溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Spark Connector Reader 原理與實踐是怎樣的,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
下面主要講述如何利用 Spark Connector 進行 Nebula Graph 數據的讀取。
Spark Connector 是一個 Spark 的數據連接器,可以通過該連接器進行外部數據系統的讀寫操作,Spark Connector 包含兩部分,分別是 Reader 和 Writer,而本文側重介紹 Spark Connector Reader,Writer 部分將在下篇和大家詳聊。
Spark Connector Reader 是將 Nebula Graph 作為 Spark 的擴展數據源,從 Nebula Graph 中將數據讀成 DataFrame,再進行后續的 map、reduce 等操作。
Spark SQL 允許用戶自定義數據源,支持對外部數據源進行擴展。通過 Spark SQL 讀取的數據格式是以命名列方式組織的分布式數據集 DataFrame,Spark SQL 本身也提供了眾多 API 方便用戶對 DataFrame 進行計算和轉換,能對多種數據源使用 DataFrame 接口。
Spark 調用外部數據源包的是 org.apache.spark.sql,首先了解下 Spark SQL 提供的的擴展數據源相關的接口。
BaseRelation:表示具有已知 Schema 的元組集合。所有繼承 BaseRelation 的子類都必須生成 StructType 格式的 Schema。換句話說,BaseRelation 定義了從數據源中讀取的數據在 Spark SQL 的 DataFrame 中存儲的數據格式的。
RelationProvider:獲取參數列表,根據給定的參數返回一個新的 BaseRelation。
DataSourceRegister:注冊數據源的簡寫,在使用數據源時不用寫數據源的全限定類名,而只需要寫自定義的 shortName 即可。
RelationProvider:從指定數據源中生成自定義的 relation。 createRelation() 會基于給定的 Params 參數生成新的 relation。
SchemaRelationProvider:可以基于給定的 Params 參數和給定的 Schema 信息生成新的 Relation。
RDD[InternalRow]: 從數據源中 Scan 出來后需要構造成 RDD[Row]
要實現自定義 Spark 外部數據源,需要根據數據源自定義上述部分方法。
在 Nebula Graph 的 Spark Connector 中,我們實現了將 Nebula Graph 作為 Spark SQL 的外部數據源,通過 sparkSession.read 形式進行數據的讀取。該功能實現的類圖展示如下:
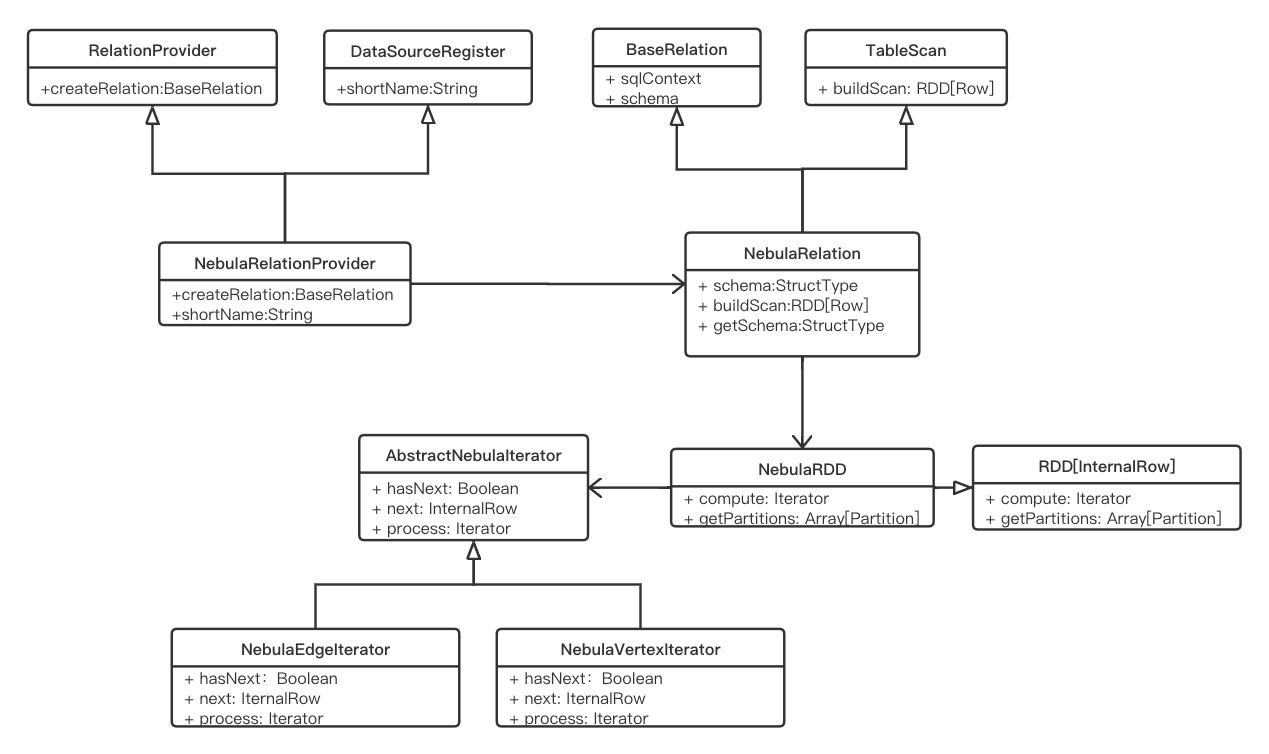
定義數據源 NebulaRelatioProvider,繼承 RelationProvider 進行 relation 自定義,繼承 DataSourceRegister 進行外部數據源的注冊。
定義 NebulaRelation 定義 Nebula Graph 的數據 Schema 和數據轉換方法。在 getSchema() 方法中連接 Nebula Graph 的 Meta 服務獲取配置的返回字段對應的 Schema 信息。
