溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關怎么在python中利用K-means聚類算法對圖像進行分割,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
1 K-means算法
實際上,無論是從算法思想,還是具體實現上,K-means算法是一種很簡單的算法。它屬于無監督分類,通過按照一定的方式度量樣本之間的相似度,通過迭代更新聚類中心,當聚類中心不再移動或移動差值小于閾值時,則就樣本分為不同的類別。
1.1 算法思路
隨機選取聚類中心
根據當前聚類中心,利用選定的度量方式,分類所有樣本點
計算當前每一類的樣本點的均值,作為下一次迭代的聚類中心
計算下一次迭代的聚類中心與當前聚類中心的差距
如4中的差距小于給定迭代閾值時,迭代結束。反之,至2繼續下一次迭代
1.2 度量方式
根據聚類中心,將所有樣本點分為最相似的類別。這需要一個有效的盤踞,平方差是最常用的度量方式,如下

2 應用于圖像分割
我們知道:無論是灰度圖還是RGB彩色圖,實際上都是存有灰度值的矩陣,所以,圖像的數據格式決定了在圖像分割方向上,使用K-means聚類算法是十分容易也十分具體的。
2.1 Code
導入必要的包
import numpy as np import random
損失函數
def loss_function(present_center, pre_center): ''' 損失函數,計算上一次與當前聚類中的差異(像素差的平方和) :param present_center: 當前聚類中心 :param pre_center: 上一次聚類中心 :return: 損失值 ''' present_center = np.array(present_center) pre_center = np.array(pre_center) return np.sum((present_center - pre_center)**2)
分類器
def classifer(intput_signal, center): ''' 分類器(通過當前的聚類中心,給輸入圖像分類) :param intput_signal: 輸入圖像 :param center: 聚類中心 :return: 標簽矩陣 ''' input_row, input_col= intput_signal.shape # 輸入圖像的尺寸 pixls_labels = np.zeros((input_row, input_col)) # 儲存所有像素標簽 pixl_distance_t = [] # 單個元素與所有聚類中心的距離,臨時用 for i in range(input_row): for j in range(input_col): # 計算每個像素與所有聚類中心的差平方 for k in range(len(center)): distance_t = np.sum(abs((intput_signal[i, j]).astype(int) - center[k].astype(int))**2) pixl_distance_t.append(distance_t) # 差異最小則為該類 pixls_labels[i, j] = int(pixl_distance_t.index(min(pixl_distance_t))) # 清空該list,為下一個像素點做準備 pixl_distance_t = [] return pixls_labels
基于k-means算法的圖像分割
def k_means(input_signal, center_num, threshold):
'''
基于k-means算法的圖像分割(適用于灰度圖)
:param input_signal: 輸入圖像
:param center_num: 聚類中心數目
:param threshold: 迭代閾值
:return:
'''
input_signal_cp = np.copy(input_signal) # 輸入信號的副本
input_row, input_col = input_signal_cp.shape # 輸入圖像的尺寸
pixls_labels = np.zeros((input_row, input_col)) # 儲存所有像素標簽
# 隨機初始聚類中心行標與列標
initial_center_row_num = [i for i in range(input_row)]
random.shuffle(initial_center_row_num)
initial_center_row_num = initial_center_row_num[:center_num]
initial_center_col_num = [i for i in range(input_col)]
random.shuffle(initial_center_col_num)
initial_center_col_num = initial_center_col_num[:center_num]
# 當前的聚類中心
present_center = []
for i in range(center_num):
present_center.append(input_signal_cp[initial_center_row_num[i], initial_center_row_num[i]])
pixls_labels = classifer(input_signal_cp, present_center)
num = 0 # 用于記錄迭代次數
while True:
pre_centet = present_center.copy() # 儲存前一次的聚類中心
# 計算當前聚類中心
for n in range(center_num):
temp = np.where(pixls_labels == n)
present_center[n] = sum(input_signal_cp[temp].astype(int)) / len(input_signal_cp[temp])
# 根據當前聚類中心分類
pixls_labels = classifer(input_signal_cp, present_center)
# 計算上一次聚類中心與當前聚類中心的差異
loss = loss_function(present_center, pre_centet)
num = num + 1
print("Step:"+ str(num) + " Loss:" + str(loss))
# 當損失小于迭代閾值時,結束迭代
if loss <= threshold:
break
return pixls_labels3 分類效果

聚類中心個數=3,迭代閾值為=1
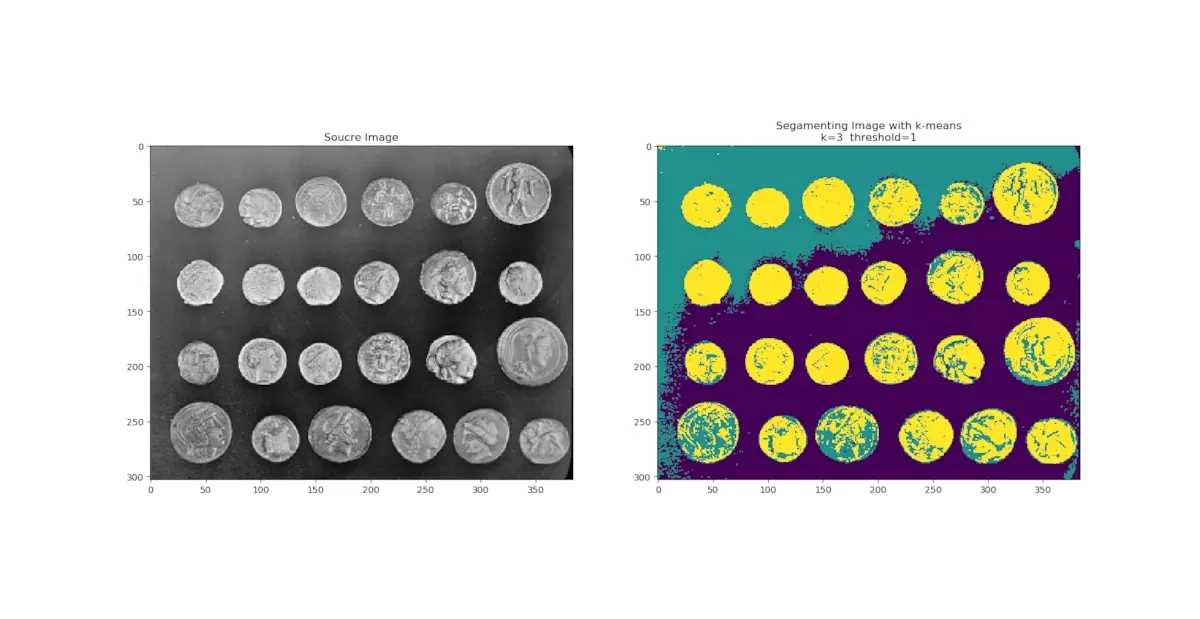
聚類中心個數=3,迭代閾值為=1
以上就是怎么在python中利用K-means聚類算法對圖像進行分割,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





