溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一、背景
1.項目描述
2.數據描述
| 字段名 | 描述 |
|---|---|
| CustomerID | 客戶編號 |
| Gender | 性別 |
| Age | 年齡 |
| Annual Income (k$) | 年收入,單位為千美元 |
| Spending Score (1-100) | 消費分數,范圍在1~100 |
二、相關模塊
import numpy as np import pandas as pd
from pandas import plotting import matplotlib.pyplot as plt import seaborn as sns import plotly.graph_objs as go import plotly.offline as py
from sklearn.cluster import KMeans
import warnings
warnings.filterwarnings('ignore')
三、數據可視化
1.數據讀取
io = '.../Mall_Customers.csv'
df = pd.DataFrame(pd.read_csv(io))
# 修改列名
df.rename(columns={'Annual Income (k$)': 'Annual Income', 'Spending Score (1-100)': 'Spending Score'}, inplace=True)
print(df.head())
print(df.describe())
print(df.shape)
print(df.count())
print(df.dtypes)
輸出如下。
CustomerID Gender Age Annual Income Spending Score
0 1 Male 19 15 39
1 2 Male 21 15 81
2 3 Female 20 16 6
3 4 Female 23 16 77
4 5 Female 31 17 40
-----------------------------------------------------------------
CustomerID Age Annual Income Spending Score
count 200.000000 200.000000 200.000000 200.000000
mean 100.500000 38.850000 60.560000 50.200000
std 57.879185 13.969007 26.264721 25.823522
min 1.000000 18.000000 15.000000 1.000000
25% 50.750000 28.750000 41.500000 34.750000
50% 100.500000 36.000000 61.500000 50.000000
75% 150.250000 49.000000 78.000000 73.000000
max 200.000000 70.000000 137.000000 99.000000
-----------------------------------------------------------------
(200, 5)
CustomerID 200
Gender 200
Age 200
Annual Income 200
Spending Score 200
dtype: int64
-----------------------------------------------------------------
CustomerID int64
Gender object
Age int64
Annual Income int64
Spending Score int64
dtype: object
2.數據可視化
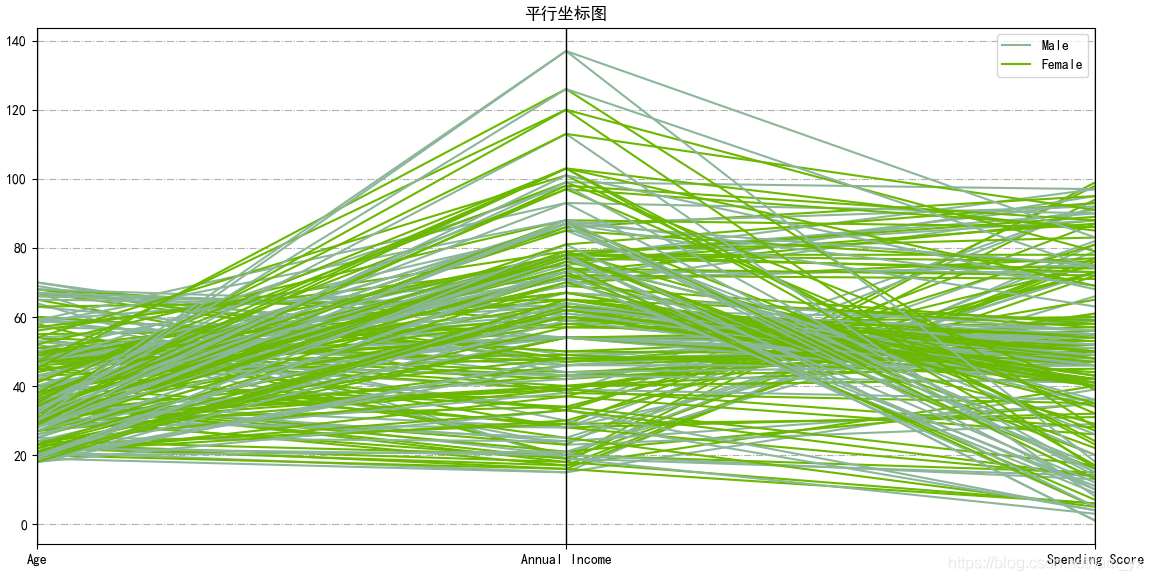
2.1 平行坐標圖
plotting.parallel_coordinates(df.drop('CustomerID', axis=1), 'Gender')
plt.title('平行坐標圖', fontsize=12)
plt.grid(linestyle='-.')
