溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Java內存模型volatile的內存語義是什么”,在日常操作中,相信很多人在Java內存模型volatile的內存語義是什么問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Java內存模型volatile的內存語義是什么”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
理解volatile特性的一個好辦法是把對volatile變量的單個讀/寫,看成是使用同一個鎖對單個讀/寫操作做了同步。
代碼示例:
package com.lizba.p1;
/**
* <p>
* volatile示例
* </p>
*
* @Author: Liziba
* @Date: 2021/6/9 21:34
*/
public class VolatileFeatureExample {
/** 使用volatile聲明64位的long型變量 */
volatile long v1 = 0l;
/**
* 單個volatile寫操作
* @param l
*/
public void set(long l) {
v1 = l;
}
/**
* 復合(多個)volatile讀&寫
*/
public void getAndIncrement() {
v1++;
}
/**
* 單個volatile變量的讀
* @return
*/
public long get() {
return v1;
}
}假設有多個線程分別調用上面程序的3個方法,這個程序在語義上和下面程序等價。
package com.lizba.p1;
/**
* <p>
* synchronized等價示例
* </p>
*
* @Author: Liziba
* @Date: 2021/6/9 21:46
*/
public class SynFeatureExample {
/** 定義一個64位長度的普通變量 */
long v1 = 0L;
/**
* 使用同步鎖對v1變量進行寫操作
* @param l
*/
public synchronized void set(long l) {
v1 = l;
}
/**
* 通過同步讀和同步寫方法對v1進行+1操作
*/
public void getAndIncrement() {
long temp = get();
// v1加一
temp += 1L;
set(temp);
}
/**
* 使用同步鎖對v1進行讀操作
* @return
*/
public synchronized long get() {
return v1;
}
}如上兩個程序所示,一個volatile變量的單個讀\寫操作,與一個普通變量的讀\寫操作都是使用同一個鎖來同步,它們之間的執行效果相同。
上述代碼總結:
鎖的happens-before規則保證釋放鎖和獲取鎖的兩個線程之間的內存可見性,這意味著對一個volatile變量的讀,總能看到(任意線程)對這個volatile變量最后的寫入。
鎖的語義決定了臨界區代碼的執行具有原子性。這意味著,即使是64位的long型和double型變量,只要它是volatile變量,對該變量的讀/寫就具有原子性。如果是多個volatile操作或類似于volatile++這種復合操作,這些操作整體上不具備原子性。
總結volatile特性:
可見性。對一個volatile變量的讀,總是能看到(任意線程)對這個volatile變量最后的寫入。
原子性。對任意volatile變量的讀/寫具有原子性,但類似volatile++這種復合操作不具有原子性。
對于程序員來說,我們更加需要關注的是volatile對線程內存的可見性。
從JDK1.5(JSR-133)開始,volatile變量的寫-讀可以實現線程之間的通信。從內存語義的角度來說,volatile的寫-讀與鎖的釋放-獲取有相同的內存效果。
volatile的寫和鎖的釋放有相同的內存語義
