溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關基于 Spark 的數據分析實踐是怎樣進行的,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
引言:
Spark是在借鑒了MapReduce之上發展而來的,繼承了其分布式并行計算的優點并改進了MapReduce明顯的缺陷。Spark主要包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等組件。
下面主要分析了 Spark RDD 以及 RDD 作為開發的不足之處,介紹了 SparkSQL 對已有的常見數據系統的操作方法,以及重點介紹了普元在眾多數據開發項目中總結的基于 SparkSQL Flow 開發框架。
RDD(Resilient Distributed Dataset)叫做彈性分布式數據集,是Spark中最基本的數據抽象,它代表一個不可變、可分區、元素可并行計算的集合。
RDD具有數據流模型的特點:自動容錯、位置感知性調度和可伸縮性。
//Scala 在內存中使用列表創建
val lines = List(“A”, “B”, “C”, “D” …) val rdd:RDD = sc.parallelize(lines);
//以文本文件創建
val rdd:RDD[String] = sc.textFile(“hdfs://path/filename”)
Spark RDD Partition 分區劃分
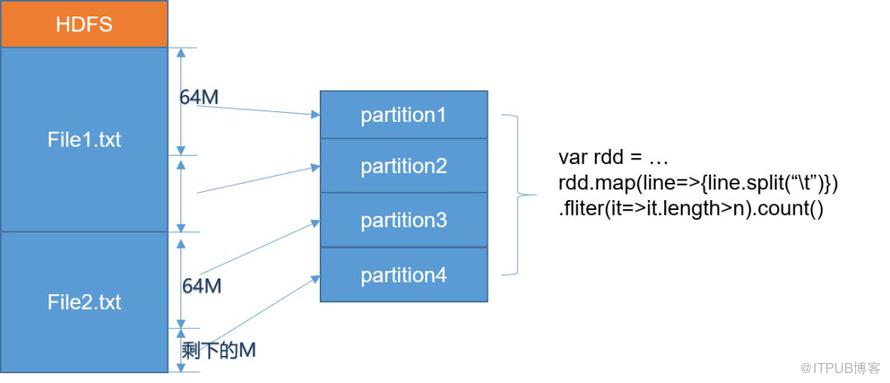
新版本的 Hadoop 已經把 BlockSize 改為 128M,也就是說每個分區處理的數據量更大。
Spark 讀取文件分區的核心原理
本質上,Spark 是利用了 Hadoop 的底層對數據進行分區的 API(InputFormat):
public abstract class InputFormat<K,V>{
public abstract List<InputSplit> getSplits(JobContextcontext
) throwsIOException,InterruptedException;
public abstract RecordReader<K,V> createRecordReader(InputSplitsplit,
TaskAttemptContextcontext
)throwsIOException,InterruptedException;
}Spark 任務提交后通過對輸入進行 Split,在 RDD 構造階段,只是判斷是否可 Split(如果參數異常一定在此階段報出異常),并且 Split 后每個 InputSplit 都是一個分區。只有在Action 算子提交后,才真正用 getSplits 返回的 InputSplit 通過 createRecordReader 獲得每個 Partition 的連接。
然后通過 RecordReader 的 next() 遍歷分區內的數據。
Spark RDD 轉換函數和提交函數

Spark RDD 的眾多函數可分為兩大類Transformation 與 Action。Transformation 與 Action 的區別在于,對 RDD 進行 Transformation 并不會觸發計算:Transformation 方法所產生的 RDD 對象只會記錄住該 RDD 所依賴的 RDD 以及計算產生該 RDD 的數據的方式;只有在用戶進行 Action 操作時,Spark 才會調度 RDD 計算任務,依次為各個 RDD 計算數據。這就是 Spark RDD 內函數的“懶加載”特性。
由于MapReduce的shuffle過程需寫磁盤,比較影響性能;而Spark利用RDD技術,計算在內存中流式進行。另外 MapReduce計算框架(API)比較局限, 使用需要關注的參數眾多,而Spark則是中間結果自動推斷,通過對數據集上鏈式執行函數具備一定的靈活性。
即使 SparkRDD 相對于 MapReduce 提高很大的便利性,但在使用上仍然有許多問題。體現在一下幾個方面:
