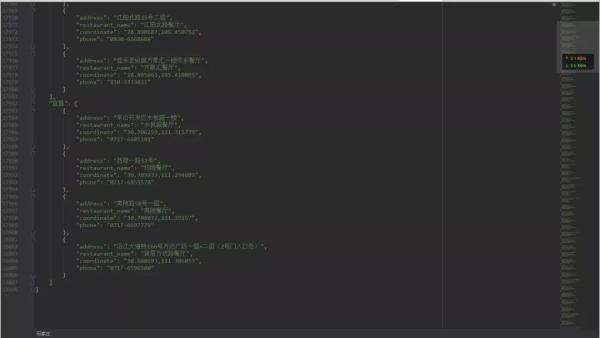
with open('results.json', 'w', encoding='UTF-8') as file: file.write(json.dumps(results, indent=4, ensure_ascii=False))05爬取結果
程序運行完之后, 就會在當前目錄下生成一個名為「results.json」文件。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