volatile的讀和鎖的獲取有相同的內存語義
代碼示例:
package com.lizba.p1;
/**
* <p>
*
* </p>
*
* @Author: Liziba
* @Date: 2021/6/9 22:23
*/
public class VolatileExample {
int a = 0;
volatile boolean flag = false;
public void writer() {
a = 1; // 1
flag = true; // 2
}
public void reader() {
if (flag) { // 3
int i = a; // 4
System.out.println(i);
}
}
}假設線程A執行writer()方法之后,線程B執行reader()方法。根據happens-before規則,
這個過程建立的happens-before關系如下:
根據程序次序規則,1 happens-before 2, 3 happens-before 4。
根據volatile規則,2 happens-before 3。
根據happens-before的傳遞性規則,1 happens-before 4。
圖示上述happens-before關系:
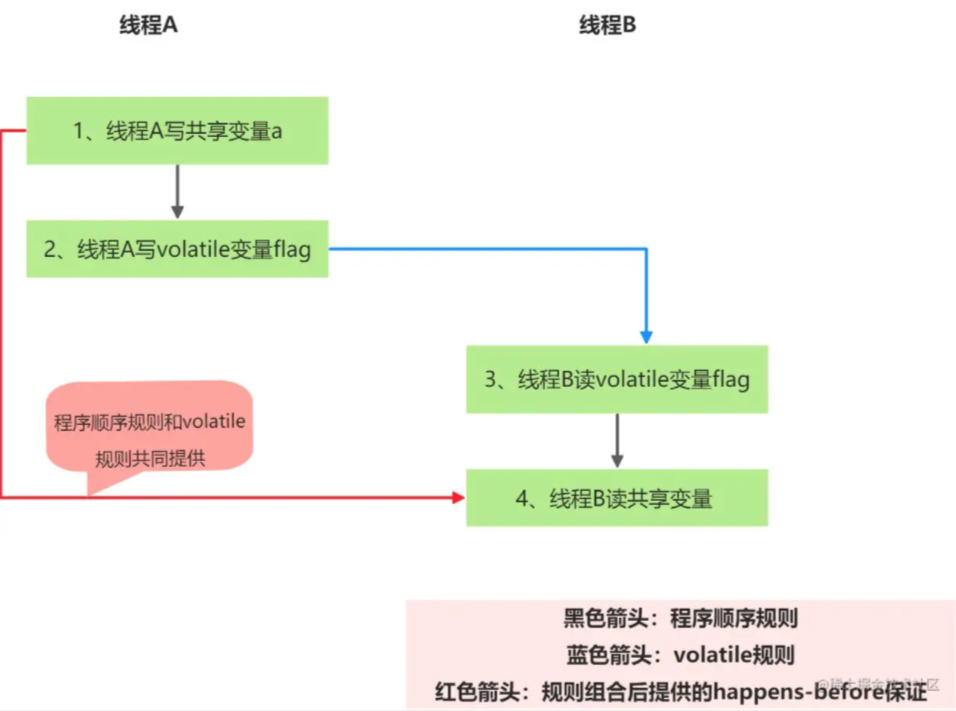
總結:這里A線程寫一個volatile變量后,B線程讀同一個volatile變量。A線程在寫volatile變量之前所有可見的共享變量,在B線程讀同一個volatile變量后,將立即對B線程可見。
volatile寫的內存語義
當寫一個volatile變量時,JMM會把該線程對應的本地內存中的共享變量值刷新到主內存。
以上面的VolatileExample為例,假設A線程首先執行writer()方法,隨后線程B執行reader()方法,初始時兩個線程的本地內存中的flag和a都是初始狀態。
A執行volatile寫后,共享變量狀態示意圖。
