溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Java內存模型原理是什么”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“Java內存模型原理是什么”文章能幫助大家解決問題。
JVM 中試圖定義一種 JMM 來屏蔽各種硬件和操作系統的內存訪問差異,以實現讓 Java 程序在各種平臺下都能達到一致的內存訪問效果。
JMM 的主要目標是定義程序中各個變量的訪問規則,即在虛擬機中將變量存儲到內存和從內存中取出變量這樣的底層細節。此處的變量與 Java 編程中的變量有所區別,它包括了實例字段、靜態字段和構成數組對象的元素,但不包括局部變量與方法參數,因為后者是線程私有的,不會被共享,自然就不會存在競爭問題。為了獲得較好的執行效能,Java 內存模型并沒有限制執行引擎使用處理器的特定寄存器或緩存來和主存進行交互,也沒有限制即使編譯器進行調整代碼執行順序這類優化措施。
JMM 是圍繞著在并發過程中如何處理原子性、可見性和有序性這 3 個特征來建立的。
JMM 是通過各種操作來定義的,包括對變量的讀寫操作,監視器的加鎖和釋放操作,以及線程的啟動和合并操作。
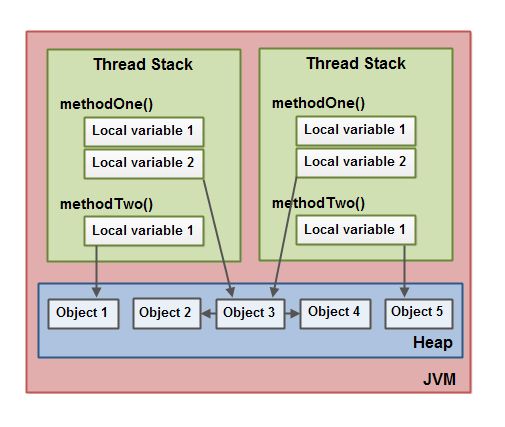
Java 內存模型把 Java 虛擬機內部劃分為線程棧和堆。
每一個運行在 Java 虛擬機里的線程都擁有自己的線程棧。這個線程棧包含了這個線程調用的方法當前執行點相關的信息。一個線程僅能訪問自己的線程棧。一個線程創建的本地變量對其它線程不可見,僅自己可見。即使兩個線程執行同樣的代碼,這兩個線程任然在在自己的線程棧中的代碼來創建本地變量。因此,每個線程擁有每個本地變量的獨有版本。
所有原始類型的本地變量都存放在線程棧上,因此對其它線程不可見。一個線程可能向另一個線程傳遞一個原始類型變量的拷貝,但是它不能共享這個原始類型變量自身。
堆上包含在 Java 程序中創建的所有對象,無論是哪一個對象創建的。這包括原始類型的對象版本。如果一個對象被創建然后賦值給一個局部變量,或者用來作為另一個對象的成員變量,這個對象任然是存放在堆上。
一個本地變量可能是原始類型,在這種情況下,它總是在線程棧上。
一個本地變量也可能是指向一個對象的一個引用。在這種情況下,引用(這個本地變量)存放在線程棧上,但是對象本身存放在堆上。
一個對象可能包含方法,這些方法可能包含本地變量。這些本地變量任然存放在線程棧上,即使這些方法所屬的對象存放在堆上。
一個對象的成員變量可能隨著這個對象自身存放在堆上。不管這個成員變量是原始類型還是引用類型。
靜態成員變量跟隨著類定義一起也存放在堆上。
存放在堆上的對象可以被所有持有對這個對象引用的線程訪問。當一個線程可以訪問一個對象時,它也可以訪問這個對象的成員變量。如果兩個線程同時調用同一個對象上的同一個方法,它們將會都訪問這個對象的成員變量,但是每一個線程都擁有這個本地變量的私有拷貝。
現代硬件內存模型與 Java 內存模型有一些不同。理解內存模型架構以及 Java 內存模型如何與它協同工作也是非常重要的。這部分描述了通用的硬件內存架構,下面的部分將會描述 Java 內存是如何與它“聯手”工作的。
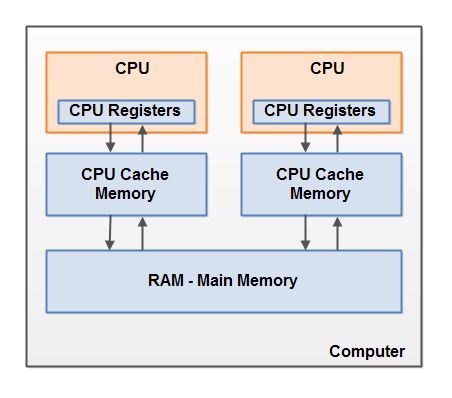
一個現代計算機通常由兩個或者多個 CPU。其中一些 CPU 還有多核。從這一點可以看出,在一個有兩個或者多個 CPU 的現代計算機上同時運行多個線程是可能的。每個 CPU 在某一時刻運行一個線程是沒有問題的。這意味著,如果你的 Java 程序是多線程的,在你的 Java 程序中每個 CPU 上一個線程可能同時(并發)執行。
每個 CPU 都包含一系列的寄存器,它們是 CPU 內內存的基礎。CPU 在寄存器上執行操作的速度遠大于在主存上執行的速度。這是因為 CPU 訪問寄存器的速度遠大于主存。
每個 CPU 可能還有一個 CPU 緩存層。實際上,絕大多數的現代 CPU 都有一定大小的緩存層。CPU 訪問緩存層的速度快于訪問主存的速度,但通常比訪問內部寄存器的速度還要慢一點。一些 CPU 還有多層緩存,但這些對理解 Java 內存模型如何和內存交互不是那么重要。只要知道 CPU 中可以有一個緩存層就可以了。
一個計算機還包含一個主存。所有的 CPU 都可以訪問主存。主存通常比 CPU 中的緩存大得多。
通常情況下,當一個 CPU 需要讀取主存時,它會將主存的部分讀到 CPU 緩存中。它甚至可能將緩存中的部分內容讀到它的內部寄存器中,然后在寄存器中執行操作。當 CPU 需要將結果寫回到主存中去時,它會將內部寄存器的值刷新到緩存中,然后在某個時間點將值刷新回主存。