plt.show()
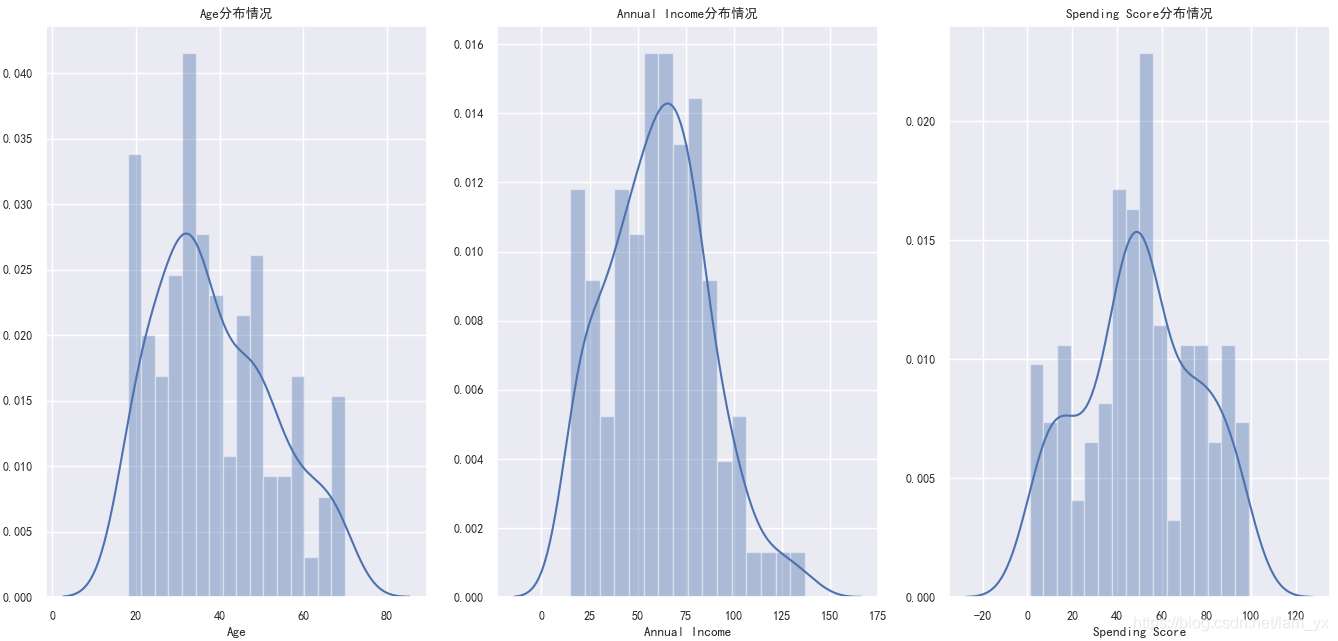
2.2 年齡/年收入/消費分數的分布
這里用了直方圖和核密度圖。(注:核密度圖看的是(x<X)的面積,而不是高度)
sns.set(palette="muted", color_codes=True) # seaborn樣式
# 配置
plt.rcParams['axes.unicode_minus'] = False # 解決無法顯示符號的問題
sns.set(font='SimHei', font_scale=0.8) # 解決Seaborn中文顯示問題
# 繪圖
plt.figure(1, figsize=(13, 6))
n = 0
for x in ['Age', 'Annual Income', 'Spending Score']:
n += 1
plt.subplot(1, 3, n)
plt.subplots_adjust(hspace=0.5, wspace=0.5)
sns.distplot(df[x], bins=16, kde=True) # kde 密度曲線
plt.title('{}分布情況'.format(x))
plt.tight_layout()
plt.show()
如下圖。從左到右分別是年齡、年收入和消費能力的分布情況。發現:
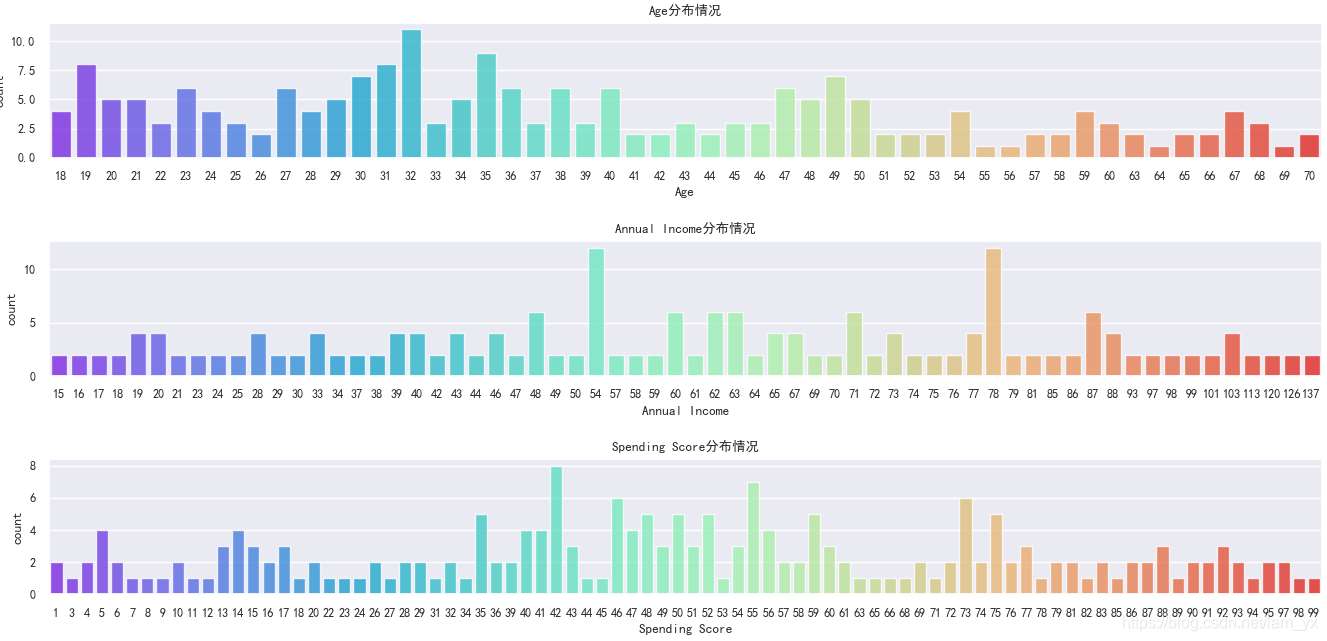
2.3年齡/年收入/消費分數的柱狀圖
這里使用的是柱狀圖,和直方圖不同的是:
plt.figure(1, figsize=(13, 6))
k = 0
for x in ['Age', 'Annual Income', 'Spending Score']:
k += 1
plt.subplot(3, 1, k)
plt.subplots_adjust(hspace=0.5, wspace=0.5)
sns.countplot(df[x], palette='rainbow', alpha=0.8)