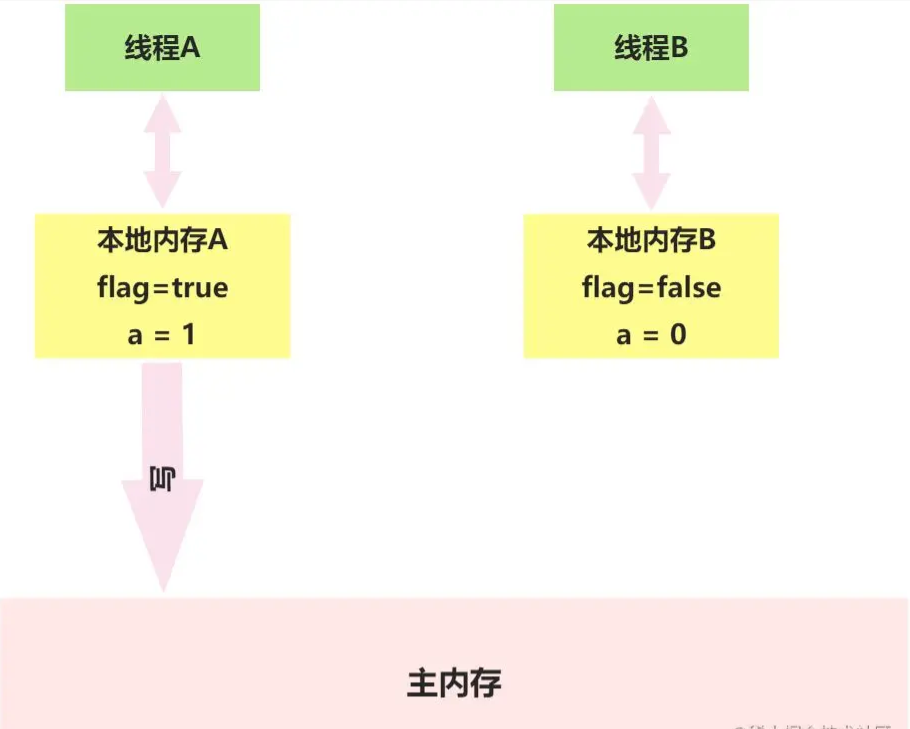
線程A在寫flag變量后,本地內存A中被線程A更新過的兩個共享變量的值被刷新到主內存中,此時A的本地內存和主內存中的值是一致的。
volatile讀的內存語義
當讀一個volatile變量時,JMM會把該線程對應的本地內存置為無效。線程接下來將會從主內存中讀取共享變量。
B執行volatile讀后,共享變量的狀態示意圖:
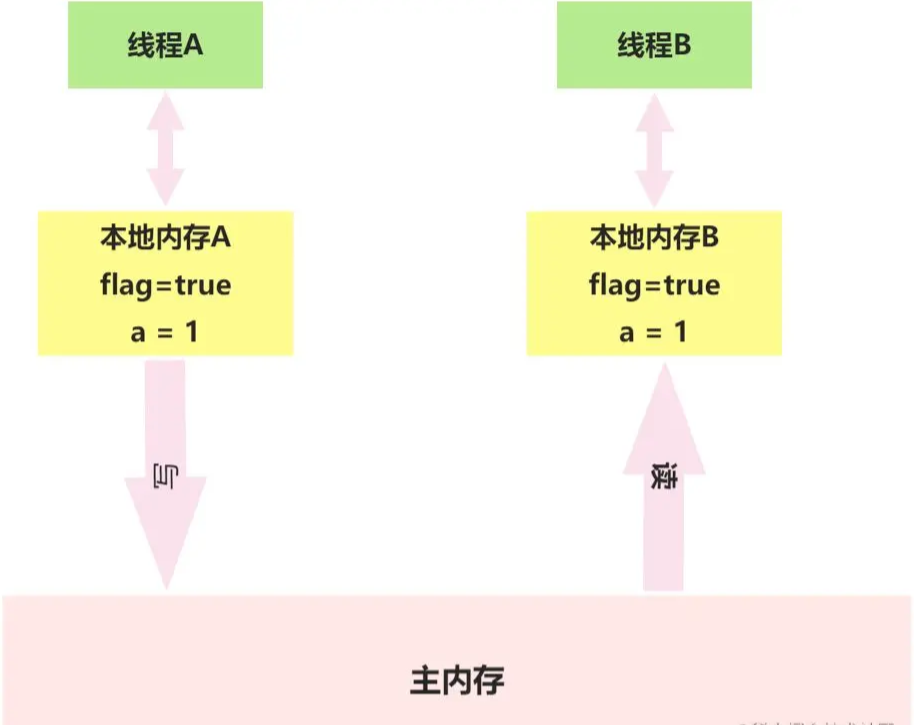
在讀flag變量后,本地內存B包含的值已經被置為無效。此時,線程B必須從主內存中重新讀取共享變量。線程B的讀取操作將導致本地內存B與主內存中的共享變量的值變為一致。
總結volatile的寫和volatile讀的內存語義
線程A寫一個volatile變量,實質上是線程A向接下來將要讀這個volatile變量的某個線程發出了(其對共享變量所做修改的)消息。
線程B讀一個volatile變量,實質上是線程B接收了之前某個線程發出的(在寫這個volatile變量之前對共享變量所做修改的)消息。
線程A寫一個volatile變量,隨后線程B讀這個volatile變量,這個過程實質上是線程A通過主內存向線程B發送消息。
程序的重排序分為編譯器重排序和處理器重排序(我的前面的博文內容有寫哈)。為了實現volatile內存語義,JMM會分別禁止這兩種類型的重排序。
volatile重排序規則表:
| 是否能重排序 | 第二個操作 | ||
|---|---|---|---|
| 第一個操作 | 普通讀/寫 | volatile讀 | volatile寫 |
| 普通讀/寫 | NO | ||
| volatile讀 | NO | NO | NO |
| volatile寫 | NO | NO |
上圖舉例:第一行最后一個單元格意思是,在程序中第一個操作為普通讀/寫時,如果第二個操作為volatile寫,則編譯器不能重排序。
總結上圖:
第二個操作是volatile寫時,都不能重排序。確保volatile寫之前的操作不會被編譯器重排序到volatile之后
