溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關怎么在Python中使用seaborn實現數據可視化,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
1.首先我們還是需要先引入庫,不過這次要用到的python庫比較多。
import numpy as np import pandas as pd import matplotlib as mpl import matplotlib.pyplot as plt import seaborn as sns
2.sns.set_style():不傳入參數用的就是seaborn默認的主題風格,里面的參數共有五種
darkgrid
whitegrid
dark
white
ticks
我比較習慣用whitegrid。

3.下面說一下seaborn里面的調色板,我們可以用sns.color_palette()獲取到這些顏色,然后用sns.palplot()將這些色塊打印出來。color_palette()函數還可以傳入一些參數
sns.palplot(sns.color_palette("hls",n))#顯示出n個不同顏色的色塊
sns.palplot(sns.color_palette("Paired",2n))#顯示出2n個不同顏色的色塊,且這些顏色兩兩之間是相近的
sns.palplot(sns.color_palette("color"))#由淺入深顯示出同一顏色的色塊
sns.palplot(sns.color_palette("color_r"))##由深入淺顯示出同一顏色的色塊
sns.palplot(sns.color_palette("cubehelix",n))#顯示出n個顏色呈線性變化的色塊
sns.palplot(sns.cubehelix_palette(k,start=m,rot=n))#顯示出k個start(0,3)為m,rot(-1,1)為n的呈線性變化的色塊
sns.palplot(sns.light_palette("color"))#將一種顏色由淺到深顯示
sns.palplot(sns.dark_palette("color"))#將一種顏色由深到淺顯示
sns.palplot(sns.dark_palette("color",reverse=bool))#reverse的值為False,則將一種顏色由深到淺顯示;若為True,則將一種顏色由淺到深顯示


4.sns.kdeplot(x,y,cmap=pal):繪制核密度分布圖。

5.sns.distplot(x,kde=bool,bins=n):kde代表是否進行核密度估計,也就是是否繪制包絡線,bins指定繪制的條形數目。

6.根據均值和協方差繪圖:
首先我們要根據均值和協方差獲取數據
mean,cov = [m,n],[(a,b),(c,d)]#指定均值和協方差 data = np.random.multivariate_normal(mean,cov,e)#根據均值和協方差獲取e個隨機數據 df = pd.DataFrame(data,columns=["x","y"])#將數據指定為DataFrame格式 df

然后繪制圖像
sns.jointplot(x="x",y="y",data=df) #繪制散點圖

用sns.jointplot(x="x",y="y",data=df)可以繪制出x和y單變量的條形圖以及x與y多變量的散點圖。
7.在jointplot()函數中傳入kind=“hex”,能夠在數據量比較大時讓我們更清晰地看到數據的分布比重。
x,y = np.random.multivariate_normal(mean,cov,2000).T
with sns.axes_style("white"):
sns.jointplot(x=x,y=y,kind="hex",color="c")繪制出的圖像如下

8.sns.pairplot(df):繪制出各變量之間的散點圖與條形圖,且對角線均為條形圖。

在這里我們可以先使用df = sns.load_dataset("")將seaborn中原本帶有的數據讀入或用pandas讀取。
9.繪制回歸分析圖:這里可以用兩個函數regplot()和lmplot(),用regplot()更好一些。

如果兩個變量不適合做回歸分析,我們可以傳入x_jitter()或y_jitter()讓x軸或y軸的數據輕微抖動一些,得出較為準確的結果。

10.sns.stripplot(x="",y="",data=df,jitter=bool):繪制一個特征變量中的多個變量與另一變量關系的散點圖,jitter控制數據是否抖動。