RDD 函數眾多,開發者不容易掌握,部分函數使用不當 shuffle時造成數據傾斜影響性能;
RDD 關注點仍然是Spark太底層的 API,基于 Spark RDD的開發是基于特定語言(Scala,Python,Java)的函數開發,無法以數據的視界來開發數據;
對 RDD 轉換算子函數內部分常量、變量、廣播變量使用不當,會造成不可控的異常;
對多種數據開發,需各自開發RDD的轉換,樣板代碼較多,無法有效重利用;
其它在運行期可能發生的異常。如:對象無法序列化等運行期才能發現的異常。
Spark 從 1.3 版本開始原有 SchemaRDD 的基礎上提供了類似Pandas DataFrame API。新的DataFrame API不僅可以大幅度降低普通開發者的學習門檻,同時還支持Scala、Java與Python三種語言。更重要的是,由于脫胎自SchemaRDD,DataFrame天然適用于分布式大數據場景。
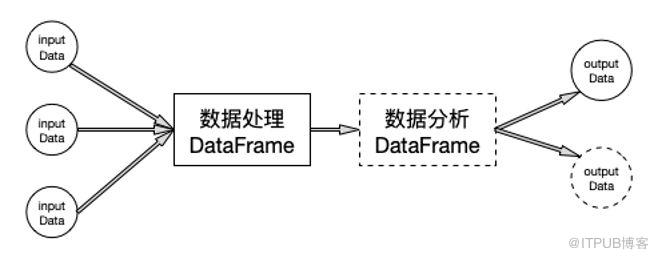
一般的數據處理步驟:讀入數據 -> 對數據進行處理 -> 分析結果 -> 寫入結果
SparkSQL 結構化數據
處理結構化數據(如 CSV,JSON,Parquet 等);
把已經結構化數據抽象成 DataFrame (HiveTable);
非結構化數據通過 RDD.map.filter 轉換成結構化進行處理;
按照列式數據庫,只加載非結構化中可結構化的部分列(Hbase,MongoDB);
處理非結構化數據,不能簡單的用 DataFrame 裝載。而是要用 SparkRDD 把數據讀入,在通過一系列的 Transformer Method 把非結構化的數據加工為結構化,或者過濾到不合法的數據。
SparkSQL DataFrame

SparkSQL 中一切都是 DataFrame,all in DataFrame. DataFrame是一種以RDD為基礎的分布式數據集,類似于傳統數據庫中的二維表格。DataFrame與RDD的主要區別在于,前者帶有schema元信息,即DataFrame所表示的二維表數據集的每一列都帶有名稱和類型。如果熟悉 Python Pandas 庫中的 DataFrame 結構,則會對 SparkSQL DataFrame 概念非常熟悉。
TextFile DataFrame
import.org.apache.spark.sql._
//定義數據的列名稱和類型
valdt=StructType(List(id:String,name:String,gender:String,age:Int))
//導入user_info.csv文件并指定分隔符
vallines = sc.textFile("/path/user_info.csv").map(_.split(","))
//將表結構和數據關聯起來,把讀入的數據user.csv映射成行,構成數據集
valrowRDD = lines.map(x=>Row(x(0),x(1),x(2),x(3).toInt))
//通過SparkSession.createDataFrame()創建表,并且數據表表頭
val df= spark.createDataFrame(rowRDD, dt)讀取規則數據文件作為DataFrame
SparkSession.Builder builder = SparkSession.builder()
Builder.setMaster("local").setAppName("TestSparkSQLApp")
SparkSession spark = builder.getOrCreate();
SQLContext sqlContext = spark.sqlContext();
# 讀取 JSON 數據,path 可為文件或者目錄
valdf=sqlContext.read().json(path);
# 讀取 HadoopParquet 文件
vardf=sqlContext.read().parquet(path);
