溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Python數據可視化之Seaborn怎么使用的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇Python數據可視化之Seaborn怎么使用文章都會有所收獲,下面我們一起來看看吧。
安裝:
pip install seaborn
導入:
import seaborn as sns
正式開始之前我們先用如下代碼準備一組數據,方便展示使用。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
pd.set_option('display.unicode.east_asian_width', True)
df1 = pd.DataFrame(
{'數據序號': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12],
'廠商編號': ['001', '001', '001', '002', '002', '002', '003', '003', '003', '004', '004', '004'],
'產品類型': ['AAA', 'BBB', 'CCC', 'AAA', 'BBB', 'CCC', 'AAA', 'BBB', 'CCC', 'AAA', 'BBB', 'CCC'],
'A屬性值': [40, 70, 60, 75, 90, 82, 73, 99, 125, 105, 137, 120],
'B屬性值': [24, 36, 52, 32, 49, 68, 77, 90, 74, 88, 98, 99],
'C屬性值': [30, 36, 55, 46, 68, 77, 72, 89, 99, 90, 115, 101]
}
)
print(df1)生成一組數據如下:
設置風格使用的是sns.set_style()方法,且這里內置的風格,是用背景色表示名字的,但是實際內容不限于背景色。
sns.set_style()
可以選擇的背景風格有:
whitegrid  白色網格
dark  灰色背景
white  白色背景
ticks  四周帶刻度線的白色背景
sns.set()
sns.set_style(“darkgrid”)
