溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何用Python爬取酷我音樂,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
前兩天聽了一下酷我音樂官網的音樂,覺得上面的音樂還不錯,想把他們爬取得到。開始,完全沒有頭緒,但是,最后有了實現它的思路,那就是通過兩個json文件最終得到想聽的音樂。

實現這個過程的主要模塊有requests、json、urllib.request、urllib.parse,其中requests模塊用于請求得到相應的數據(這里是得到json數據),json模塊用于對得到的json數據進行處理(將json數據轉換成字典,主要使用json.loads()方法),urllib.request(使用其urlretrieve()方法,用于下載音樂),urllib.parse(使用其quote()方法,用于對輸入的字符串進行編碼)。
首先,我們需要來到酷我音樂的官網(http://www.kuwo.cn/),在輸入框中輸入關鍵字,小編輸入的是:破繭然后回車,可以得到搜索相應的歌曲列表,然而這些數據都是動態加載的,使用requests模塊如果直接請求這個網址,根本不可能得到這些數據,這個時候我們可以按電腦鍵盤F12,來到開發者模式,點擊Network下面的XHR,找到這些歌曲列表的那個網址,具體為: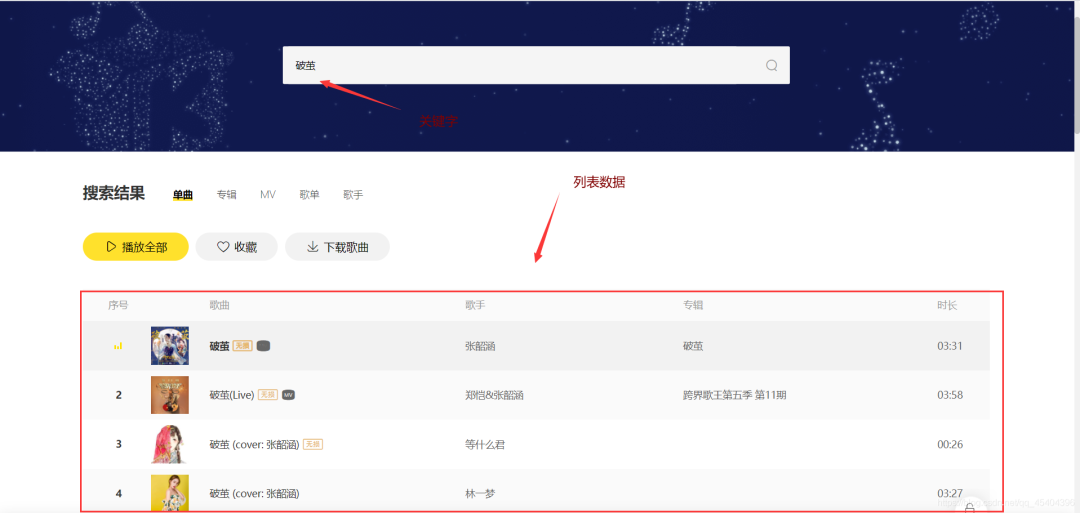
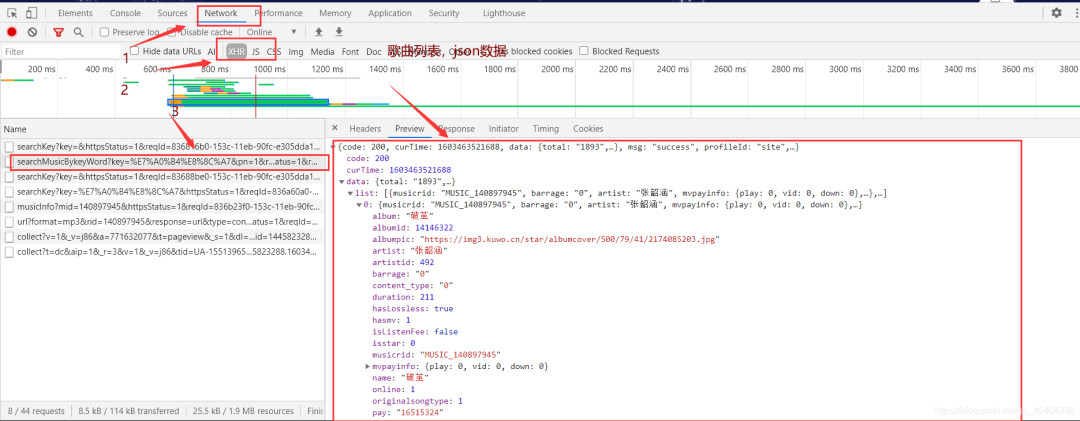
我們需要得到這些歌曲中相應的數據如下: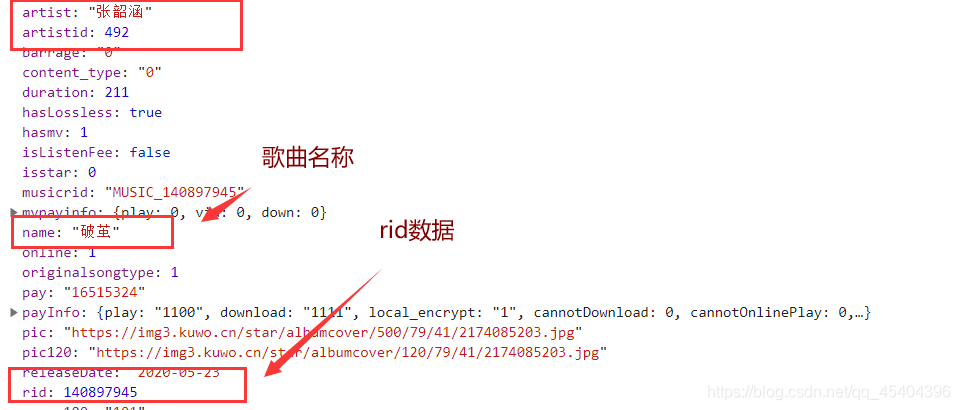
其中name和artist關鍵字對應的值為展示用和最終.mp3文件名稱,rid關鍵字對應的值是為后面過程所用。
當然,訪問這個網址不是很簡單的,需要添加請求頭。參考代碼如下:
musicName=input('請輸入歌曲名稱:')
encodName=quote(musicName)
url='https://www.kuwo.cn/api/www/search/searchMusicBykeyWord?key={}&pn=1&rn=30&httpsStatus=1'.format(encodName)
referer='https://www.kuwo.cn/search/list?key={}'.format(encodName)
# 請求頭
headers = {
"Cookie": "_ga=GA1.2.2021007609.1602479334; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1602479334,1602673632; _gid=GA1.2.168402150.1602673633; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1602673824; kw_token=5LER5W4ZD1C",
"csrf": "5LER5W4ZD1C",
