溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
怎么進行Spark NLP使用入門,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
關于AI在企業中應用的年度O‘Reilly報告已經在2019年2月發布, 該報告針對多個垂直行業的1300多從業人員進行調查, 該調查包含受訪者所在企業中生產環境的AI項目,這些AI項目是如何在企業中應用,以及AI如何快速的擴展到深度學習,人機互助系統,知識圖譜, 強化學習中。
該調查包含了受訪者企業主要使用ML以及AI的框架以及工具情況,下圖為使用情況總結的展示圖:
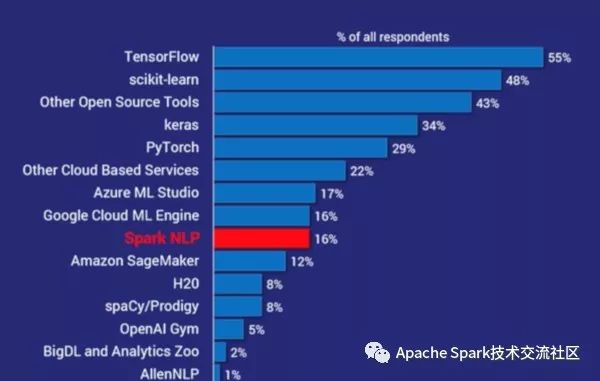
其中Spark NLP在所有的框架以及工具排在第7位,是迄今為止最受歡迎NLP庫,其受歡迎程度是spaCy的兩倍, 事實上,除了其他開源工具以及其他云服務外提供工具或者框架之外,Spark NLP是繼scikit-learn, TensorFlow, Keras,和 PyTorch之后最受歡迎的AI工具。
該調查與近年來Spark NLP在醫療保健,金融, 生命科學和招聘中應用越來越廣泛保持一致, 根本原因在NLP技術在近年來發生重大轉變。
在過去的3-5年中深度學習在自然語言領域的興起使得算法的精度越來越高,而傳統的例如 spaCy, Stanford CoreNLP, ntlp以及OpenNLP在精度上顯然比不上這些最新的研究成果。
為了追求更高的準確度以及性能,工業界不斷將最新的研究成果產品化, 下圖是迄今為止的總結(基于en_core_web_lg標準測試的F1值):
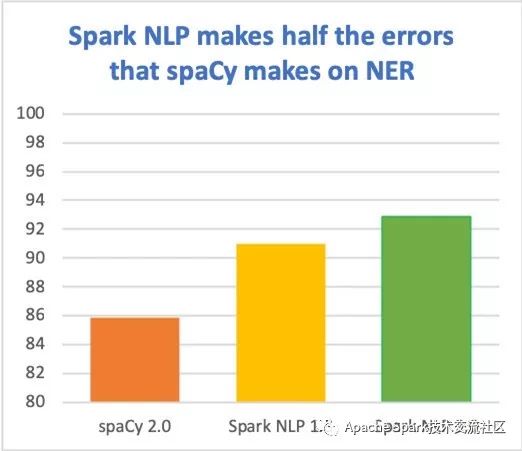
由于Apache Spark的優化使得無論在單機或者在集群的性能都已經非常接近bare metal的性能, Spark NLP的性能可以比傳統的AI庫快一個數量級, 這些傳統的庫受限于他們的設計。
一年前O'Reily發布了迄今為止最全面的產品級別的NLP庫性能對比測試, 下圖中左側為在spaCy和Spark NLP訓練簡單流水的性能對比圖, 該測試基于單機配置(Intel I5, 4核, 16GB內存)進行:
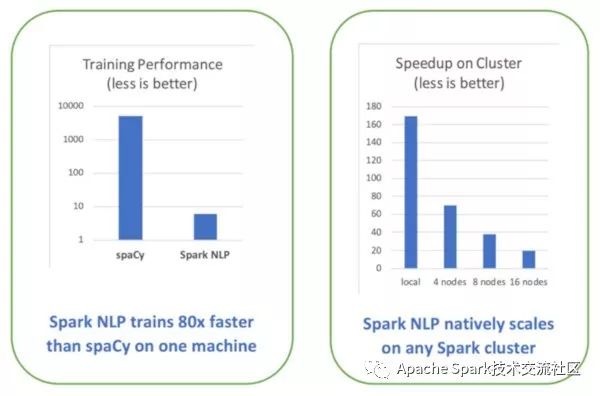
利用GPU來進行訓練以及推理編程深度學習的領域的一大趨勢,使用TensorFlow進行深度學習使得Spark NLP能夠充分利用現代計算機平臺 - 從nVida的DGX-1到Intel的Cascade Lake處理器, 傳統的庫, 不管有沒有使用深度學習的技術, 需要重寫代碼才能夠充分利用這些新硬件的特性,而正是這些新硬件的特性使得NLP性能提高了一個數量級。
在深度學習領域能夠將模型訓練,推理,整個AI流水無縫從單機遷移到集群變得越來越關鍵,Spark NPL得益于原生的構建Apache Spark ML之上,能夠在spark集群做任意擴展, 而Spark的分布式執行計劃以及Cache的優化也能助力提升Spark NLP性能。
不同于AllenNLP以及NLP Architect這樣面向研究的NLP庫,我們致力于向企業提供我們的Spark NLP庫。
Spark NLP使用Apache 2.0的許可協議, 不同于Stanford CoreNLP(商業化需要付費)以及SpaCy模型使用的ShareAlike CC許可協議,該協議是完全免費應用于商品化。
支持多語言編程不僅提高了Spark NLP的受眾面,而且可以避免在使用過程數據的交換,例如, SpaCy只支持Python, 用戶在使用過程需要將數據在JVM進程和Python進程進行交換,這樣會導致架構變得復雜以及性能下降。
