溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“怎么使用Python自然語言處理NLP創建摘要”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“怎么使用Python自然語言處理NLP創建摘要”吧!
應該使用哪種總結方法
我使用提取摘要,因為我可以將此方法應用于許多文檔,而不必執行大量(令人畏懼)的機器學習模型訓練任務。
此外,提取摘要法比抽象摘要具有更好的總結效果,因為抽象摘要必須從原文中生成新的句子,這是一種比數據驅動的方法提取重要句子更困難的方法。
如何創建自己的文本摘要器
我們將使用單詞直方圖來對句子的重要性進行排序,然后創建一個總結。這樣做的好處是,你不需要訓練你的模型來將其用于文檔。
文本摘要工作流
下面是我們將要遵循的工作流…
導入文本>>>>清理文本并拆分成句子>>刪除停用詞>>構建單詞直方圖>>排名句子>>選擇前N個句子進行提取摘要
(1) 示例文本
我用了一篇新聞文章的文本,標題是蘋果以5000萬美元收購AI初創公司,以推進其應用程序。你可以在這里找到原始的新聞文章:https://analyticsindiamag.com/apple-acquires-ai-startup-for-50-million-to-advance-its-apps/
你還可以從Github下載文本文檔:https://github.com/louisteo9/personal-text-summarizer
(2) 導入庫
# 自然語言工具包(NLTK) import nltk nltk.download('stopwords') # 文本預處理的正則表達式 import re # 隊列算法求首句 import heapq # 數值計算的NumPy import numpy as np # 用于創建數據幀的pandas import pandas as pd # matplotlib繪圖 from matplotlib import pyplot as plt %matplotlib inline(3) 導入文本并執行預處理
有很多方法可以做到。這里的目標是有一個干凈的文本,我們可以輸入到我們的模型中。
# 加載文本文件 with open('Apple_Acquires_AI_Startup.txt', 'r') as f: file_data = f.read()這里,我們使用正則表達式來進行文本預處理。我們將
(A)用空格(如果有的話…)替換參考編號,即[1]、[10]、[20],
(B)用單個空格替換一個或多個空格。
text = file_data # 如果有,請用空格替換 text = re.sub(r'\[[0-9]*\]',' ',text) # 用單個空格替換一個或多個空格 text = re.sub(r'\s+',' ',text)
然后,我們用小寫(不帶特殊字符、數字和額外空格)形成一個干凈的文本,并將其分割成單個單詞,用于詞組分數計算和構詞直方圖。
形成一個干凈文本的原因是,算法不會把“理解”和“理解”作為兩個不同的詞來處理。
# 將所有大寫字符轉換為小寫字符 clean_text = text.lower() # 用空格替換[a-zA-Z0-9]以外的字符 clean_text = re.sub(r'\W',' ',clean_text) # 用空格替換數字 clean_text = re.sub(r'\d',' ',clean_text) # 用單個空格替換一個或多個空格 clean_text = re.sub(r'\s+',' ',clean_text)
(4) 將文本拆分為句子
我們使用NLTK sent_tokenize方法將文本拆分為句子。我們將評估每一句話的重要性,然后決定是否應該將每一句都包含在總結中。
sentences = nltk.sent_tokenize(text)
(5) 刪除停用詞
停用詞是指不給句子增加太多意義的英語單詞。他們可以安全地被忽略,而不犧牲句子的意義。我們已經下載了一個文件,其中包含英文停用詞
這里,我們將得到停用詞的列表,并將它們存儲在stop_word 變量中。
# 獲取停用詞列表 stop_words = nltk.corpus.stopwords.words('english')(6) 構建直方圖
讓我們根據每個單詞在整個文本中出現的次數來評估每個單詞的重要性。
我們將通過(1)將單詞拆分為干凈的文本,(2)刪除停用詞,然后(3)檢查文本中每個單詞的頻率。
