溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“基于node.js如何制作簡單爬蟲”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“基于node.js如何制作簡單爬蟲”這篇文章吧。
目標:爬取 http://tweixin.yueyishujia.com/webapp/build/html/ 網站的所有門店發型師的基本信息。
思路:訪問上述網站,通過chrome瀏覽器的network對網頁內容分析,找到獲取各個門店發型師的接口,對參數及返回數據進行分析,遍歷所有門店的所有發型師,直到遍歷完畢,同事將信息存儲到本地。
步驟一:安裝node.js
下載并安裝node,此步驟比較簡單就不詳細解釋了,有問題的可以直接問一下度娘。
步驟二:建立工程
1)打開dos命令條,cd進入想要創建項目的路徑(我將此項目直接放在了E盤,以下皆以此路徑為例);
2)mkdir node (創建一個文件夾用來存放項目,我這里取名為node);
3)cd 進入名為node的文件夾,并執行npm init初始化工程(期間會讓填寫一些信息,我是直接回車的);
步驟三:創建爬取到的數據存放的文件夾
1)創建data文件夾用來存放發型師基本信息;
2)創建image文件夾用來存儲發型師頭像圖片;
此時工程下文件如下:

步驟四:安裝第三方依賴包(fs是內置模塊,不需要單獨安裝)
1)npm install cheerio –save
2)npm install superagent –save
3)npm install async –save
4)npm install request –save
分別簡單解釋一下上面安裝的依賴包:
cheerio:是nodejs的抓取頁面模塊,為服務器特別定制的,快速、靈活、實施的jQuery核心實現,則能夠對請求結果進行解析,解析方式和jQuery的解析方式幾乎完全相同;
superagent:能夠實現主動發起get/post/delete等請求;
async:async模塊是為了解決嵌套金字塔,和異步流程控制而生,由于nodejs是異步編程模型,有一些在同步編程中很容易做到的事情,現在卻變得很麻煩。Async的流程控制就是為了簡化這些操作;
request:有了這個模塊,http請求變的超簡單,Request使用簡單,同時支持https和重定向;
步驟五:編寫爬蟲程序代碼
打開hz.js,編寫代碼:
var superagent = require('superagent');
var cheerio = require('cheerio');
var async = require('async');
var fs = require('fs');
var request = require('request');
var page=1; //獲取發型師處有分頁功能,所以用該變量控制分頁
var num = 0;//爬取到的信息總條數
var storeid = 1;//門店ID
console.log('爬蟲程序開始運行......');
function fetchPage(x) { //封裝函數
startRequest(x);
}
function startRequest(x) {
superagent
.post('http://tweixin.yueyishujia.com/v2/store/designer.json')
.send({
// 請求的表單信息Form data
page : x,
storeid : storeid
})
// Http請求的Header信息
.set('Accept', 'application/json, text/javascript, */*; q=0.01')
.set('Content-Type','application/x-www-form-urlencoded; charset=UTF-8')
.end(function(err, res){
// 請求返回后的處理
