溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關NLP基本工具jieba怎么用,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
jieba是百度工程師Sun Junyi開發的一個開源庫,在GitHub上很受歡迎,使用頻率也很高。
GitHub鏈接:https://github.com/fxsjy/jieba

jieba最流行的應用是分詞,包括介紹頁面上也稱之為“結巴中文分詞”,但除了分詞之外,jieba還可以做關鍵詞抽取、詞頻統計等。
jieba支持四種分詞模式:
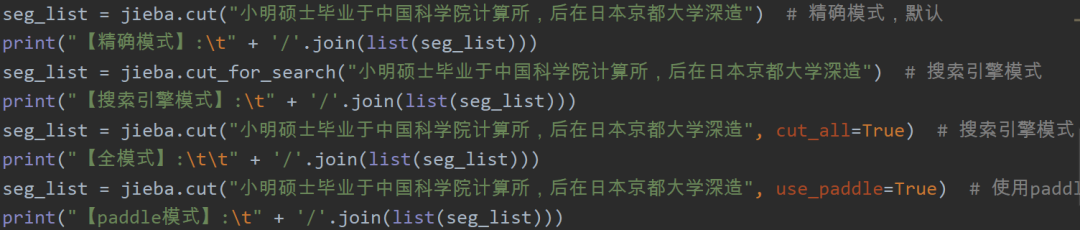
- 精確模式:試圖將句子最精確地切開,只輸出最大概率組合;
- 搜索引擎模式:在精確模式基礎上,對長詞再次切分,提高召回率,適用于搜索引擎分詞;
- 全模式:把句子中所有的可以成詞的詞語都掃描出來;
- paddle模式,利用PaddlePaddle深度學習框架,訓練序列標注(雙向GRU)網絡模型實現分詞。同時支持詞性標注。
代碼:

輸出:

代碼:
輸出

從上面的例子可以看出:
- 精確模式是比較常見的分詞方式,也是默認的方式;
- 搜索引擎模式切分更細一些,包含了清華、華大、大學、中國、科學、學院等等;
- 全模式相對于搜索引擎模式更全,列出了所有可能;
- paddle模式接近于精確模式。
另外,jieba還支持:
- 繁體分詞
- 自定義詞典
安裝:
pip/pip3/easy_installinstall jieba
使用:
importjieba # 導入 jieba
importjieba.posseg as pseg #詞性標注
importjieba.analyse as anls #關鍵詞提取
基于前綴詞典實現高效的詞圖掃描,生成句子中漢字所有可能成詞情況所構成的有向無環圖 (DAG)
采用了動態規劃查找最大概率路徑, 找出基于詞頻的最大切分組合
對于未登錄詞,采用了基于漢字成詞能力的 HMM 模型,使用了 Viterbi 算法
看完上述內容,你們對NLP基本工具jieba怎么用有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