sns.set_style(“whitegrid”)
sns.set_style(“dark”)
sns.set_style(“white”)
sns.set_style(“ticks”) 
其中sns.set()表示使用自定義樣式,如果沒有傳入參數,則默認表示灰色網格背景風格。如果沒有set()也沒有set_style(),則為白色背景。
一個可能的bug:使用relplot()方法繪制出的圖像,"ticks"樣式無效。
seaborn庫是基于matplotlib庫而封裝的,其封裝好的風格可以更加方便我們的繪圖工作。而matplotlib庫常用的語句,在使用seaborn庫時也依然有效。
關于設置其他風格相關的屬性,如字體,這里有一個細節需要注意的是,這些代碼必須寫在sns.set_style()的后方才有效。如將字體設置為黑體(避免中文亂碼)的代碼: 
plt.rcParams[‘font.sans-serif’] = [‘SimHei’]
如果在其后方設置風格,則設置好的字體會設置的風格覆蓋,從而產生警告。其他屬性也同理。
sns.despine()方法
# 移除頂部和右部邊框,只保留左邊框和下邊框 sns.despine() # 使兩個坐標軸相隔一段距離(以10長度為例) sns.despine(offet=10,trim=True) # 移除左邊框 sns.despine(left=True) # 移除指定邊框 (以只保留底部邊框為例) sns.despine(fig=None, ax=None, top=True, right=True, left=True, bottom=False, offset=None, trim=False)
使用seaborn庫 繪制散點圖,可以使用replot()方法,也可以使用scatter()方法。
replot方法的參數kind默認是’scatter’,表示繪制散點圖。
hue參數表示 在該一維度上,用顏色區分
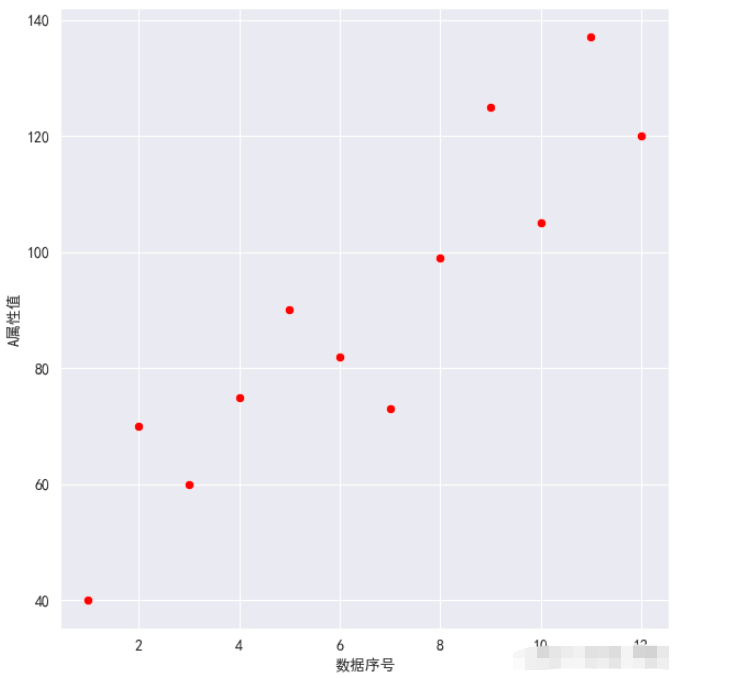
①對A屬性值和數據序號繪制散點圖,紅色散點,灰色網格,保留左、下邊框
sns.set_style(‘darkgrid') plt.rcParams[‘font.sans-serif'] = [‘SimHei'] sns.relplot(x=‘數據序號', y=‘A屬性值', data=df1, color=‘red') plt.show()
