溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關R語言中有哪些統計分析方法,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
R語言是用于統計分析、繪圖的語言和操作環境,屬于GNU系統的一個自由、免費、源代碼開放的軟件,它是一個用于統計計算和統計制圖的優秀工具。
根據分組字段,將分析對象劃分為不同的部分,以進行對比分析各組之間差異性的一種分析方法。
常用統計指標:
計數 length
求和 sum
平均值 mean
標準差 var
方差 sd
分組統計函數
aggregate(分組表達式,data=需要分組的數據框,function=統計函數)
參數說明
formula:分組表達式,格式:統計列~分組列1+分組列2+...
data=需要分組的數據框
function:統計函數
aggregate(name ~ class, data=data, FUN=length); #求和 aggregate(score ~ class, data=data, FUN=sum); #均值 aggregate(score ~ class, data=data, FUN=mean); #方差 aggregate(score ~ class, data=data, FUN=var); #標準差 aggregate(score ~ class, data=data, FUN=sd)
根據分析目的,將數據(定量數據)進行等距或者不等距的分組,進行研究各組分布規律的一種分析方法。
分組函數
cut(data,breaks,labels,right)
參數說明
data=需要分組的一列數據
breaks=分組條件,如果是一個數字,那么將平均分組;如果是一個數組,那么將按照指定范圍分組
labels:分組標簽
right:指定范圍是否右閉合,默認為右閉合,right參數為TRUE
用戶明細 <- read.csv('data.csv', stringsAsFactors=FALSE)
head(用戶明細)
breaks <- c(min(用戶明細$年齡)-1, 20, 30, 40, max(用戶明細$年齡)+1)
年齡分組 <- cut(用戶明細$年齡, breaks = breaks)
用戶明細[, '年齡分組1'] <- 年齡分組
年齡分組 <- cut(用戶明細$年齡, breaks = breaks, right = FALSE)
用戶明細[, '年齡分組2'] <- 年齡分組
labels <- c('20歲以及以下', '21歲到30歲', '31歲到40歲', '41歲以上');
年齡分組 <- cut(用戶明細$年齡, breaks = breaks, labels = labels)
用戶明細[, '年齡分組'] <- 年齡分組
head(用戶明細)
aggregate(formula=用戶ID ~ 年齡分組, data=用戶明細, FUN=length)通常用于分析兩個或兩個以上,分組變量之間的關系,以交叉表形式進行變量間關系的對比分析;
交叉分析的原理就是從數據的不同維度,綜合進行分組細分,以進一步了解數據的構成、分布特征。
交叉分析函數:
tapply(統計向量,list(數據透視表中的行,數據透視變中的列),FUN=統計函數)
返回值說明:
一個table類型的統計量
breaks <- c(min(用戶明細$年齡)-1, 20, 30, 40, max(用戶明細$年齡)+1)
labels <- c('20歲以及以下', '21歲到30歲', '31歲到40歲', '41歲以上');
年齡分組 <- cut(用戶明細$年齡, breaks = breaks, labels = labels)
用戶明細[, '年齡分組'] <- 年齡分組
head(用戶明細)
tapply(用戶明細$用戶ID, list(用戶明細$年齡分組, 用戶明細$性別), FUN=length)是在分組的基礎上,計算各組成部分所占的比重,進而分析總體內部特征的一種分析方法。
for example:資產占有率就是一個非常經典的運用
統計占比函數
prop.table(table,margin=NULL)
參數說明:
table,使用tapply函數統計得到的分組計數或求和結果
margin,占比統計方式,具體參數如下:
屬性 注釋
1 按行統計占比
2 按列統計占比
NULL 按整體統計占比
data <- read.csv('data.csv', stringsAsFactors=FALSE);head(data) t <- tapply(data$月消費.元., list(data$通信品牌), sum) t prop.table(t); t <- tapply(data$月消費.元., list(data$通信品牌), mean) t prop.table(t); t <- tapply(data$月消費.元., list(data$省份, data$通信品牌), sum) t prop.table(t, margin = 2)
是研究現象之間是否存在某種依存關系,并對具體有依存關系的現象探討其相關方向以及相關程度,是研究隨機變量之間的相關關系的一種統計方法。
相關系數r 可以用來描述定量變量之間的關系
相關分析函數:
cor(向量1,向量2,...)返回值:table類型的統計量
data <- read.csv('data.csv', fileEncoding = "UTF-8");
cor(data[, 2:7])補充:R中基本統計分析方法整理
面對一大堆的數據,往往會讓人眼花繚亂。但是只要使用一些簡單圖形和運算,就可以了解數據更多的特征。R提供了很多關于數據描述的函數,通過這些函數可以對數據進行一個簡單地初步分析。
mean(x):平均值
median(x):中位數
sd(x):標準差
var(x):方差
sum(x):求和
min(x):最小值
max(x):最大值
range(x):值域
......等等
提供最小值、下四分位數、中位數、平均值、上四分位數、最大值。
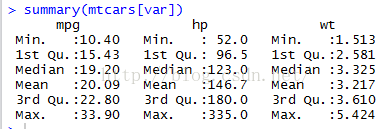
計算參數指定的任意描述性統計量。
其中sapply()用法:sapply(x,FUNC,options) ,x是待處理的數據框,FUNC是用戶指定的函數,如sum()、max()、mean()等等,指定了的options會傳遞給FUNC。

返回變量和觀測值的數目、缺失值和唯一值的數目、平均值、分位數、五個最大的值和五個最小的值。
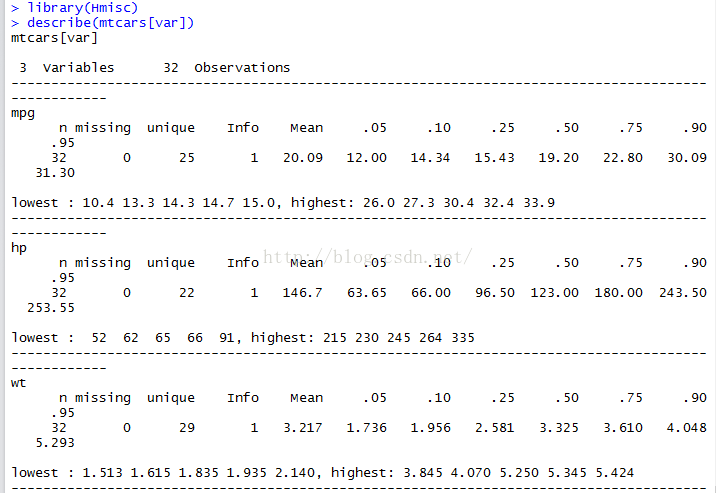
可以計算種類繁多的描述性統計量

它可以計算非缺失值的數量、平均數、標準差、中位數、截尾均值、絕對中位差、最小值、最大值、值域、偏度、峰度等。

關于R語言中有哪些統計分析方法就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