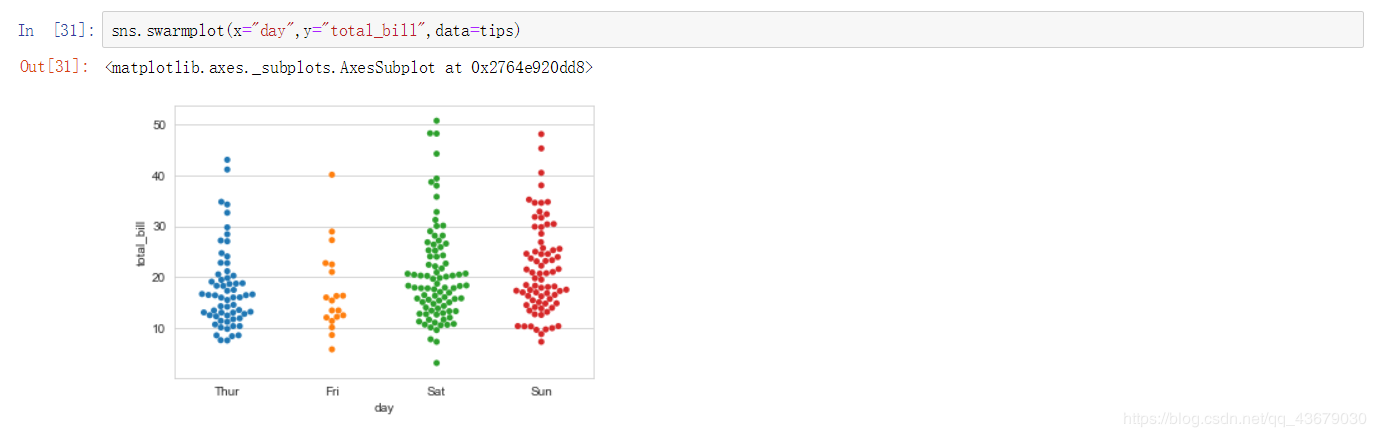
11.sns.swarmplot(x="",y="",hue="",data=df):繪制頁狀散點圖,hue指定對數據的分類,由于在大量數據下,上面的散點圖會影響到我們對數據的觀察,這種圖能夠更清晰地觀察到數據分布。

12.sns.boxplot(x="",y="",hue="",data=df,orient="h"):繪制盒形圖,hue同樣指定對數據的分類。在統計學中有四分位數的概念,第一個四分位記做Q1,第二個四分位數記做Q2,第三個四分位數記做Q3,Q3-Q1得到的結果Q叫做四分位距,如果一個數n,n的范圍是n<Q1-1.5Q或n>Q3+1.5Q,則稱n為離群點,也就是不符合數據規范的點,利用盒形圖可以很清晰地觀察到離群點。如果傳入orient則畫出的盒形圖是橫向的。

13.sns.violinplot(x="",y="",data=df,hue="",split=bool):繪制小提琴圖,split表示是否將兩類數據分開繪制,如果為True,則不分開繪制,默認為False。


14.還可以將頁狀散點圖和小提琴圖在一起繪制,只需將兩個繪圖命令

inner="None"表示去除小提琴圖內部的形狀。
15.sns.barplot(x="",y="",hue="",data=df):按hue的數據分類繪制條形圖。

16.sns.pointplot(x="",y="",hue="",data=df):繪制點圖,點圖可以更好的描述數據的變化差異。

17.我們還可以傳入其他參數:
sns.pointplot(x="class",y="survived",hue="sex",data=titanic,
palette={"male":"#02ff96","female":"#0980e6"},#指定曲線的顏色
markers=["s","d"],linestyles=["-","-."])#指定曲線的點型和線型繪制出的圖像如下

18.sns.factorplot(x="", y="", hue="", data=df):繪制多層面板分類圖。
sns.factorplot(x="day",y="total_bill",hue="smoker",data=tips)
繪制的圖像如下

19.sns.factorplot(x="",y="",hue="",data=df,kind=""):kind中指定要畫圖的類型。
sns.factorplot(x="day",y="total_bill",hue="smoker",data=tips,kind="bar")

sns.factorplot(x="day",y="total_bill",hue="smoker",col="time",data=tips,kind="swarm")

sns.factorplot(x="time",y="total_bill",hue="smoker",col="day",data=tips,kind="box",size=5,aspect=0.8) #aspect指定橫縱比