plt.title('{}分布情況'.format(x))
plt.tight_layout()
plt.show()
如下圖。從上到下分別是年齡、年收入和消費能力的柱狀圖。發現:
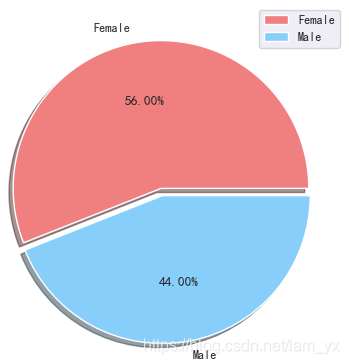
2.4不同性別用戶占比
df_gender_c = df['Gender'].value_counts()
p_lables = ['Female', 'Male']
p_color = ['lightcoral', 'lightskyblue']
p_explode = [0, 0.05]
# 繪圖
plt.pie(df_gender_c, labels=p_lables, colors=p_color, explode=p_explode, shadow=True, autopct='%.2f%%')
plt.axis('off')
plt.legend()
plt.show()
如下餅圖。女性以56%的份額居于領先地位,而男性則占整體的44%。特別是當男性人口相對高于女性時,這是一個比較大的差距。
2.5 兩兩特征之間的關系
# df_a_a_s = df.drop(['CustomerID'], axis=1) sns.pairplot(df, vars=['Age', 'Annual Income', 'Spending Score'], hue='Gender', aspect=1.5, kind='reg') plt.show()
pairplot主要展現的是屬性(變量)兩兩之間的關系(線性或非線性,有無較為明顯的相關關系)。注意,我對男、女性的數據點進行了區分(但是感覺數據在性別上的差異不大呀?)。如下組圖所示:
kind 參數設置為 reg 會為非對角線上的散點圖擬合出一條回歸直線,更直觀地顯示變量之間的關系。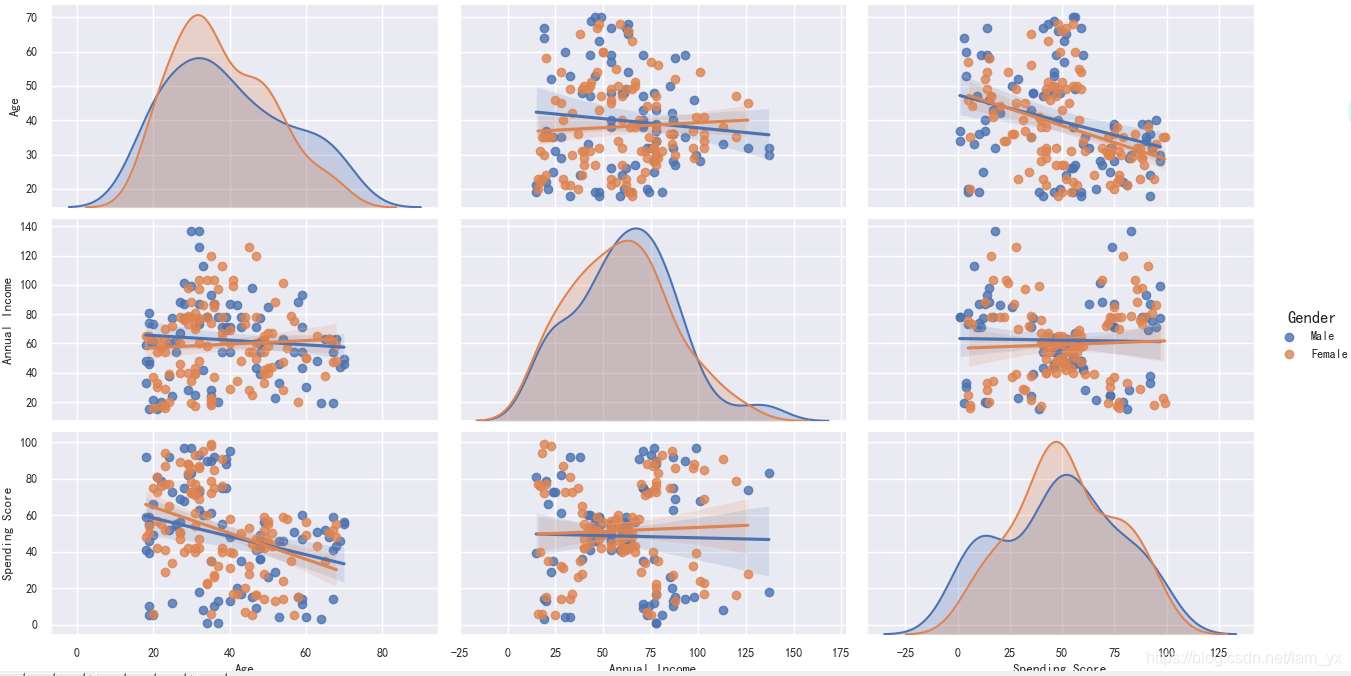
2.6 兩兩特征之間的分布