# 讀取 HadoopORC 文件
vardf=sqlContext.read().orc(path);JSON 文件為每行一個 JSON 對象的文件類型,行尾無須逗號。文件頭也無須[]指定為數組;SparkSQL 讀取是只是按照每行一條 JSON Record序列化;
Parquet文件
Configurationconfig = new Configuration();
ParquetFileReaderreader = ParquetFileReader.open(
HadoopInputFile.fromPath(new Path("hdfs:///path/file.parquet"),conf));
Map<String, String>schema = reader.getFileMetaData().getKeyValueMetaData();
String allFields= schema.get("org.apache.spark.sql.parquet.row.metadata");allFiedls 的值就是各字段的名稱和具體的類型,整體是一個json格式進行展示。
讀取 Hive 表作為 DataFrame
Spark2 API 推薦通過 SparkSession.Builder 的 Builder 模式創建 SparkContext。 Builder.getOrCreate() 用于創建 SparkSession,SparkSession 是 SparkContext 的封裝。
在Spark1.6中有兩個核心組件SQLcontext和HiveContext。SQLContext 用于處理在 SparkSQL 中動態注冊的表,HiveContext 用于處理 Hive 中的表。
從Spark2.0以上的版本開始,spark是使用全新的SparkSession接口代替Spark1.6中的SQLcontext和HiveContext。SQLContext.sql 即可執行 Hive 中的表,也可執行內部注冊的表;
在需要執行 Hive 表時,只需要在 SparkSession.Builder 中開啟 Hive 支持即可(enableHiveSupport())。
SparkSession.Builder builder = SparkSession.builder().enableHiveSupport(); SparkSession spark = builder.getOrCreate(); SQLContext sqlContext = spark.sqlContext();
// db 指 Hive 庫中的數據庫名,如果不寫默認為 default
// tableName 指 hive 庫的數據表名
sqlContext.sql(“select * from db.tableName”)
SparkSQL ThriftServer
//首先打開 Hive 的 Metastore服務
hive$bin/hive –-service metastore –p 8093
//把 Spark 的相關 jar 上傳到hadoophdfs指定目錄,用于指定sparkonyarn的依賴 jar
spark$hadoop fs –put jars/*.jar /lib/spark2
// 啟動 spark thriftserver 服務
spark$ sbin/start-thriftserver.sh --master yarn-client --driver-memory 1G --conf spark.yarn.jars=hdfs:///lib/spark2/*.jar
當hdfs 上傳了spark 依賴 jar 時,通過spark.yarn.jars 可看到日志 spark 無須每個job 都上傳jar,可節省啟動時間
19/06/1114:08:26 INFO Client: Source and destination file systems are the same. Notcopying hdfs://localhost:9000/lib/spark2/snappy-java-1.0.5.jar 19/06/1114:08:26 INFO Client: Source and destination file systems are the same. Notcopying hdfs://localhost:9000/lib/spark2/snappy-java-1.1.7.3.jar