第一個操作為volatile讀時,都不能重排序。確保volatile讀之后的操作不會被編譯器重排序到volatile之前
第一個操作為volatile寫,第二個操作為volatile讀時,不能重排序。
為了實現volatile的內存語義,編譯器在生成字節碼時,會在指令序列中插入內存屏障來禁止特定類型的處理器重排序。
JMM采取的是保守策略內存屏障插入策略,如下:
在每個volatile寫操作屏障前面插入一個StoreStore屏障。
在每個volatile寫操作的后面插入一個StoreLoad屏障
在每個volatile讀操作的后面插入一個LoadLoad屏障。
在每個volatile讀操作的后面插入一個LoadStore屏障。
保守策略可以保證在任意處理器平臺上,任意程序中都能得到正確的volatile內存語義。
保守策略下,volatile寫插入內存屏障后生成的指令序列圖:

解釋:
StoreStore屏障可以保證在volatile寫之前,其前面所有普通寫操作已經對任意處理器可見了。這是因為StoreStore屏障將保障上面所有普通寫在volatile寫之前刷新到主內存。
保守策略下,volatile讀插入內存屏障后生成的指令序列圖:
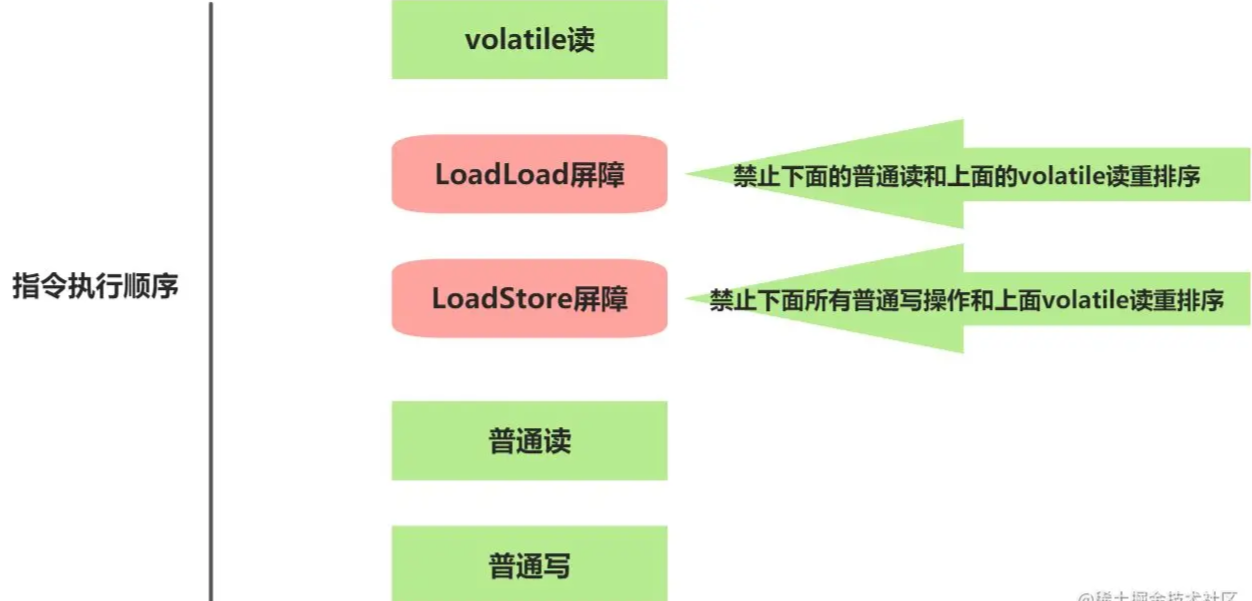
解釋:
LoadLoad屏障用來禁止處理器把上面的volatile讀與下面的普通讀重排序。LoadStore屏障用來禁止處理器把上面的volatile讀與下面的普通寫重排序。
上述volatile寫和volatile讀的內存屏障插入策略非常保守。在實際執行時,只要不改變volatile寫-讀的內存語義,編譯器可以根據具體情況省略不必要的屏障。
代碼示例:
package com.lizba.p1;
/**
* <p>
* volatile屏障示例
* </p>
*
* @Author: Liziba
* @Date: 2021/6/9 23:48
*/