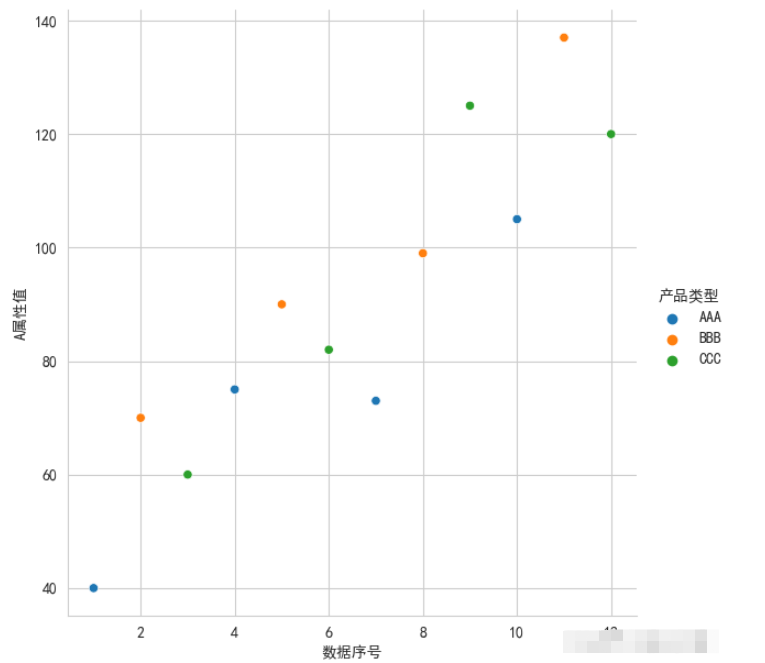
②對A屬性值和數據序號繪制散點圖,散點根據產品類型的不同顯示不同的顏色,
白色網格,左、下邊框:
sns.set_style(‘whitegrid') plt.rcParams[‘font.sans-serif'] = [‘SimHei'] sns.relplot(x=‘數據序號', y=‘A屬性值', hue=‘產品類型', data=df1) plt.show()
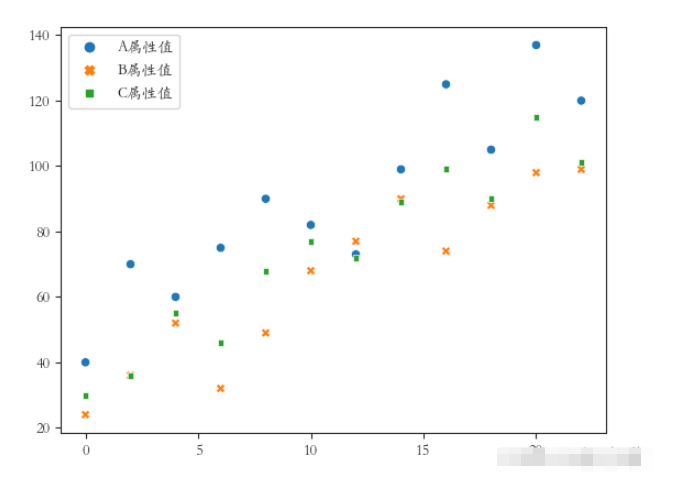
③將A屬性、B屬性、C屬性三個字段的值用不同的樣式繪制在同一張圖上(繪制散點圖),x軸數據是[0,2,4,6,8…]
ticks風格(四個方向的框線都要),字體使用楷體
sns.set_style(‘ticks') plt.rcParams[‘font.sans-serif'] = [‘STKAITI'] df2 = df1.copy() df2.index = list(range(0, len(df2)*2, 2)) dfs = [df2[‘A屬性值'], df2[‘B屬性值'], df2[‘C屬性值']] sns.scatterplot(data=dfs) plt.show()
使用seaborn庫繪制折線圖, 可以使用replot()方法,也可以使用lineplot()方法。
sns.replot()默認繪制的是散點圖,繪制折線圖只需吧參數kind改為"line"。
①需求:繪制A屬性值與數據序號的折線圖,
灰色網格,全局字體為楷體;并調整標題、兩軸標簽 的字體大小,
以及坐標系與畫布邊緣的距離(設置該距離是因為字體沒有顯示完全):
sns.set(rc={‘font.sans-serif': “STKAITI”})
sns.relplot(x=‘數據序號', y=‘A屬性值', data=df1, color=‘purple', kind=‘line')
plt.title(“繪制折線圖”, fontsize=18)
plt.xlabel(‘num', fontsize=18)
plt.ylabel(‘A屬性值', fontsize=16)
plt.subplots_adjust(left=0.15, right=0.9, bottom=0.1, top=0.9)