# 根據分類變量分組繪制一個縱向的增強箱型圖
plt.rcParams['axes.unicode_minus'] = False # 解決無法顯示符號的問題
sns.set(font='SimHei', font_scale=0.8) # 解決Seaborn中文顯示問題
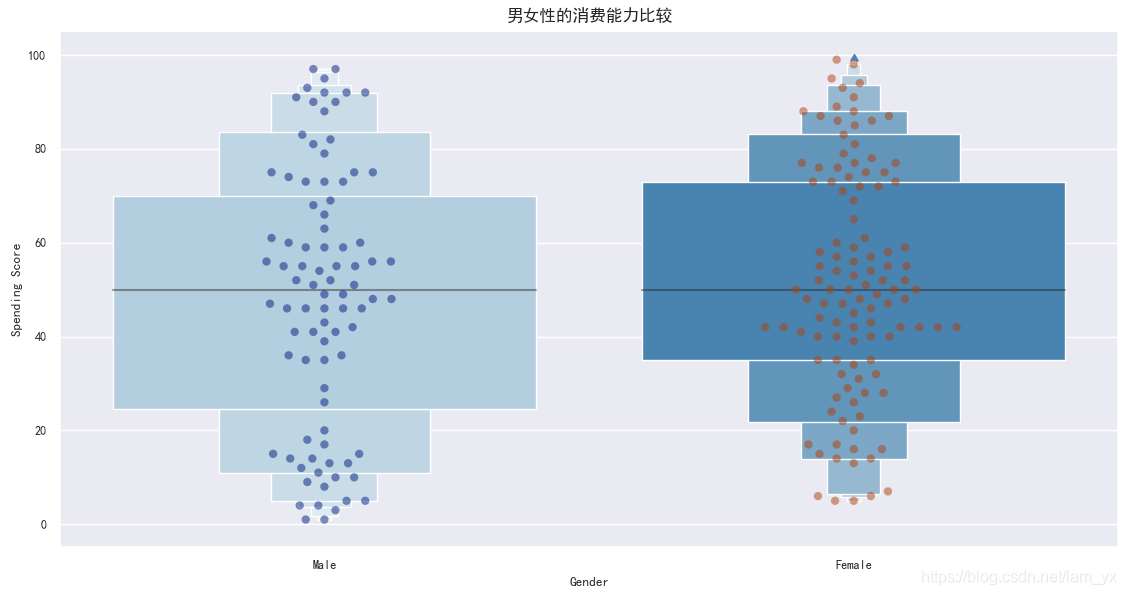
sns.boxenplot(df['Gender'], df['Spending Score'], palette='Blues')
# x:設置分組統計字段,y:數據分布統計字段
sns.swarmplot(x=df['Gender'], y=df['Spending Score'], data=df, palette='dark', alpha=0.5, size=6)
plt.title('男女性的消費能力比較', fontsize=12)
plt.show()
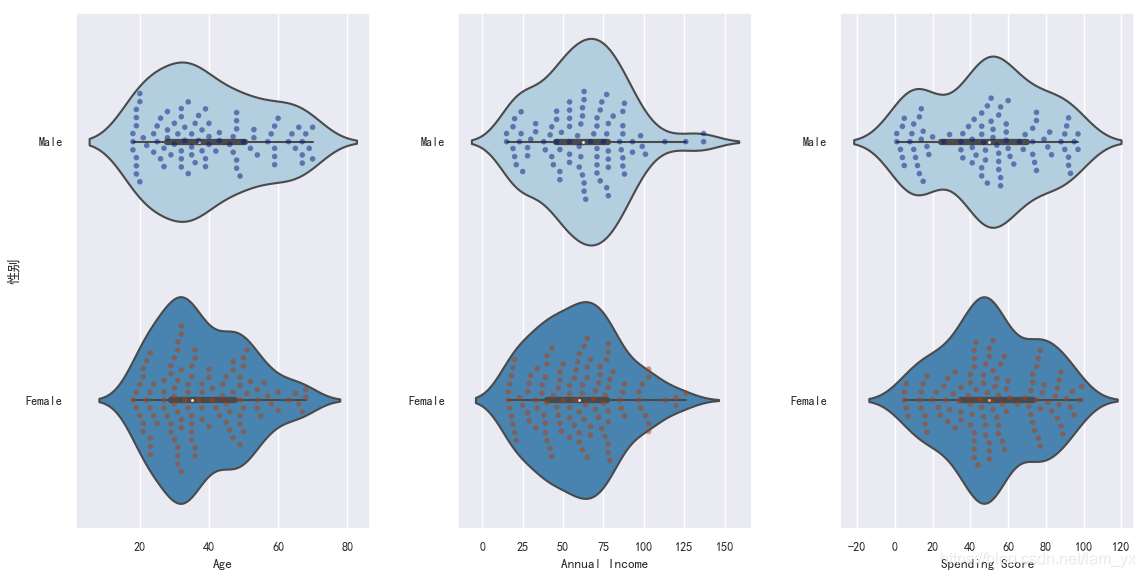
# 根據分類變量分組繪制一個縱向的增強箱型圖
plt.rcParams['axes.unicode_minus'] = False # 解決無法顯示符號的問題
sns.set(font='SimHei', font_scale=0.8) # 解決Seaborn中文顯示問題
sns.boxenplot(df['Gender'], df['Spending Score'], palette='Blues')
# x:設置分組統計字段,y:數據分布統計字段
sns.swarmplot(x=df['Gender'], y=df['Spending Score'], data=df, palette='dark', alpha=0.5, size=6)
plt.title('男女性的消費能力比較', fontsize=12)
plt.show()
其實,下面這一部分也包含了上面的信息。
四、K-means聚類分析
0.手肘法簡介
核心指標
