溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“RabbitMQ和Kafka怎么保證消息隊列的可靠性傳輸”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“RabbitMQ和Kafka怎么保證消息隊列的可靠性傳輸”吧!
如何保證消息的可靠性傳輸?或者說,如何處理消息丟失的問題?
這個是肯定的,用 MQ 有個基本原則,就是數據不能多一條,也不能少一條,不能多,就是前面說的重復消費和冪等性問題。不能少,就是說這數據別搞丟了。那這個問題你必須得考慮一下。
如果說你這個是用 MQ 來傳遞非常核心的消息,比如說計費、扣費的一些消息,那必須確保這個 MQ 傳遞過程中絕對不會把計費消息給弄丟。
數據的丟失問題,可能出現在生產者、MQ、消費者中,咱們從 RabbitMQ 和 Kafka 分別來分析一下吧。
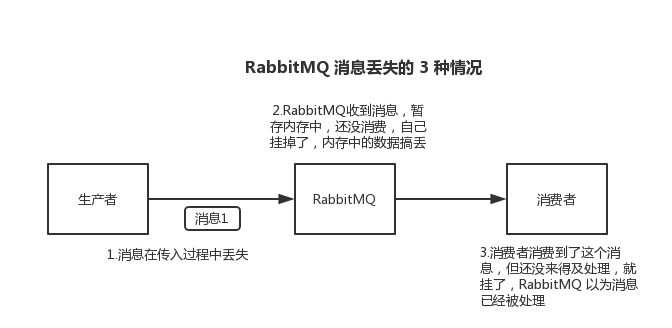
生產者將數據發送到 RabbitMQ 的時候,可能數據就在半路給搞丟了,因為網絡問題啥的,都有可能。
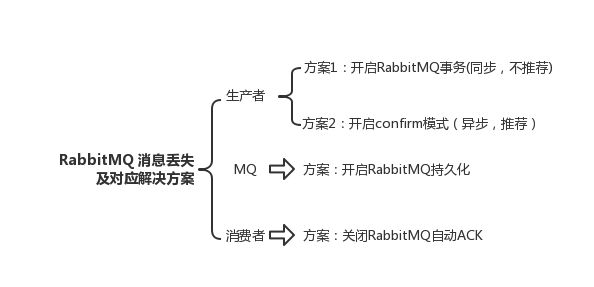
此時可以選擇用 RabbitMQ 提供的事務功能,就是生產者發送數據之前開啟 RabbitMQ 事務channel.txSelect,然后發送消息,如果消息沒有成功被 RabbitMQ 接收到,那么生產者會收到異常報錯,此時就可以回滾事務channel.txRollback,然后重試發送消息;如果收到了消息,那么可以提交事務channel.txCommit。
// 開啟事務
channel.txSelect
try {
// 這里發送消息
} catch (Exception e) {
channel.txRollback
// 這里再次重發這條消息
}
// 提交事務
channel.txCommit但是問題是,RabbitMQ 事務機制(同步)一搞,基本上吞吐量會下來,因為太耗性能。
所以一般來說,如果你要確保說寫 RabbitMQ 的消息別丟,可以開啟 confirm 模式,在生產者那里設置開啟 confirm 模式之后,你每次寫的消息都會分配一個唯一的 id,然后如果寫入了 RabbitMQ 中,RabbitMQ 會給你回傳一個 ack 消息,告訴你說這個消息 ok 了。如果 RabbitMQ 沒能處理這個消息,會回調你的一個 nack 接口,告訴你這個消息接收失敗,你可以重試。而且你可以結合這個機制自己在內存里維護每個消息 id 的狀態,如果超過一定時間還沒接收到這個消息的回調,那么你可以重發。
事務機制和 cnofirm 機制最大的不同在于,事務機制是同步的,你提交一個事務之后會阻塞在那兒,但是 confirm 機制是異步的,你發送個消息之后就可以發送下一個消息,然后那個消息 RabbitMQ 接收了之后會異步回調你的一個接口通知你這個消息接收到了。
所以一般在生產者這塊避免數據丟失,都是用 confirm 機制的。
就是 RabbitMQ 自己弄丟了數據,這個你必須開啟 RabbitMQ 的持久化,就是消息寫入之后會持久化到磁盤,哪怕是 RabbitMQ 自己掛了,恢復之后會自動讀取之前存儲的數據,一般數據不會丟。除非極其罕見的是,RabbitMQ 還沒持久化,自己就掛了,可能導致少量數據丟失,但是這個概率較小。
設置持久化有兩個步驟:
創建 queue 的時候將其設置為持久化
這樣就可以保證 RabbitMQ 持久化 queue 的元數據,但是它是不會持久化 queue 里的數據的。
第二個是發送消息的時候將消息的 deliveryMode 設置為 2
就是將消息設置為持久化的,此時 RabbitMQ 就會將消息持久化到磁盤上去。
必須要同時設置這兩個持久化才行,RabbitMQ 哪怕是掛了,再次重啟,也會從磁盤上重啟恢復 queue,恢復這個 queue 里的數據。