plt.show()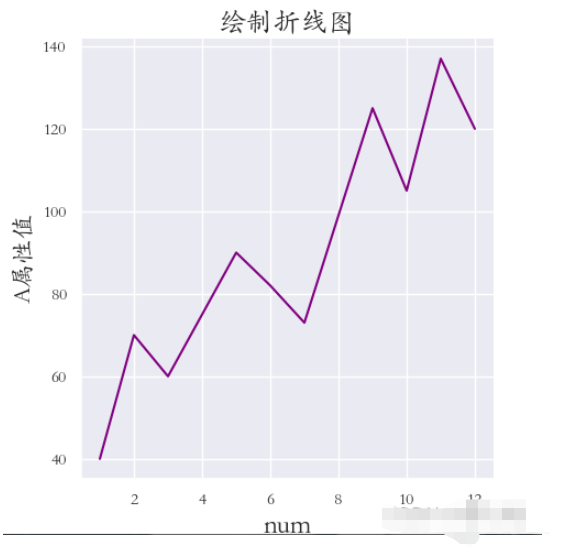
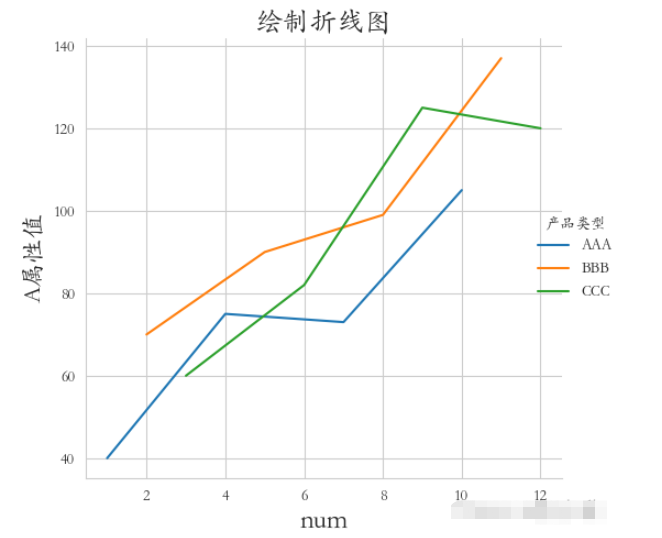
②需求:繪制不同產品類型的A屬性折線(三條線一張圖),whitegrid風格,字體楷體。
sns.set_style(“whitegrid”) plt.rcParams[‘font.sans-serif'] = [‘STKAITI'] sns.relplot(x=‘數據序號', y=‘A屬性值', hue=‘產品類型', data=df1, kind=‘line') plt.title(“繪制折線圖”, fontsize=18) plt.xlabel(‘num', fontsize=18) plt.ylabel(‘A屬性值', fontsize=16) plt.subplots_adjust(left=0.15, right=0.9, bottom=0.1, top=0.9) plt.show()
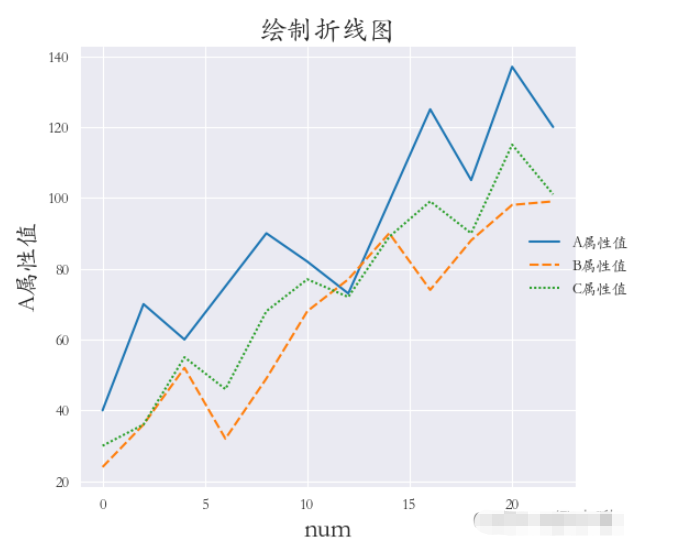
③需求:將A屬性、B屬性、C屬性三個字段的值用不同的樣式繪制在同一張圖上(繪制折線圖),x軸數據是[0,2,4,6,8…]
darkgrid風格(四個方向的框線都要),字體使用楷體,并加入x軸標簽,y軸標簽和標題。邊緣距離合適。
sns.set_style(‘darkgrid') plt.rcParams[‘font.sans-serif'] = [‘STKAITI'] df2 = df1.copy() df2.index = list(range(0, len(df2)*2, 2)) dfs = [df2[‘A屬性值'], df2[‘B屬性值'], df2[‘C屬性值']] sns.relplot(data=dfs, kind=“line”) plt.title(“繪制折線圖”, fontsize=18) plt.xlabel(‘num', fontsize=18) plt.ylabel(‘A屬性值', fontsize=16) plt.subplots_adjust(left=0.15, right=0.9, bottom=0.1, top=0.9) plt.show()
③多重子圖
橫向多重子圖 col