//通過 spark bin 下的 beeline 工具,可以連接到 spark ThriftServer(SparkOnHive)
bin/beeline -u jdbc:hive2://ip:10000/default -n hadoop
-u 是指定 beeline 的執行驅動地址;
-n 是指定登陸到 spark Session 上的用戶名稱;
Beeline 還支持傳入-e 可傳入一行 SQL,
-e <query> query that should be executed
也可通過 –f 指定一個 SQL File,內部可用逗號分隔的多個 SQL(存儲過程)
-f <exec file> script file that should be executed
SparkSQL Beeline 的執行效果展示
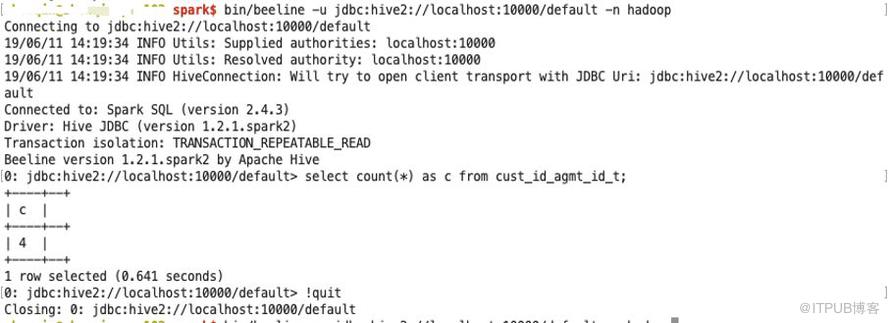
SparkSQL ThriftServer
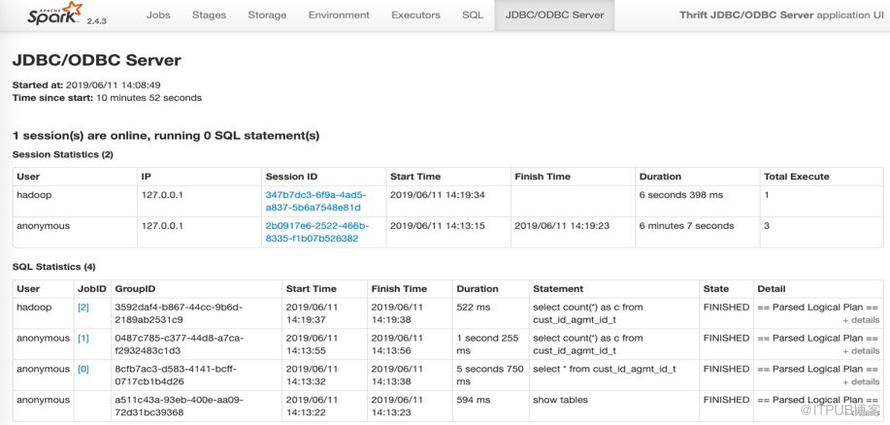
對于 SparkSQL ThriftServer 服務,每個登陸的用戶都有創建的 SparkSession,并且執行的對個 SQL 會通過時間順序列表展示。
SparkSQL ThriftServer 服務可用于其他支持的數據庫工具創建查詢,也用于第三方的 BI 工具,如 tableau。
SparkSQL Flow 是以 SparkSQL 為基礎,開發的統一的基于 XML 配置化的可執行一連串的 SQL 操作,這一連串的 SQL 操作定義為一個 Flow。下文開始 SparkSQL Flow 的介紹:
SparkSQL Flow 是基于 SparkSQL 開發的一種基于 XML 配置化的 SQL 數據流轉處理模型。該模型簡化了 SparkSQL 、Spark RDD的開發,并且降低開發了難度,適合了解數據業務但無法駕馭大數據以及 Spark 技術的開發者。
一個由普元技術部提供的基于 SparkSQL 的開發模型;
一個可二次定制開發的大數據開發框架,提供了靈活的可擴展 API;
一個提供了 對文件,數據庫,NoSQL 等統一的數據開發視界語義;
基于 SQL 的開發語言和 XML 的模板配置,支持 Spark UDF 的擴展管理;
支持基于 Spark Standlone,Yarn,Mesos 資源管理平臺;
支持開源、華為、星環等平臺統一認證。
SparkSQL Flow 適合的場景:
批量 ETL;
非實時分析服務;
SparkSQL Flow XML 概覽

Properties 內定義一組變量,可用于宏替換;
Methods 內可注冊 udf 和 udaf 兩種函數;
Prepare 內可定義前置 SQL,用于執行 source 前的 sql 操作;
Sources 內定義一個到多個數據表視圖;
Transformer 內可定義 0 到多個基于 SQL 的數據轉換操作(支持 join);
Targets 用于定義 1 到多個數據輸出;
After 可定義 0到多個任務日志;
如你所見,source 的 type 參數用于區分 source 的類型,source 支持的種類直接決定SparkSQL Flow 的數據源加載廣度;并且,根據 type 不同,source 也需要配置不同的參數,如數據庫還需要 driver,url,user和 password 參數。
Transformer 是基于 source 定的數據視圖可執行的一組轉換 SQL,該 SQL 符合 SparkSQL 的語法(SQL99)。Transform 的 SQL 的執行結果被作為中間表命名為 table_name 指定的值。
Targets 為定義輸出,table_name 的值需在 source 或者 Transformer 中定義。
SparkSQL Flow 支持的Sourse

支持從 Hive 獲得數據;