20.sns.factorplot()的參數:
x,y,hue 數據集變量 變量名。
date 數據集 數據集名。
row,col 更多分類變量進行平鋪顯示 變量名。
col_wrap 每行的最高平鋪數 整數。
estimator 在每個分類中進行矢量到標量的映射 矢量。
ci 置信區間 浮點數或None。
n_boot 計算置信區間時使用的引導迭代次數 整數。
units 采樣單元的標識符,用于執行多級引導和重復測量設計 數據變量或向量數據。
order, hue_order 對應排序列表 字符串列表。
row_order, col_order 對應排序列表 字符串列表。
kind : 可選:point 默認, bar 柱形圖, count 頻次, box 箱體, violin 提琴, strip 散點,swarm 分散點 size 每個面的高度(英寸) 標量 aspect 縱橫比 標量 orient 方向 "v"/"h" color 顏色 matplotlib顏色 palette 調色板 seaborn顏色色板或字典 legend hue的信息面板 True/False legend_out 是否擴展圖形,并將信息框繪制在中心右邊 True/False share{x,y} 共享軸線 True/False。
21.sns.FacetGrid():這是一個很重要的繪圖函數。
g = sns.FacetGrid(tips,col="time") g.map(plt.hist,"tip")

g = sns.FacetGrid(tips,col="sex",hue="smoker",size=5,aspect=1) g.map(plt.scatter,"total_bill","tip",alpha=0.3,s=100)#alpha指定點的透明度,s指定點的大小 g.add_legend()#添加圖例

g = sns.FacetGrid(tips,col="day",size=4,aspect=0.8) g.map(sns.barplot,"sex","total_bill")

22.sns.PairGrid():將各變量間的關系成對繪制。
iris = sns.load_dataset("iris")
g = sns.PairGrid(iris)
g.map(plt.scatter)
23.g.map_diag()和g.map_offdiag():繪制對角線和非對角線的圖形
g = sns.PairGrid(iris) g.map_diag(plt.hist) #指定對角線繪圖類型 g.map_offdiag(plt.scatter) #指定非對角線繪圖類型

g = sns.PairGrid(iris, hue="species") g.map_diag(plt.hist) g.map_offdiag(plt.scatter) g.add_legend()

g = sns.PairGrid(iris, vars=["sepal_length", "sepal_width"], hue="species",size=3) g.map(plt.scatter)

g = sns.PairGrid(tips, hue="size", palette="GnBu_d") g.map(plt.scatter, s=50, edgecolor="white") g.add_legend()

24.sns.heatmap():繪制熱度圖,熱度圖可以很清楚看到數據的變化情況以及變化過程中的最大值和最小值。
uniform_data = np.random.rand(3, 3) print (uniform_data) heatmap = sns.heatmap(uniform_data)

25.向heatmap()中傳入參數vmin=和vmax=。
ax = sns.heatmap(uniform_data,vmin=0.2,vmax=0.5) #超過最大值都是最大值的顏色,小于最小值都是最小值的顏色

26.
normal_data = np.random.randn(3, 3) print (normal_data) ax = sns.heatmap(normal_data, center=0) #center指定右側圖例的中心值

27.
flights = sns.load_dataset("flights")
flights = flights.pivot("month", "year", "passengers")
ax = sns.heatmap(flights, annot=True,fmt="d",linewidth=0.5)
#annot指定是否顯示數據,fmt指定數據的顯示格式,linewidth指定數據格子間的距離
28.
ax = sns.heatmap(flights, cmap="YlGnBu",cbar=True) #cmap指定圖形顏色,cbar表示是否繪制右側圖例。

上述就是小編為大家分享的怎么在Python中使用seaborn實現數據可視化了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