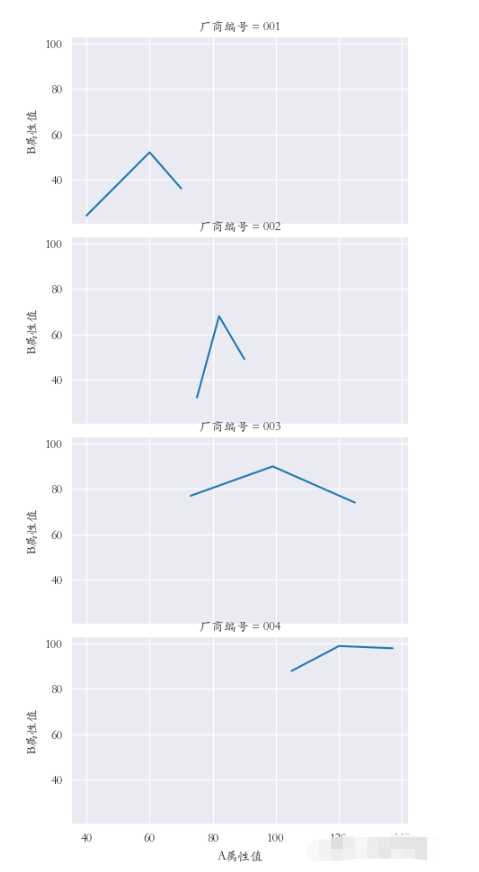
sns.set_style(‘darkgrid') plt.rcParams[‘font.sans-serif'] = [‘STKAITI'] sns.relplot(data=df1, x=“A屬性值”, y=“B屬性值”, kind=“line”, col=“廠商編號”) plt.subplots_adjust(left=0.05, right=0.95, bottom=0.1, top=0.9) plt.show()
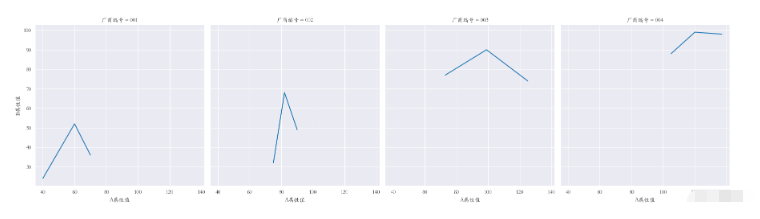
縱向多重子圖 row
sns.set_style(‘darkgrid') plt.rcParams[‘font.sans-serif'] = [‘STKAITI'] sns.relplot(data=df1, x=“A屬性值”, y=“B屬性值”, kind=“line”, row=“廠商編號”) plt.subplots_adjust(left=0.15, right=0.9, bottom=0.1, top=0.95) plt.show()
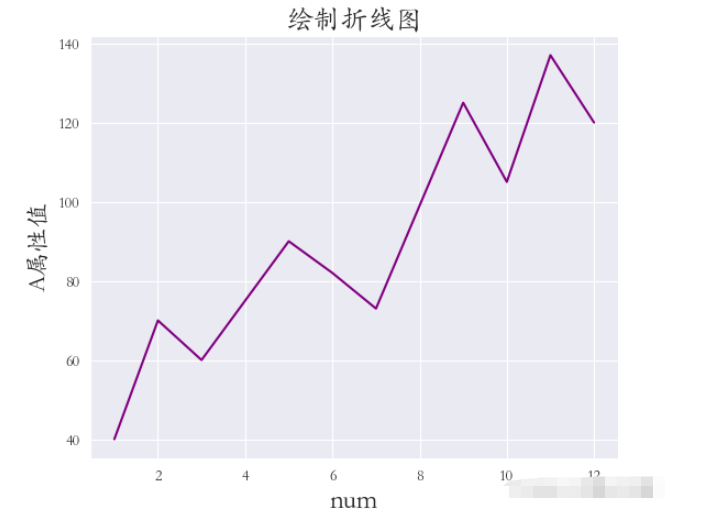
使用lineplot()方法繪制折線圖,其他細節基本同上,示例代碼如下:
sns.set_style(‘darkgrid') plt.rcParams[‘font.sans-serif'] = [‘STKAITI'] sns.lineplot(x=‘數據序號', y=‘A屬性值', data=df1, color=‘purple') plt.title(“繪制折線圖”, fontsize=18) plt.xlabel(‘num', fontsize=18) plt.ylabel(‘A屬性值', fontsize=16) plt.subplots_adjust(left=0.15, right=0.9, bottom=0.1, top=0.9) plt.show()
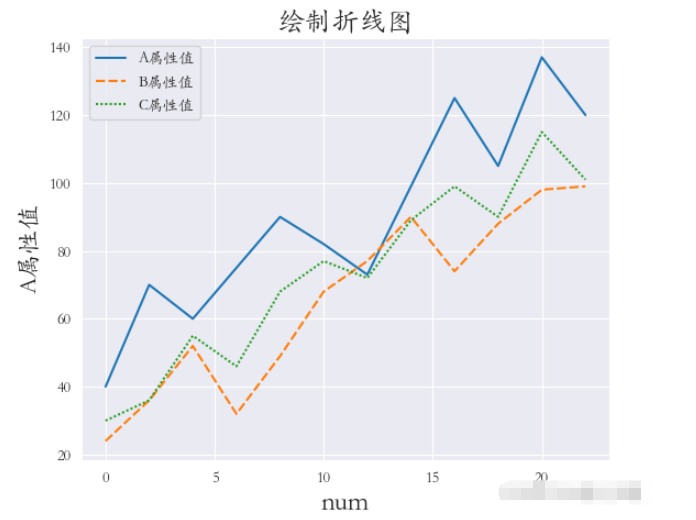