當 CPU 需要在緩存層存放一些東西的時候,存放在緩存中的內容通常會被刷新回主存。CPU 緩存可以在某一時刻將數據局部寫到它的內存中,和在某一時刻局部刷新它的內存。它不會再某一時刻讀/寫整個緩存。通常,在一個被稱作“cache lines”的更小的內存塊中緩存被更新。一個或者多個緩存行可能被讀到緩存,一個或者多個緩存行可能再被刷新回主存。
上面已經提到,Java 內存模型與硬件內存架構之間存在差異。硬件內存架構沒有區分線程棧和堆。對于硬件,所有的線程棧和堆都分布在主內中。部分線程棧和堆可能有時候會出現在 CPU 緩存中和 CPU 內部的寄存器中。如下圖所示:
當對象和變量被存放在計算機中各種不同的內存區域中時,就可能會出現一些具體的問題。主要包括如下兩個方面:
線程對共享變量修改的可見性
當讀,寫和檢查共享變量時出現 race conditions
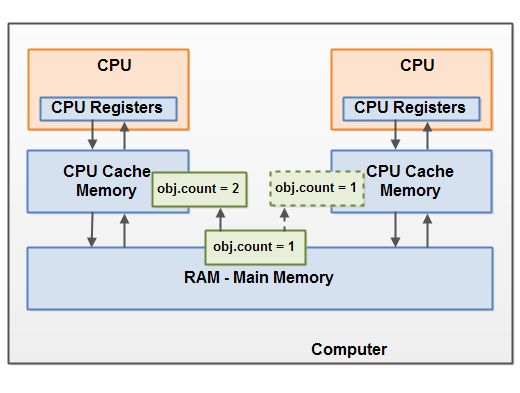
如果兩個或者更多的線程在沒有正確的使用 volatile 聲明或者同步的情況下共享一個對象,一個線程更新這個共享對象可能對其它線程來說是不接見的。
想象一下,共享對象被初始化在主存中。跑在 CPU 上的一個線程將這個共享對象讀到 CPU 緩存中。然后修改了這個對象。只要 CPU 緩存沒有被刷新會主存,對象修改后的版本對跑在其它 CPU 上的線程都是不可見的。這種方式可能導致每個線程擁有這個共享對象的私有拷貝,每個拷貝停留在不同的 CPU 緩存中。
上圖示意了這種情形。跑在左邊 CPU 的線程拷貝這個共享對象到它的 CPU 緩存中,然后將 count 變量的值修改為 2。這個修改對跑在右邊 CPU 上的其它線程是不可見的,因為修改后的 count 的值還沒有被刷新回主存中去。
解決這個問題你可以使用 Java 中的 volatile 關鍵字。volatile 關鍵字可以保證直接從主存中讀取一個變量,如果這個變量被修改后,總是會被寫回到主存中去。
如果兩個或者更多的線程共享一個對象,多個線程在這個共享對象上更新變量,就有可能發生 race conditions。
想象一下,如果線程 A 讀一個共享對象的變量 count 到它的 CPU 緩存中。再想象一下,線程 B 也做了同樣的事情,但是往一個不同的 CPU 緩存中。現在線程 A 將 count 加 1,線程 B 也做了同樣的事情。現在 count 已經被增在了兩個,每個 CPU 緩存中一次。
如果這些增加操作被順序的執行,變量 count 應該被增加兩次,然后原值+2 被寫回到主存中去。
然而,兩次增加都是在沒有適當的同步下并發執行的。無論是線程 A 還是線程 B 將 count 修改后的版本寫回到主存中取,修改后的值僅會被原值大 1,盡管增加了兩次。
解決這個問題可以使用 Java 同步塊。一個同步塊可以保證在同一時刻僅有一個線程可以進入代碼的臨界區。同步塊還可以保證代碼塊中所有被訪問的變量將會從主存中讀入,當線程退出同步代碼塊時,所有被更新的變量都會被刷新回主存中去,不管這個變量是否被聲明為 volatile。
JMM 為程序中所有的操作定義了一個偏序關系,稱之為 Happens-Before。
程序順序規則:如果程序中操作 A 在操作 B 之前,那么在線程中操作 A 將在操作 B 之前執行。
監視器鎖規則:在監視器鎖上的解鎖操作必須在同一個監視器鎖上的加鎖操作之前執行。
volatile 變量規則:對 volatile 變量的寫入操作必須在對該變量的讀操作之前執行。
線程啟動規則:在線程上對 Thread.start 的調用必須在該線程中執行任何操作之前執行。
線程結束規則:線程中的任何操作都必須在其他線程檢測到該線程已經結束之前執行,或者從 Thread.join 中成功返回,或者在調用 Thread.isAlive 時返回 false。
中斷規則:當一個線程在另一個線程上調用 interrupt 時,必須在被中斷線程檢測到 interrupt 調用之前執行(通過拋出 InterruptException,或者調用 isInterrupted 和 interrupted)。
終結器規則:對象的構造函數必須在啟動該對象的終結器之前執行完成。
傳遞性:如果操作 A 在操作 B 之前執行,并且操作 B 在操作 C 之前執行,那么操作 A 必須在操作 C 之前執行。
關于“Java內存模型原理是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