誤差平方和(sum of the squared errors,SSE)是所有樣本的聚類誤差反映了聚類效果的好壞,公式如下:
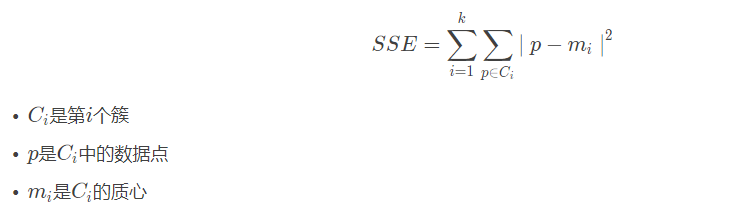
核心思想
1.基于年齡和消費分數的聚類
所需要的數據有‘Age'和‘Spending Score'。
df_a_sc = df[['Age', 'Spending Score']].values # 存放每次聚類結果的誤差平方和 inertia1 = []
使用手肘法確定最合適的
for n in range(1, 11):
# 構造聚類器
km1 = (KMeans(n_clusters=n, # 要分成的簇數,int類型,默認值為8
init='k-means++', # 初始化質心,k-means++是一種生成初始質心的算法
n_init=10, # 設置選擇質心種子次數,默認為10次。返回質心最好的一次結果(好是指計算時長短)
max_iter=300, # 每次迭代的最大次數
tol=0.0001, # 容忍的最小誤差,當誤差小于tol就會退出迭代
random_state=111, # 隨機生成器的種子 ,和初始化中心有關
algorithm='elkan')) # 'full'是傳統的K-Means算法,'elkan'是采用elkan K-Means算法
# 用訓練數據擬合聚類器模型
km1.fit(df_a_sc)
# 獲取聚類標簽
inertia1.append(km1.inertia_)
繪圖確定
plt.figure(1, figsize=(15, 6))
plt.plot(np.arange(1, 11), inertia1, 'o')
plt.plot(np.arange(1, 11), inertia1, '-', alpha=0.7)
plt.title('手肘法圖', fontsize=12)
plt.xlabel('聚類數'), plt.ylabel('SSE')
plt.grid(linestyle='-.')