支持文件:JSON,TextFile(CSV),ParquetFile,AvroFile
支持RDBMS數據庫:PostgreSQL, MySQL,Oracle
支持 NOSQL 數據庫:Hbase,MongoDB
SparkSQL Flow TextFile Source
textfile 為讀取文本文件,把文本文件每行按照 delimiter 指定的字符進行切分,切分不夠的列使用 null 填充。
<source type="textfile" table_name="et_rel_pty_cong" fields="cust_id,name1,gender1,age1:int" delimiter="," path="file:///Users/zhenqin/software/hive/user.txt"/>
Tablename 為該文件映射的數據表名,可理解為數據的視圖;
Fields 為切分后的字段,使用逗號分隔,字段后可緊跟該字段的類型,使用冒號分隔;
Delimiter 為每行的分隔符;
Path 用于指定文件地址,可以是文件,也可是文件夾;
Path 指定地址需要使用協議,如:file:// 、 hdfs://,否則跟 core-site.xml 配置密切相關;
SparkSQL Flow DB Source
<source type="mysql" table_name="et_rel_pty_cong" table="user" url="jdbc:mysql://localhost:3306/tdb?characterEncoding=UTF-8" driver="com.mysql.jdbc.Driver" user="root" password="123456"/>
RDBMS 是從數據庫使用 JDBC讀取 數據集。支持 type 為:db、mysql、oracle、postgres、mssql;
tablename 為該數據表的抽象 table 名稱(視圖);
url、driver、user,password 為數據庫 JDBC 驅動信息,為必須字段;
SparkSQL 會加載該表的全表數據,無法使用 where 條件。
SparkSQL Flow Transformer
<transform type="sql" table_name="cust_id_agmt_id_t" cached="true"> SELECT c_phone,c_type,c_num, CONCAT_VAL(cust_id) as cust_ids FROM user_concat_testx group by c_phone,c_type,c_num </transform>
Transform 支持 cached 屬性,默認為 false;如果設置為 true,相當于把該結果緩存到內存中,緩存到內存中的數據在后續其它 Transform 中使用能提高計算效率。但是需使用大量內存,開發者需要評估該數據集能否放到內存中,防止出現 OutofMemory 的異常。
SparkSQL Flow Targets
SparkSQL Flow Targets 支持輸出數據到一個或者多個目標。這些目標,基本覆蓋了 Source 包含的外部系統。下面以 Hive 舉例說明:
<target type="hive" table_name="cust_id_agmt_id_t" savemode=”append” target_table_name="cust_id_agmt_id_h"/>
table_name 為 source 或者 Transform 定義的表名稱;
target_table_name 為 hive 中的表結果,Hive 表可不存在也可存在,sparksql 會根據 DataFrame 的數據類型自動創建表;
savemode 默認為 overwrite 覆蓋寫入,當寫入目標已存在時刪除源表再寫入;支持 append 模式, 可增量寫入。
Target 有一個特殊的 show 類型的 target。用于直接在控制臺輸出一個 DataFrame 的結果到控制臺(print),該 target 用于開發和測試。