"Referer": "{}".format(referer),
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36",
}
response=requests.get(url=url,headers=headers)
dict2=json.loads(response.text)
misicInfo=dict2['data']['list'] # 歌曲信息的列表
musicNames=list() # 歌曲名稱的列表
rids=list() # 存儲歌曲rid的列表
for i in range(len(misicInfo)):
name=misicInfo[i]['name']+'-'+misicInfo[i]['artist']
musicNames.append(name)
rids.append(misicInfo[i]['rid'])
print('【{}】-{}->>>{}'.format(i+1,int(random.random()*10)*'#$',name))
我們選擇上面列表中歌曲進行試聽,可以發現,在剛才那個下面有一個這樣的網址,里面也是一個json數據,放有我試聽歌曲的下載鏈接。如下: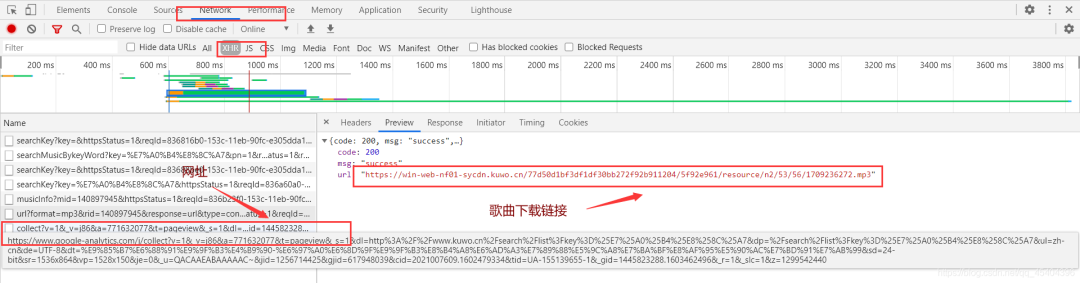
對這個網址進行分析可以得知,需要剛才我們的那個 rid 數據才能訪問到相應的json數據。網址為:http://www.kuwo.cn/url?format=mp3&rid=**140897945**&response=url&type=convert\_url3&br=128kmp3&from=web&t=1603463521198&httpsStatus=1,也許讀者得到的那個網址長度比我這個長一些,我這個是去掉最后面的那個參數的,因為我發現沒有最后的那個參數,依舊可以訪問到相應的數據。
參考代碼如下:
from urllib.request import urlretrieve
from urllib.parse import quote
import requests
import random
import json
musicName=input('請輸入歌曲名稱:')
encodName=quote(musicName)
url='https://www.kuwo.cn/api/www/search/searchMusicBykeyWord?key={}&pn=1&rn=30&httpsStatus=1'.format(encodName)
referer='https://www.kuwo.cn/search/list?key={}'.format(encodName)
# 請求頭
headers = {
"Cookie": "_ga=GA1.2.2021007609.1602479334; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1602479334,1602673632; _gid=GA1.2.168402150.1602673633; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1602673824; kw_token=5LER5W4ZD1C",