plt.show()
通過如下圖,確定
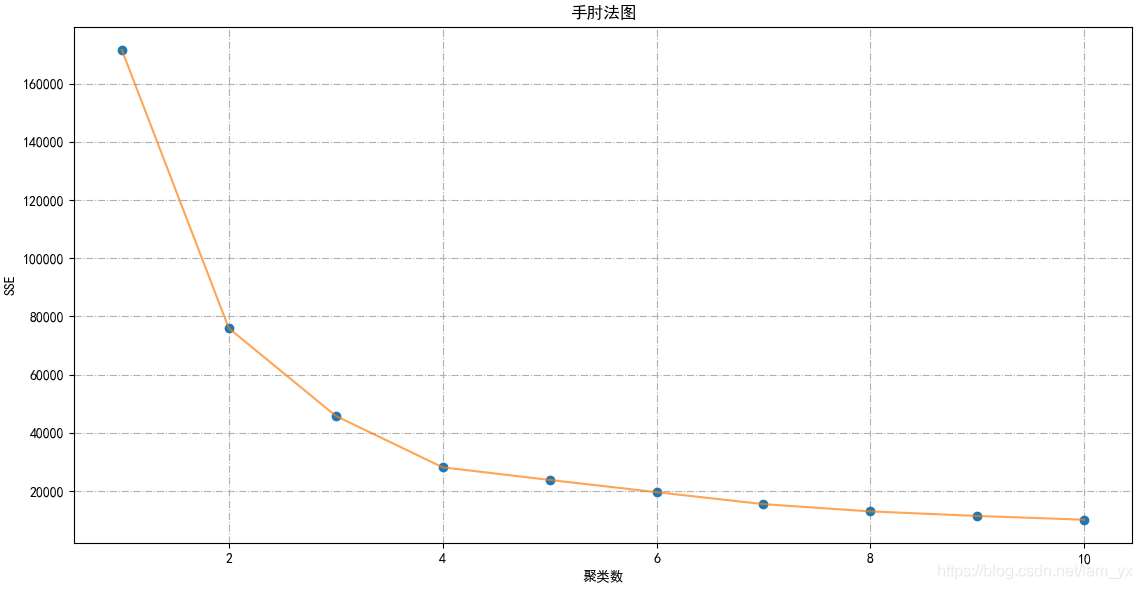
確定
km1_result = (KMeans(n_clusters=4, init='k-means++', n_init=10, max_iter=300,
tol=0.0001, random_state=111, algorithm='elkan'))
# 先fit()再predict(),一次性得到聚類預測之后的標簽
y1_means = km1_result.fit_predict(df_a_sc)
# 繪制結果圖
plt.scatter(df_a_sc[y1_means == 0][:, 0], df_a_sc[y1_means == 0][:, 1], s=70, c='blue', label='1', alpha=0.6)
plt.scatter(df_a_sc[y1_means == 1][:, 0], df_a_sc[y1_means == 1][:, 1], s=70, c='orange', label='2', alpha=0.6)
plt.scatter(df_a_sc[y1_means == 2][:, 0], df_a_sc[y1_means == 2][:, 1], s=70, c='pink', label='3', alpha=0.6)
plt.scatter(df_a_sc[y1_means == 3][:, 0], df_a_sc[y1_means == 3][:, 1], s=70, c='purple', label='4', alpha=0.6)
plt.scatter(km1_result.cluster_centers_[:, 0], km1_result.cluster_centers_[:, 1], s=260, c='gold', label='質心')
plt.title('聚類圖(K=4)', fontsize=12)
plt.xlabel('年收入(k$)')
plt.ylabel('消費分數(1-100)')
plt.legend()
plt.grid(linestyle='-.')
plt.show()
效果如下,基于年齡和消費能力這兩個參數,可以將用戶劃分成4類。
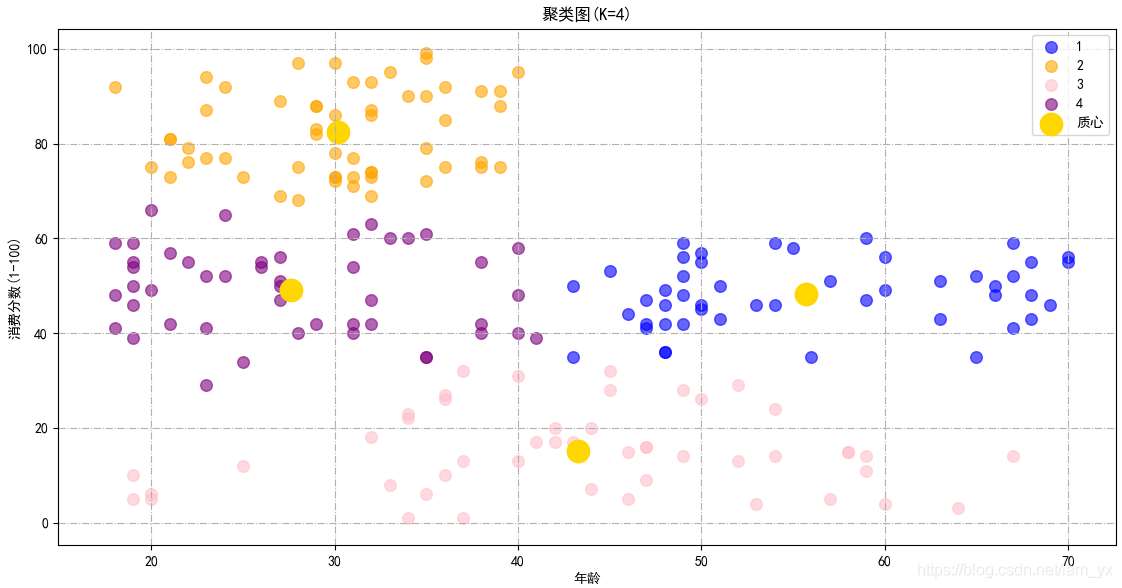
2.基于年收入和消費分數的聚類
所需要的數據
df_ai_sc = df[['Annual Income', 'Spending Score']].values # 存放每次聚類結果的誤差平方和 inertia2 = []
同理,使用手肘法確定合適的
for n in range(1, 11):
# 構造聚類器
km2 = (KMeans(n_clusters=n, init='k-means++', n_init=10, max_iter=300, tol=0.0001, random_state=111, algorithm='elkan'))
# 用訓練數據擬合聚類器模型
km2.fit(df_ai_sc)