public class VolatileBarrierExample {
int a;
volatile int v1 = 1;
volatile int v2 = 2;
void readAndWrite() {
// 第一個volatile讀
int i = v1;
// 第二個volatile讀
int j = v2;
// 普通寫
a = i + j;
// 第一個volatile寫
v1 = i + 1;
// 第二個volatile寫
v2 = j * 2;
}
// ... 其他方法
}針對VolatileBarrierExample的readAndWrite(),編譯器生成字節碼時可以做如下優化:
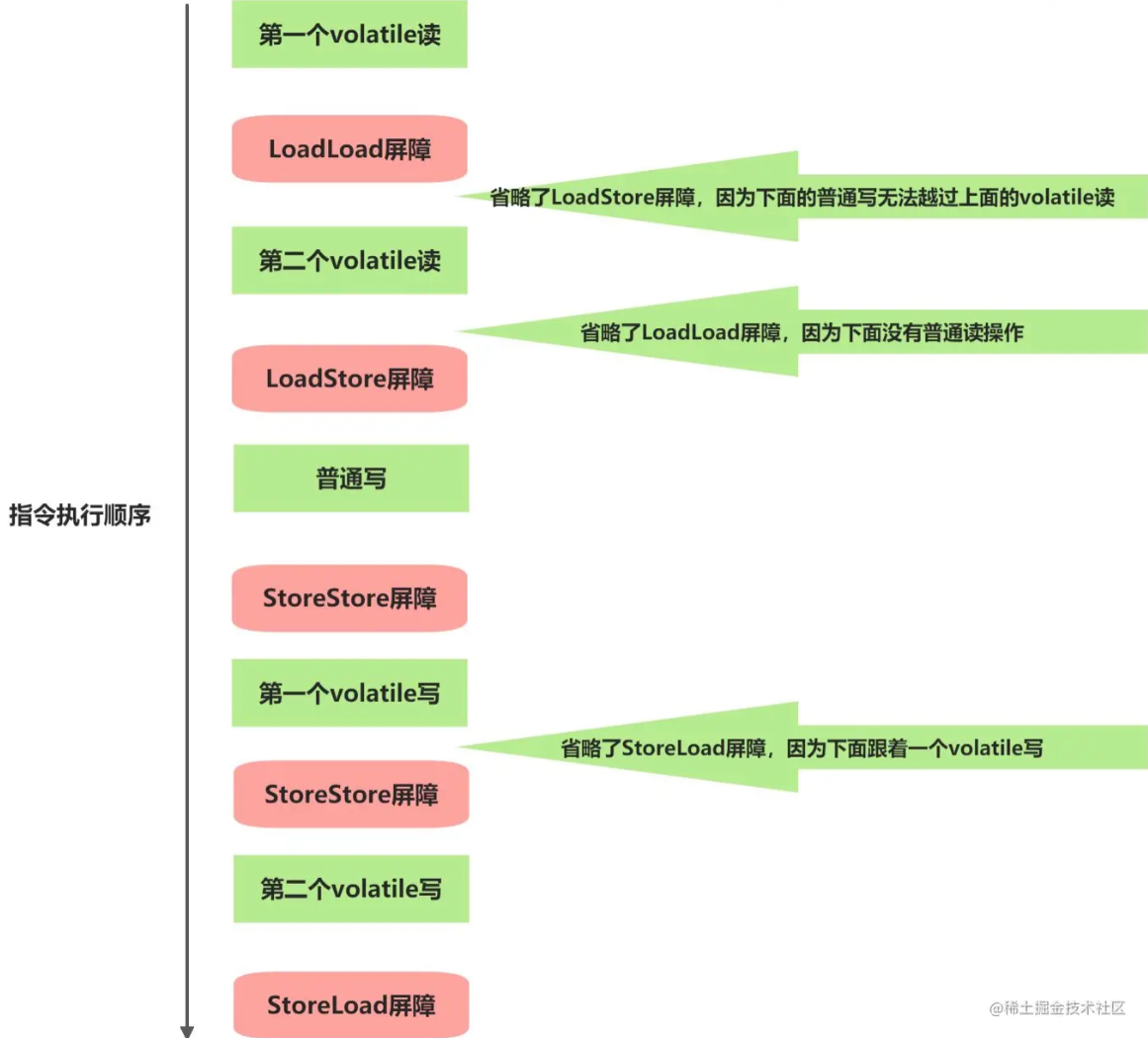
注意:最后的StoreLoad屏障無法省略。因為第二個volatile寫之后,程序return。此時編譯器無法準確斷定后面是否會有volatile讀寫操作,為了安全起見,編譯器通常會在這里插入一個StoreLoad屏障。
上面的優化可以針對任意處理器平臺,但是由于不同的處理器有不同的“松緊度”的處理器內存模型,內存屏障的插入還可以根據具體的處理器內存模型繼續優化。
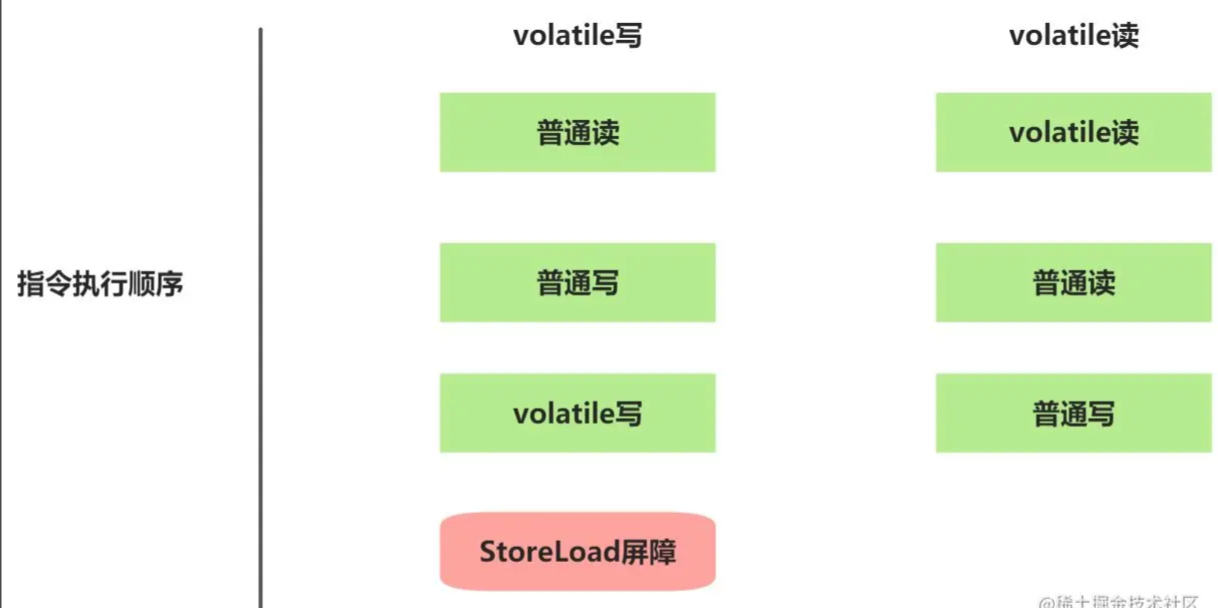
X86處理器平臺優化
X86處理器僅會對寫-讀操作做重排序。X86不會對讀-讀、讀-寫和寫-寫重排序,因此X86處理器會省略掉這3種操作類型對應的內存屏障。在X86平臺中,JMM僅需要在volatile寫后插入一個StoreLoad屏障即可正確實現volatile寫-讀內存語義。同時這樣意味著X86處理器中,volatile寫的開銷會遠遠大于讀的開銷。
功能上:
鎖比
volatile更強大可伸縮性和執行性能上:
volatile更具有優勢
到此,關于“Java內存模型volatile的內存語義是什么”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