"csrf": "5LER5W4ZD1C",
"Referer": "{}".format(referer),
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36",
}
response=requests.get(url=url,headers=headers)
dict2=json.loads(response.text)
misicInfo=dict2['data']['list'] # 歌曲信息的列表
musicNames=list() # 歌曲名稱的列表
rids=list() # 存儲歌曲rid的列表
for i in range(len(misicInfo)):
name=misicInfo[i]['name']+'-'+misicInfo[i]['artist']
musicNames.append(name)
rids.append(misicInfo[i]['rid'])
print('【{}】-{}->>>{}'.format(i+1,int(random.random()*10)*'#$',name))
id=int(input('請輸入歌曲序號:'))
musicRid=rids[id-1]
url2='https://www.kuwo.cn/url?format=mp3&rid={}&response=url&type=convert_url3&br=128kmp3&from=web&t=1602674521838&httpsStatus=1'.format(musicRid)
headers2={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"}
response2=requests.get(url=url2,headers=headers2)
dict3=json.loads(response2.text)
downloadUrl=dict3['url']
path=input('請輸入存儲路徑:')
urlretrieve(url=downloadUrl,filename=path+'\{}.mp3'.format(musicNames[id-1])) # 下載歌曲
運行結果:
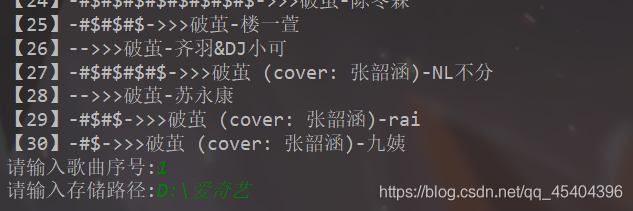
找到相應的目錄,可以發現在這個文件夾下面多了一個.mp3文件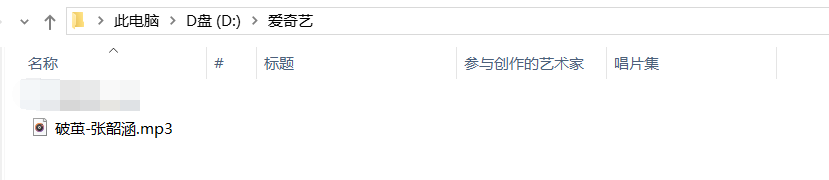
首先,小編先聲明一下:本程序參考代碼僅供學習,切莫用于商業活動,一經被相關人員發現,本小編概不負責!
另外,需要指明的是希望讀者一天不要多次運行本程序代碼,從而減少服務其負擔。
程序代碼或許還有一定的不足!沒有詳細地分析這兩個網址中的參數,讀者有興趣的話,可以嘗試嘗試。如果讀者覺得小編的這篇文章還不錯!離開的時候別忘了點上一個小小的贊!
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