# 獲取聚類標簽
inertia2.append(km2.inertia_)
# 繪制手肘圖確定K值
plt.figure(1, figsize=(15, 6))
plt.plot(np.arange(1, 11), inertia1, 'o')
plt.plot(np.arange(1, 11), inertia1, '-', alpha=0.7)
plt.title('手肘法圖', fontsize=12)
plt.xlabel('聚類數'), plt.ylabel('SSE')
plt.grid(linestyle='-.')
plt.show()
通過如下圖,確定
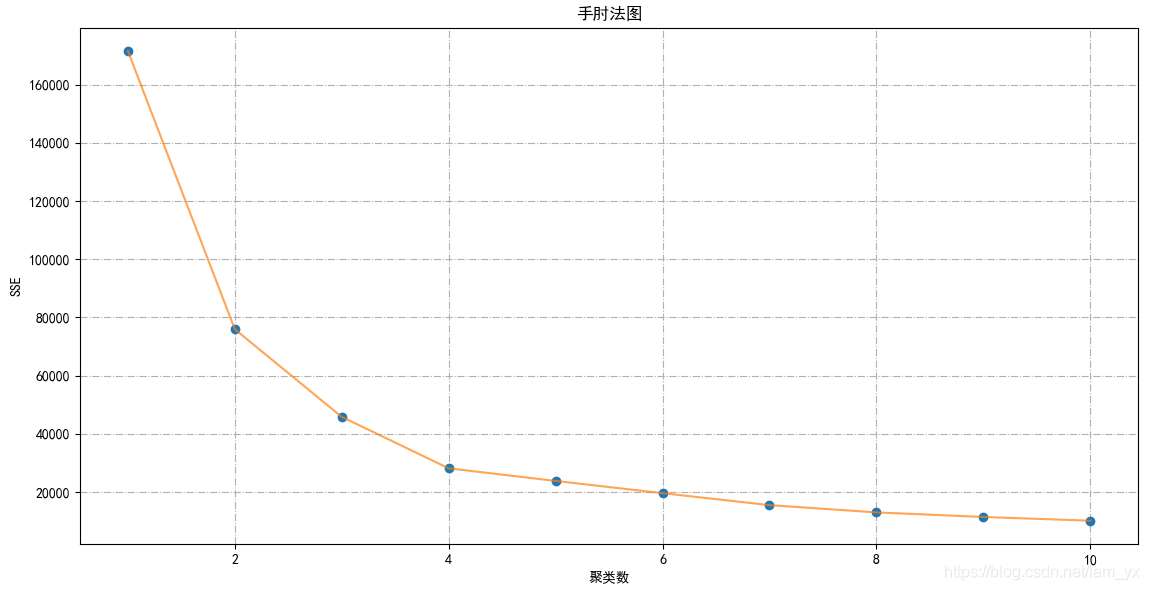
確定
km2_result = (KMeans(n_clusters=5, init='k-means++', n_init=10, max_iter=300,
tol=0.0001, random_state=111, algorithm='elkan'))
# 先fit()再predict(),一次性得到聚類預測之后的標簽
y2_means = km2_result.fit_predict(df_ai_sc)
# 繪制結果圖
plt.scatter(df_ai_sc[y2_means == 0][:, 0], df_ai_sc[y2_means == 0][:, 1], s=70, c='blue', label='1', alpha=0.6)
plt.scatter(df_ai_sc[y2_means == 1][:, 0], df_ai_sc[y2_means == 1][:, 1], s=70, c='orange', label='2', alpha=0.6)
plt.scatter(df_ai_sc[y2_means == 2][:, 0], df_ai_sc[y2_means == 2][:, 1], s=70, c='pink', label='3', alpha=0.6)
plt.scatter(df_ai_sc[y2_means == 3][:, 0], df_ai_sc[y2_means == 3][:, 1], s=70, c='purple', label='4', alpha=0.6)
plt.scatter(df_ai_sc[y2_means == 4][:, 0], df_ai_sc[y2_means == 4][:, 1], s=70, c='green', label='5', alpha=0.6)
plt.scatter(km2_result.cluster_centers_[:, 0], km2_result.cluster_centers_[:, 1], s=260, c='gold', label='質心')
plt.title('聚類圖(K=5)', fontsize=12)
plt.xlabel('年收入(k$)')
plt.ylabel('消費分數(1-100)')
plt.legend()
plt.grid(linestyle='-.')