# 創建空字典以容納單詞計數 word_count = {} # 循環遍歷標記化的單詞,刪除停用單詞并將單詞計數保存到字典中 for word in nltk.word_tokenize(clean_text): # remove stop words if word not in stop_words: # 將字數保存到詞典 if word not in word_count.keys(): word_count[word] = 1 else: word_count[word] += 1讓我們繪制單詞直方圖并查看結果。
plt.figure(figsize=(16,10)) plt.xticks(rotation = 90) plt.bar(word_count.keys(), word_count.values()) plt.show()
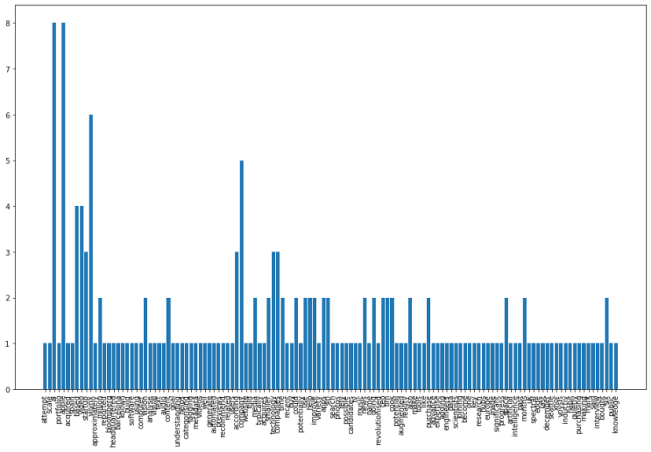
讓我們把它轉換成橫條圖,只顯示前20個單詞,下面有一個helper函數。
# helper 函數,用于繪制最上面的單詞。 def plot_top_words(word_count_dict, show_top_n=20): word_count_table = pd.DataFrame.from_dict(word_count_dict, orient = 'index').rename(columns={0: 'score'}) word_count_table.sort_values(by='score').tail(show_top_n).plot(kind='barh', figsize=(10,10)) plt.show()讓我們展示前20個單詞。
plot_top_words(word_count, 20)
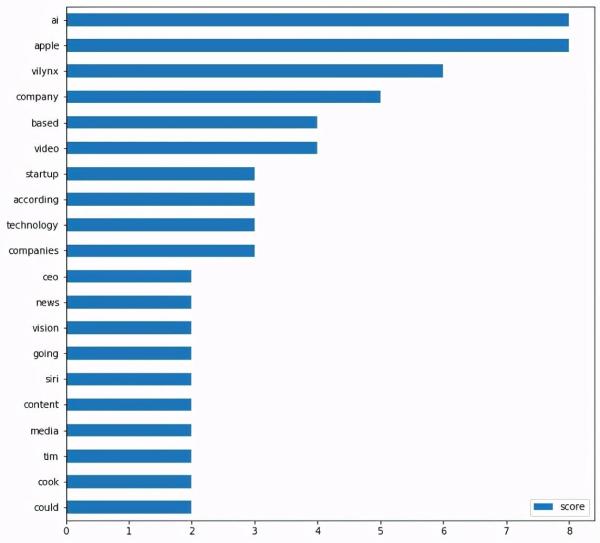
從上面的圖中,我們可以看到“ai”和“apple”兩個詞出現在頂部。這是有道理的,因為這篇文章是關于蘋果收購一家人工智能初創公司的。
(7) 根據分數排列句子
現在,我們將根據句子得分對每個句子的重要性進行排序。我們將:
刪除超過30個單詞的句子,認識到長句未必總是有意義的;
然后,從構成句子的每個單詞中加上分數,形成句子分數。
高分的句子將排在前面。前面的句子將形成我們的總結。
注意:根據我的經驗,任何25到30個單詞都可以給你一個很好的總結。
# 創建空字典來存儲句子分數 sentence_score = {} # 循環通過標記化的句子,只取少于30個單詞的句子,然后加上單詞分數來形成句子分數 for sentence in sentences: # 檢查句子中的單詞是否在字數字典中 for word in nltk.word_tokenize(sentence.lower()): if word in word_count.keys(): # 只接受少于30個單詞的句子 if len(sentence.split(' ')) < 30: # 把單詞分數加到句子分數上 if sentence not in sentence_score.keys(): sentence_score[sentence] = word_count[word] else: sentence_score[sentence] += word_count[word]我們將句子-分數字典轉換成一個數據框,并顯示sentence_score。
注意:字典不允許根據分數對句子進行排序,因此需要將字典中存儲的數據轉換為DataFrame。
df_sentence_score = pd.DataFrame.from_dict(sentence_score, orient = 'index').rename(columns={0: 'score'}) df_sentence_score.sort_values(by='score', ascending = False)
(8) 選擇前面的句子作為摘要
我們使用堆隊列算法來選擇前3個句子,并將它們存儲在best_quences變量中。
通常3-5句話就足夠了。根據文檔的長度,可以隨意更改要顯示的最上面的句子數。
在本例中,我選擇了3,因為我們的文本相對較短。
# 展示最好的三句話作為總結 best_sentences = heapq.nlargest(3, sentence_score, key=sentence_score.get)
讓我們使用print和for loop函數顯示摘要文本。
print('SUMMARY') print('------------------------') # 根據原文中的句子順序顯示最上面的句子 for sentence in sentences: if sentence in best_sentences: print (sentence)到此,相信大家對“怎么使用Python自然語言處理NLP創建摘要”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