<target type="show" table_name="cust_id_agmt_id_t" rows=”10000”/>
Rows 用于控制輸出多少行數據。
SparkSQL Around
After 用于 Flow 在運行結束后執行的一個環繞,用于記錄日志和寫入狀態。類似 Java 的 try {} finally{ round.execute() }
多個 round 一定會執行,round 異常不會導致任務失敗。
<prepare>
<round type="mysql"
sql="insert into cpic_task_history(id, task_type, catalog_model, start_time, retry_count, final_status, created_at)
values(${uuid}, ${task.type}, ${catalog.model}, ${starttime}, 0, ${status}, now())"
url="${jdbc.url}" .../>
</prepare>
<after>
<round type="mysql"
sql="update cpic_task_history set
end_time = ${endtime}, final_status = ${status}, error_text = ${error} where id = ${uuid}"
url="${jdbc.url}”…/>
</after>Prepare round 和 after round 配合使用可用于記錄 SparkSQL Flow 任務的運行日志。
SparkSQL Around可使用的變量
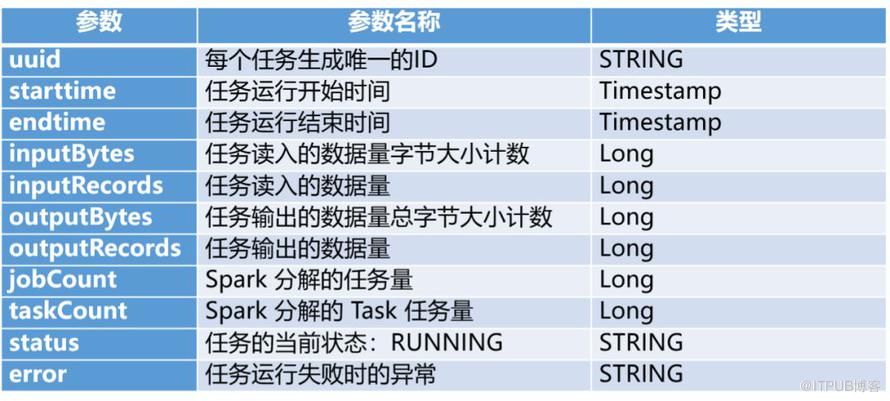
SparkSQL Around的執行效果
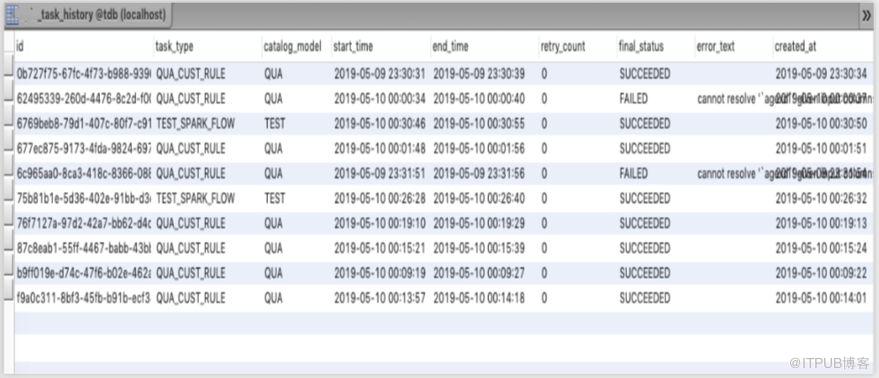
Prepare round 可做插入(insert)動作,after round 可做更新 (update)動作,相當于在數據庫表中從執行開始到結束有了完整的日志記錄。SparkSQL Flow 會保證round 一定能被執行,而且 round 的執行不影響任務的狀態。
SparkSQL Flow 提交
bin/spark-submit --master yarn-client --driver-memory 1G \ --num-executors 10 --executor-memory 2G \ --jars /lib/jsoup-1.11.3.jarlib/jsqlparser-0.9.6.jar,/lib/mysql-connector-java-5.1.46.jar \ --conf spark.yarn.jars=hdfs:///lib/spark2/*.jar \ --queue default --name FlowTest \ etl-flow-0.2.0.jar -f hive-flow-test.xml
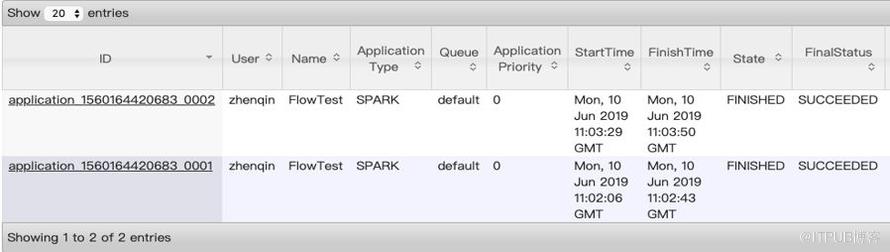
接收必須的參數 –f,可選的參數為支持 Kerberos 認證的租戶名稱principal,和其認證需要的密鑰文件。
usage: spark-submit --jars etl-flow.jar --class com.yiidata.etl.flow.source.FlowRunner -f,--xml-file <arg> Flow XML File Path --keytabFile <arg> keytab File Path(Huawei) --krb5File <arg> krb5 File Path(Huawei) --principal <arg> principal for hadoop(Huawei)
SparkSQL Execution Plan
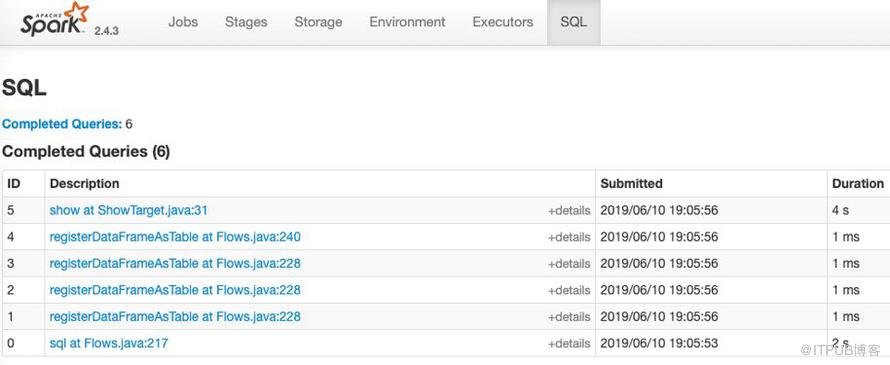
每個Spark Flow 任務本質上是一連串的 SparkSQL 操作,在 SparkUI SQL tab 里可以看到 flow 中重要的數據表操作。
