溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Kafka生產者與可靠性保證ACK的方法有哪些”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
消息發送的整體流程,生產端主要由兩個線程協調運行。分別是main線程和sender線程(發送線程)。
在Kafka(2.6.0版本)源碼中,可以看到。
源碼地址: kafka\clients\src\main\java\org.apache.kafka.clients.producer.KafkaProducer.java 測試入口: KafkaProducerTest.testInvalidGenerationIdAndMemberIdCombinedInSendOffsets()
在創建KafkaProducer時,在430創建了一個Sender對象,并且啟動了一個IO線程。
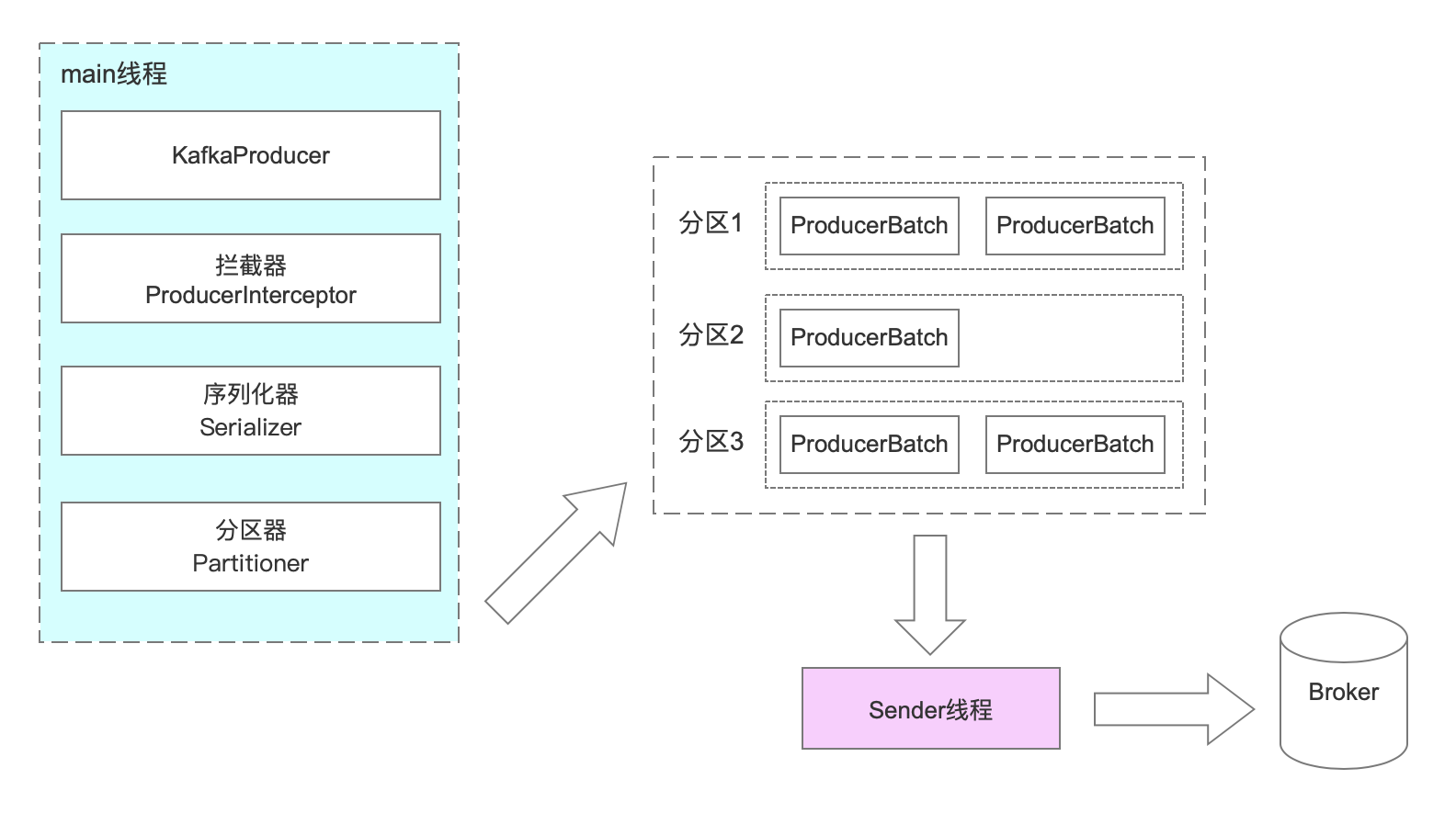
this.errors = this.metrics.sensor("errors");
this.sender = newSender(logContext, kafkaClient, this.metadata);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();interceptor的作用是實現消息的定制化,類似:spring Interceptor 、MyBatis的插件、Quartz的監聽器。
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}可通過實現org.apache.kafka.clients.producer.ProducerInterceptor接口開發自定義器。
簡單自定義例子:
public class CustomInterceptor implements ProducerInterceptor<String, String> {
// 發送消息時觸發
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
System.out.println("發送消息時觸發");
return record;
}
// 收到服務端的ACK時觸發
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
System.out.println("消息被服務端接收");
}
@Override
public void close() {
System.out.println("生產者關閉");
}
// 用鍵值對配置時觸發
@Override
public void configure(Map<String, ?> configs) {
System.out.println("configure...");
}
}
// 生產者中添加
List<String> interceptors = new ArrayList<>();
interceptors.add("com.freecloud.plug.kafka.interceptor.CustomInterceptor");
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}
在kafka針對不同的數據類型做了相應的序列化工具。如需自定義實現org.apache.kafka.common.serialization.Serializer接口。