除了社區貢獻,Spark NLP還有一個專門的開發團隊,Spark NLP基本上每個月發布兩次,在2018年總共發布了26個版本, Spark NLP社區非常歡迎貢獻代碼,文檔,模型以及問題。
Spark NLP 2.0 一大設計目標就是使用者不要了解Spark或者TensorFlow就可以使用Spark和TensorFlow平臺帶來的好處。用戶不必要了解什么是Spark ML的estimator和transformer, 或者什么是tensorFlow graph或者session, 用戶也可以使用Spark NLP 構建自己的模型,但是能夠以最少時間和學習曲線完成,Spark NLP內置的15種訓練流水和模型可以覆蓋大部分的用戶場景。
用戶可以通過pip或者conda安裝Spark NLP的python版本,Jupyter以及Databricks的安裝以及配置細節可以參考 安裝頁面 (https://nlp.johnsnowlabs.com/docs/en/install), Spark NLP 被廣泛應用在各種組件當中,包括Zepplin, SageMaker, Azure,GCP, Cloudera以及Vanilla spark,支持K8S和非K8S環境。
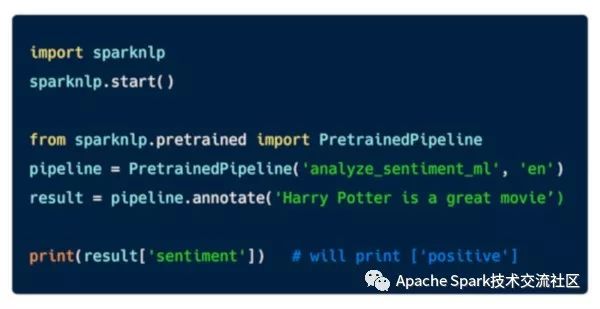
下圖是展示的是情緒分析的簡單例子:
下圖是利用Bert模型訓練命名實體識別的例子:
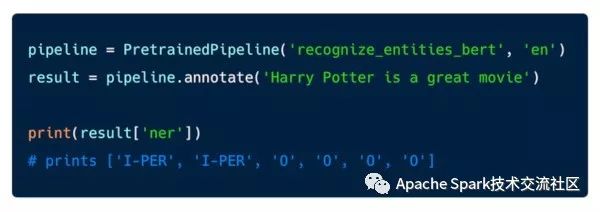
上述例子代碼能夠在spark集群上處理大量文本,其中有兩個關鍵的方法 - annotate(), 該方法以string類型作為輸入, transform(), 該方法的數據輸入是spark 的data frame。
Spark NLP是用Scala語言編寫的, 可以直接操作Spark Data Frame, 在這過程中數據零拷貝,可以充分利用Spark執行計劃以及其他優化,因此對于Scala和Java開發者,使用Spark NLP非常方便。
Spark NLP 可以Maven庫中找到, 用戶只要加上Spark NLP的依賴就可以使用它, 如果用戶希望是有Spark NLP's OCR能力,需要安裝額外的依賴。下圖是個拼寫檢查的例子:
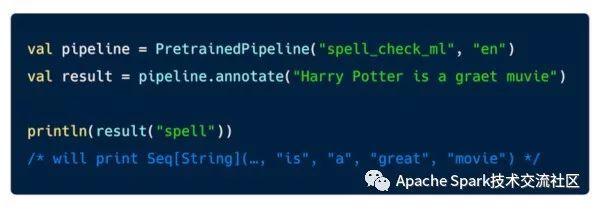
Spark NLP為用戶屏蔽許多復雜的細節,因此上面的代碼片段都非常簡單, 此外Spark NLP也提供了靈活性,用戶可以根據自己的需求進行定制。Spark NLP針對訓練領域的NLP模型做過深度優化。下面詳細介紹Bert模型訓練命名實體識別的Python代碼:
sparknlp.start() 創建spark session。
PretrainedPipeline() 加載 explain_document_dl流水的英文版本, 預訓練模型以及他們的依賴。
啟動TensorFlow, TensorFlow的進程跟spark的處于同一個JVM進程,加載預先訓練的Embeddings和深度學習的模型(例如NER), 模型可以自動在集群上分發以及共享。
annotate() 啟動NLP的推理流程,并且分發各個階段的算法流程。
NER階段運行在tensorflow上,分別采用雙向LSTM的神經網絡以及CNN
Embeddings在推理過程用來將contextual tokens轉換為vectors
最后結果以python字典的形式輸出
Spark NLP主頁包含大量的樣例, 文檔以及安裝說明文檔, 此外Spark NLP還提供了docker鏡像, 用戶可以很方便的在本地構建自己的環境。用戶如果遇到任何問題, 用戶可以登錄Slack尋求幫助。
看完上述內容,你們掌握怎么進行Spark NLP使用入門的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