定義 NebulaRDD 進行 Nebula Graph 數據的讀取。 compute() 方法中定義如何讀取 Nebula Graph 數據,主要涉及到進行 Nebula Graph 數據 Scan、將讀到的 Nebula Graph Row 數據轉換為 Spark 的 InternalRow 數據,以 InternalRow 組成 RDD 的一行,其中每一個 InternalRow 表示 Nebula Graph 中的一行數據,最終通過分區迭代的形式將 Nebula Graph 所有數據讀出組裝成最終的 DataFrame 結果數據。
Spark Connector 的 Reader 功能提供了一個接口供用戶編程進行數據讀取。一次讀取一個點/邊類型的數據,讀取結果為 DataFrame。
下面開始實踐,拉取 GitHub 上 Spark Connector 代碼:
git clone -b v1.0 git@github.com:vesoft-inc/nebula-java.git cd nebula-java/tools/nebula-spark mvn clean compile package install -Dgpg.skip -Dmaven.javadoc.skip=true
將編譯打成的包 copy 到本地 Maven 庫。
應用示例如下:
在 mvn 項目的 pom 文件中加入 nebula-spark 依賴
<dependency> <groupId>com.vesoft</groupId> <artifactId>nebula-spark</artifactId> <version>1.1.0</version> </dependency>
在 Spark 程序中讀取 Nebula Graph 數據:
// 讀取 Nebula Graph 點數據
val vertexDataset: Dataset[Row] =
spark.read
.nebula("127.0.0.1:45500", "spaceName", "100")
.loadVerticesToDF("tag", "field1,field2")
vertexDataset.show()
// 讀取 Nebula Graph 邊數據
val edgeDataset: Dataset[Row] =
spark.read
.nebula("127.0.0.1:45500", "spaceName", "100")
.loadEdgesToDF("edge", "*")
edgeDataset.show()配置說明:
nebula(address: String, space: String, partitionNum: String)
address:可以配置多個地址,以英文逗號分割,如“ip1:45500,ip2:45500” space: Nebula Graph 的 graphSpace partitionNum: 設定spark讀取Nebula時的partition數,盡量使用創建 Space 時指定的 Nebula Graph 中的 partitionNum,可確保一個Spark的partition讀取Nebula Graph一個part的數據。
loadVertices(tag: String, fields: String)
tag:Nebula Graph 中點的 Tag fields:該 Tag 中的字段,,多字段名以英文逗號分隔。表示只讀取 fields 中的字段,* 表示讀取全部字段
loadEdges(edge: String, fields: String)
edge:Nebula Graph 中邊的 Edge fields:該 Edge 中的字段,多字段名以英文逗號分隔。表示只讀取 fields 中的字段,* 表示讀取全部字段
上述內容就是Spark Connector Reader 原理與實踐是怎樣的,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