sns.set_style(‘darkgrid') plt.rcParams[‘font.sans-serif'] = [‘STKAITI'] df2 = df1.copy() df2.index = list(range(0, len(df2)*2, 2)) dfs = [df2[‘A屬性值'], df2[‘B屬性值'], df2[‘C屬性值']] sns.lineplot(data=dfs) plt.title(“繪制折線圖”, fontsize=18) plt.xlabel(‘num', fontsize=18) plt.ylabel(‘A屬性值', fontsize=16) plt.subplots_adjust(left=0.15, right=0.9, bottom=0.1, top=0.9) plt.show()
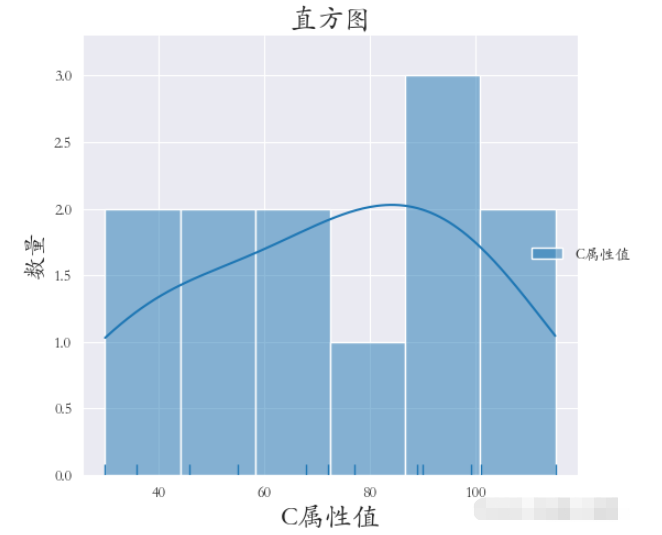
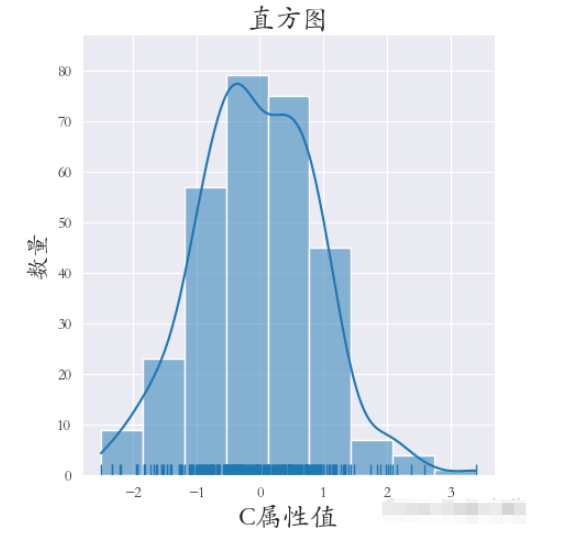
繪制直方圖使用的是sns.displot()方法
bins=6 表示 分成六個區間繪圖
rug=True 表示在x軸上顯示觀測的小細條
kde=True表示顯示核密度曲線
sns.set_style(‘darkgrid') plt.rcParams[‘font.sans-serif'] = [‘STKAITI'] sns.displot(data=df1[[‘C屬性值']], bins=6, rug=True, kde=True) plt.title(“直方圖”, fontsize=18) plt.xlabel(‘C屬性值', fontsize=18) plt.ylabel(‘數量', fontsize=16) plt.subplots_adjust(left=0.15, right=0.9, bottom=0.1, top=0.9) plt.show()
隨機生成300個正態分布數據,并繪制直方圖,顯示核密度曲線
sns.set_style(‘darkgrid') plt.rcParams[‘font.sans-serif'] = [‘STKAITI'] np.random.seed(13) Y = np.random.randn(300) sns.displot(Y, bins=9, rug=True, kde=True) plt.title(“直方圖”, fontsize=18) plt.xlabel(‘C屬性值', fontsize=18) plt.ylabel(‘數量', fontsize=16) plt.subplots_adjust(left=0.15, right=0.9, bottom=0.1, top=0.9) plt.show()