regiserDataFrameAsTable 是每個 source 和 Transform 的數據在 SparkSQL 中的數據視圖,每個視圖都會在 SparkContex 中注冊一次。
對RegisterDataFrameAsTable的分析
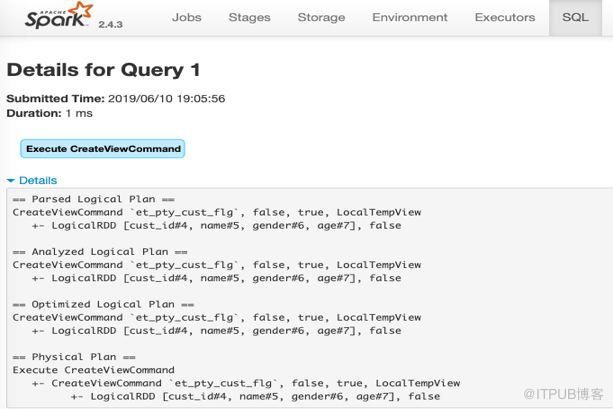
通過單個 regiserDataFrameAsTable 項進行分析,SparkSQL 并不是把source 的數據立即計算把數據放到內存,而是每次執行 source 時只是生成了一個 Logical Plan,只有遇到需要提交的算子(Action),SparkSQL 才會觸發前面所依賴的的 plan 執行。
這是一個開發框架,不是一個成熟的產品,也不是一種架構。他只是基于 SparkSQL 整合了大多數的外部系統,能通過 XML 的模板配置完成數據開發。面向的是理解數據業務但不了解 Spark 的數據開發人員。整個框架完成了大多數的外部系統對接,開發者只需要使用 type 獲得數據,完成數據開發后通過 target 回寫到目標系統中。整個過程基本無須程序開發,除非當前的 SQL 函數無法滿足使用的情況下,需要自行開發一下特定的 UDF。因此本框架在對 SparkSQL 做了二次開發基礎上,大大簡化了 Spark 的開發,可降低了開發者使用難度。
精選提問:
問1:和Fink平臺有什么優勢么?
答:Flink 應該對標 Spark Streaming 的解決方案,是另一種可選流數據引擎。Flink 也采用了 Scala 語言,內部原理和操作數據方式頗有相似之處,是 SparkStreaming 之外流數據處理一種選型。基于 SparkSQL Flow 的架構主要側重批量數據分析,非實時 ETL 方面。
問2:這些應該是源數據庫吧,請問目標數據庫支持哪些?
答:目前的實現目標數據基本支持所有的源。
問3:你們產品是軟件開發平臺,spark和你們開發平臺啥關系?
答:普元針對部分成熟場景提供了一些開發平臺和工具,也在參與了一些大數據項目建設。對于大規模數據的數據報表,數據質量分析也需要適應大數據的技術場景,Spark 作為Hadoop 內比較成熟的解決方案,因此作為主要的選型工具。在參與部分項目實施過程中,通過對一些開發中的痛點針對性的提取了應用框架。
問4:對于ETL中存在的merge、update的數據匹配、整合處理,Spark SQL Flow有沒有好的解決方法?
答:merge 和 update 在數據開發過程不可避免,往往對數據庫造成較大壓力。大數據場景下不建議逐條對數據做 update 操作,更好的辦法是在數據處理階段通過 join 把結果集在寫入目標前準備好,統一一次性寫入到目標數據庫。查詢操作通過換庫使用新庫,這中操作一般適合數據量比較大,數據更新頻率較低的情況。如果目標庫是 HBase 或者其他 MPP 類基于列式的數據庫,適當的可以更新。但是當每天有 60% 以上的數據都需要更新時,建議還是一次性生成新表。
問5: blink和flink 應該如何選取?
答:blink 是阿里巴巴在 flink 基礎上做了部分場景優化(只是部分社區有介紹,并不明確)并且開源,但是考慮到國內這些機構開源往往是沒有持久動力的。要看采用 Blink 是否用了比較關鍵的特性。也有消息說 Blink 和 Flink 會合并,畢竟阿里 Dubbo 前期自己發展,后期還是捐給了 Apache,因此兩者合并也是有可能。建議選型 Flink。
問6:etl 同步數據中主要用哪些工具?
答:這個要區分場景。傳統數據庫之間,可采用日志同步,也有部分成熟的工具;
傳統數據庫和Hadoop 生態內(HBase,HIVE) 同步可使用 apache sqoop。 SparkSQL Flow 可以作為數據同步的另一種方案,可用在實時性不高的場景。SparkSQL Flow 更側重大數據工具,偏向數據分析和非實時 ETL。
看完上述內容,你們對基于 Spark 的數據分析實踐是怎樣進行的有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