注意,哪怕是你給 RabbitMQ 開啟了持久化機制,也有一種可能,就是這個消息寫到了 RabbitMQ 中,但是還沒來得及持久化到磁盤上,結果不巧,此時 RabbitMQ 掛了,就會導致內存里的一點點數據丟失。
所以,持久化可以跟生產者那邊的 confirm 機制配合起來,只有消息被持久化到磁盤之后,才會通知生產者 ack 了,所以哪怕是在持久化到磁盤之前,RabbitMQ 掛了,數據丟了,生產者收不到 ack,你也是可以自己重發的。
RabbitMQ 如果丟失了數據,主要是因為你消費的時候,剛消費到,還沒處理,結果進程掛了,比如重啟了,那么就尷尬了,RabbitMQ 認為你都消費了,這數據就丟了。
這個時候得用 RabbitMQ 提供的 ack 機制,簡單來說,就是你必須關閉 RabbitMQ 的自動 ack,可以通過一個 api 來調用就行,然后每次你自己代碼里確保處理完的時候,再在程序里 ack 一把。這樣的話,如果你還沒處理完,不就沒有 ack 了?那 RabbitMQ 就認為你還沒處理完,這個時候 RabbitMQ 會把這個消費分配給別的 consumer 去處理,消息是不會丟的。
唯一可能導致消費者弄丟數據的情況,就是說,你消費到了這個消息,然后消費者那邊自動提交了 offset,讓 Kafka 以為你已經消費好了這個消息,但其實你才剛準備處理這個消息,你還沒處理,你自己就掛了,此時這條消息就丟咯。
這不是跟 RabbitMQ 差不多嗎,大家都知道 Kafka 會自動提交 offset,那么只要關閉自動提交offset,在處理完之后自己手動提交 offset,就可以保證數據不會丟。但是此時確實還是可能會有重復消費,比如你剛處理完,還沒提交 offset,結果自己掛了,此時肯定會重復消費一次,自己保證冪等性就好了。
生產環境碰到的一個問題,就是說我們的 Kafka 消費者消費到了數據之后是寫到一個內存的 queue 里先緩沖一下,結果有的時候,你剛把消息寫入內存 queue,然后消費者會自動提交 offset。然后此時我們重啟了系統,就會導致內存 queue 里還沒來得及處理的數據就丟失了。
這塊比較常見的一個場景,就是 Kafka 某個 broker 宕機,然后重新選舉 partition 的 leader。大家想想,要是此時其他的 follower 剛好還有些數據沒有同步,結果此時 leader 掛了,然后選舉某個 follower 成 leader 之后,不就少了一些數據?這就丟了一些數據啊。
生產環境也遇到過,我們也是,之前 Kafka 的 leader 機器宕機了,將 follower 切換為 leader 之后,就會發現說這個數據就丟了。
所以此時一般是要求起碼設置如下 4 個參數:
給 topic 設置 replication.factor 參數:這個值必須大于 1,要求每個 partition 必須有至少 2 個副本。
在 Kafka 服務端設置 min.insync.replicas 參數:這個值必須大于 1,這個是要求一個 leader 至少感知到有至少一個 follower 還跟自己保持聯系,沒掉隊,這樣才能確保 leader 掛了還有一個 follower 吧。
在 producer 端設置 acks=all:這個是要求每條數據,必須是寫入所有 replica 之后,才能認為是寫成功了。
在 producer 端設置 retries=MAX(很大很大很大的一個值,無限次重試的意思):這個是要求一旦寫入失敗,就無限重試,卡在這里了。
我們生產環境就是按照上述要求配置的,這樣配置之后,至少在 Kafka broker 端就可以保證在 leader 所在 broker 發生故障,進行 leader 切換時,數據不會丟失。
如果按照上述的思路設置了 acks=all,一定不會丟,要求是,你的 leader 接收到消息,所有的 follower 都同步到了消息之后,才認為本次寫成功了。如果沒滿足這個條件,生產者會自動不斷的重試,重試無限次。
到此,相信大家對“RabbitMQ和Kafka怎么保證消息隊列的可靠性傳輸”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