int partition = partition(record, serializedKey, serializedValue, cluster);
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);
// RecordAccumulator本質是一個ConcurrentMap:
private final ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches;
一個partition一個Batch。batch滿了之后,會喚醒Sender線程發送消息。
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}生產者發送一條消息到服務器如何確保服務器收到消息?如果在發送過程中網絡出了問題,或者kafka服務器接收的時候出了問題,這個消息發送失敗了,生產者是不知道的。
所以kafka服務端需要使用一種響應客戶端的方式,只有在服務端確認以后,生產者才發一下條消息,否則重新發送數據。
那什么時候才算接收成功?因為消息存儲在不同的broker里,所以是在寫入到磁盤之后響應生產者。
在分布式場景中,只有一個broker寫入成功還是不夠的,如果有多個副本,follower也要寫入成功才行。
服務端發送ACK給生產者一般有以下幾種策略。
只要leader成功接收就可以,會產生副本與leader不一致情況,如果leader出問題可能會出現數據丟失風險。客戶端等待時間最短。
需要半數以上的follower節點完成同步,這種方式客戶端等待的時間比上邊稍長一點,但可以確保大部分場景不出問題。
需要所有follwer全部完成同步,客戶端等待時間最長,但如果節點掛掉的影響相對來說最小,因為所有節點的數據都是完整的。
kafka的ACK應答機制就使用了以上三種方式。可以通過配置acks參數進行配置。
上邊第三種方式如果保證所有follower同步數據成功?
假設leader接收到數據,所有follower都開始同步數據,但是有一個follower出了問題,沒辦法從leader同步數據,按這個規則,leader就要一直等待,無法返回ack,成了害群之馬。
所以我們該如果解決這個問題呢?接下來我們把規則修改一下,不是所有follower都有權利讓leader等待,而是只有那些正常工作的follower同步數據的時候才會等待。
把那些正常和leader保持同步的副本維護起來,放到一個動態set里,這個就叫做in-sync replica set (ISR)。只要ISR里面的follower同步完數據之后,就可以給客戶端發送ACK。
對于經常出問題的follower可以設定replica.lag.time.max.ms=30(默認30秒),如果超過配置時間才會從isr中剔除。
| 參數 | 說明 |
|---|---|
| acks = 0 | Producer不等待broker的ack,brokder一接收到還沒寫入磁盤就返回,當brokder故障時有可能丟失數據; |
| acks = 1 | Producer等待brokder的ack,partition的leader成功落盤后返回ack,如果在follower同步成功前leader故障,將會丟失數據; |
| acks = -1 | producer等待brokder的ack,partition的leader和follower全部成功落盤后才返回ack; |
以上三種機制性能依次遞減(producer吞吐量降低),數據健壯性則依次遞增。實際開發中可根據不同場景選擇不同的策略。
“Kafka生產者與可靠性保證ACK的方法有哪些”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