// 將response中返回的結果轉換成JSON對象
if(err){
console.log(err);
}else{
var designJson = JSON.parse(res.text);
var deslist = designJson.data.designerlist;
if(deslist.length > 0){
num += deslist.length;
// 并發遍歷deslist對象
async.mapLimit(deslist, 5,
function (hair, callback) {
// 對每個對象的處理邏輯
console.log('...正在抓取數據ID:'+hair.id+'----發型師:'+hair.name);
saveImg(hair,callback);
},
function (err, result) {
console.log('...累計抓取的信息數→→' + num);
}
);
page++;
fetchPage(page);
}else{
if(page == 1){
console.log('...爬蟲程序運行結束~~~~~~~');
console.log('...本次共爬取數據'+num+'條...');
return;
}
storeid += 1;
page = 1;
fetchPage(page);
}
}
});
}
fetchPage(page);
function saveImg(hair,callback){
// 存儲圖片
var img_filename = hair.store.name+'-'+hair.name + '.png';
var img_src = 'http://photo.yueyishujia.com:8112' + hair.avatar; //獲取圖片的url
//采用request模塊,向服務器發起一次請求,獲取圖片資源
request.head(img_src,function(err,res,body){
if(err){
console.log(err);
}else{
request(img_src).pipe(fs.createWriteStream('./image/' + img_filename)); //通過流的方式,把圖片寫到本地/image目錄下,并用發型師的姓名和所屬門店作為圖片的名稱。
console.log('...存儲id='+hair.id+'相關圖片成功!');
}
});
// 存儲照片相關信息
var html = '姓名:'+hair.name+'<br>職業:'+hair.jobtype+'<br>職業等級:'+hair.jobtitle+'<br>簡介:'+hair.simpleinfo+'<br>個性簽名:'+hair.info+'<br>剪發價格:'+hair.cutmoney+'元<br>店名:'+hair.store.name+'<br>地址:'+hair.store.location+'<br>聯系方式:'+hair.telephone+'<br>頭像:<img src='+img_src+' >';
fs.appendFile('./data/' +hair.store.name+'-'+ hair.name + '.html', html, 'utf-8', function (err) {
if (err) {
console.log(err);
}
});
callback(null, hair);
}步驟六:運行爬蟲程序
輸入node hz.js命令運行爬蟲程序,效果圖如下:

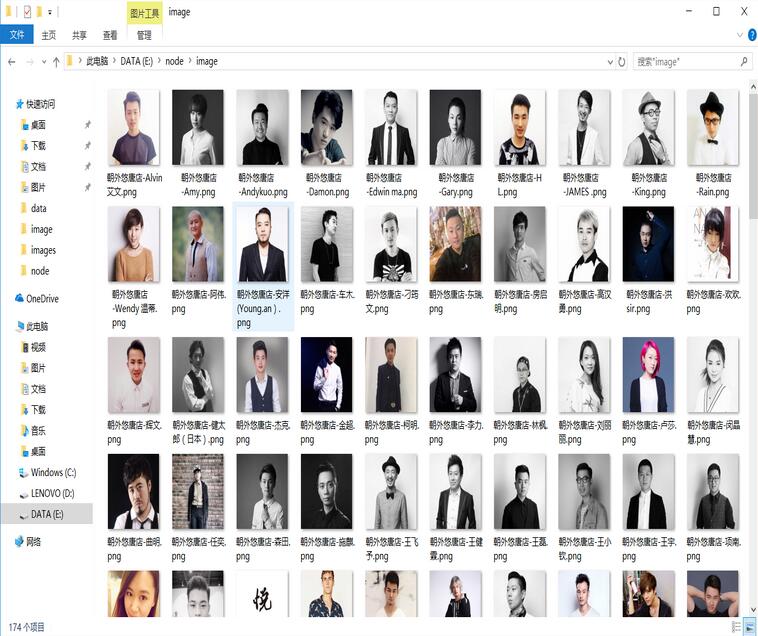
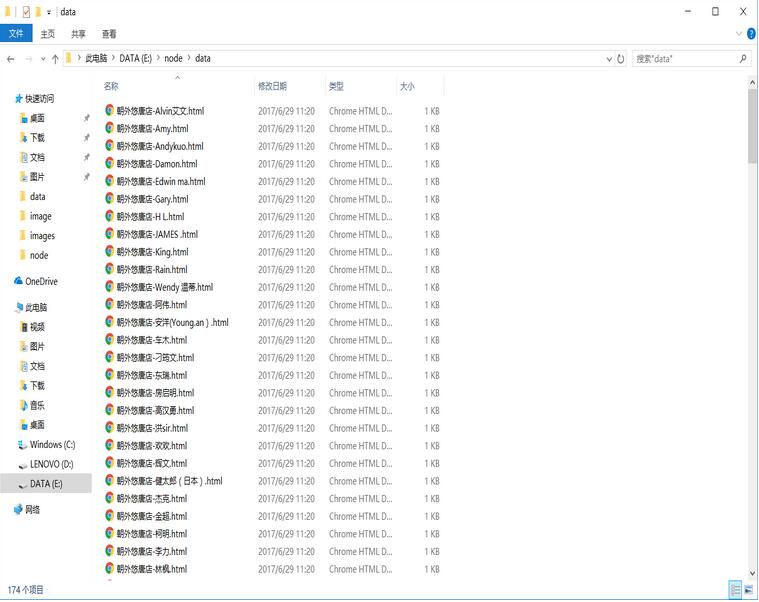
運行成功后,發型師基本信息以html文件的形式存儲在data文件夾中,發型師頭像圖片存儲在image文件夾下:
以上是“基于node.js如何制作簡單爬蟲”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