plt.show()
效果如下,基于年收入和消費能力這兩個參數,可以將用戶劃分成如下5類:
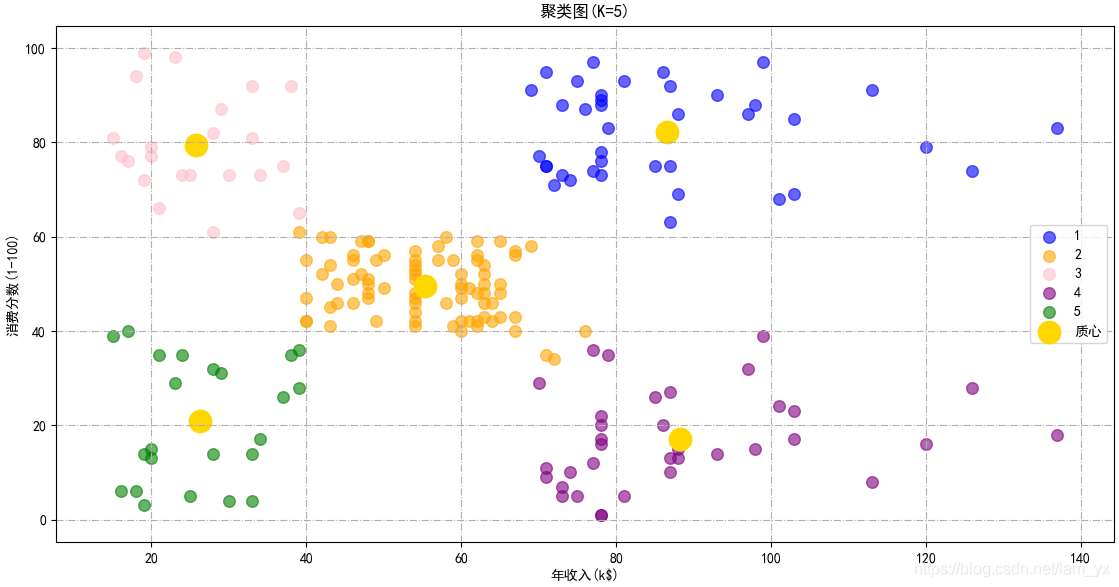
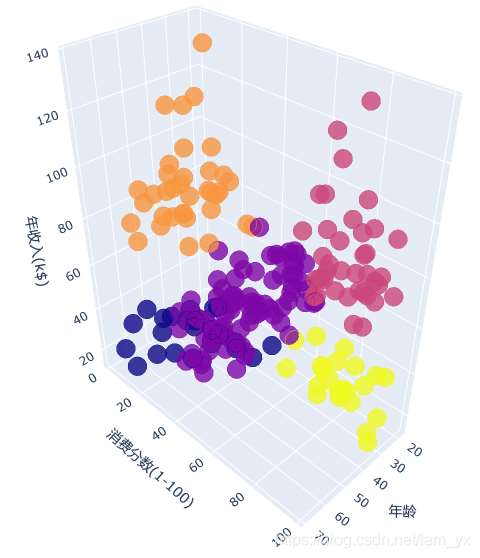
3.基于年齡、收入和消費分數的聚類所需要的數據
df_a_ai_sc = df[['Age', 'Annual Income', 'Spending Score']].values
聚類,
km3 = KMeans(n_clusters=5, init='k-means++', max_iter=300, n_init=10, random_state=0) km3.fit(df_a_ai_sc)
繪圖。
df['labels'] = km3.labels_
# 繪制3D圖
trace1 = go.Scatter3d(
x=df['Age'],
y=df['Spending Score'],
z=df['Annual Income'],
mode='markers',
marker=dict(
color=df['labels'],
size=10,
line=dict(
color=df['labels'],
width=12
),
opacity=0.8
)
)
df_3dfid = [trace1]
layout = go.Layout(
margin=dict(
l=0,
r=0,
b=0,
t=0
),
scene=dict(
xaxis=dict(title='年齡'),
yaxis=dict(title='消費分數(1-100)'),
zaxis=dict(title='年收入(k$)')
)
)
fig = go.Figure(data=df_3dfid, layout=layout)
py.offline.plot(fig)
效果如下。
五、小結
到此這篇關于Python用K-means聚類算法進行客戶分群的實現的文章就介紹到這了,更多相關Python K-means客戶分群內容請搜索億速云以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持億速云!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