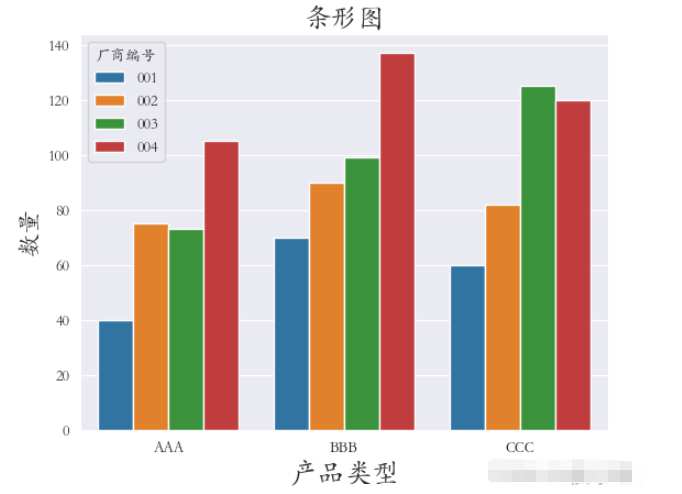
繪制條形圖使用的是barplot()方法
以產品類型 字段數據作為x軸數據,A屬性值數據作為y軸數據。按照廠商編號字段的不同進行分類。
具體如下:
sns.set_style(‘darkgrid') plt.rcParams[‘font.sans-serif'] = [‘STKAITI'] sns.barplot(x=“產品類型”, y=‘A屬性值', hue=“廠商編號”, data=df1) plt.title(“條形圖”, fontsize=18) plt.xlabel(‘產品類型', fontsize=18) plt.ylabel(‘數量', fontsize=16) plt.subplots_adjust(left=0.15, right=0.9, bottom=0.15, top=0.9) plt.show()
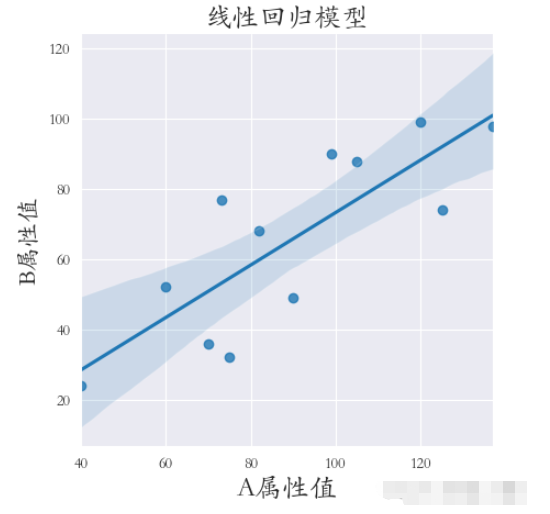
繪制線性回歸模型使用的是lmplot()方法。
主要的參數為x, y, data。分別表示x軸數據、y軸數據和數據集數據。
除此之外,同上述所講,還可以通過hue指定分類的變量;
通過col指定列分類變量,以繪制 橫向多重子圖;
通過row指定行分類變量,以繪制 縱向多重子圖;
通過col_wrap控制每行子圖的數量;
通過size可以控制子圖的高度;
通過markers可以控制點的形狀。
下邊對 X屬性值 和 Y屬性值 做線性回歸,代碼如下:
sns.set_style(‘darkgrid') plt.rcParams[‘font.sans-serif'] = [‘STKAITI'] sns.lmplot(x=“A屬性值”, y=‘B屬性值', data=df1) plt.title(“線性回歸模型”, fontsize=18) plt.xlabel(‘A屬性值', fontsize=18) plt.ylabel(‘B屬性值', fontsize=16) plt.subplots_adjust(left=0.15, right=0.9, bottom=0.15, top=0.9) plt.show()
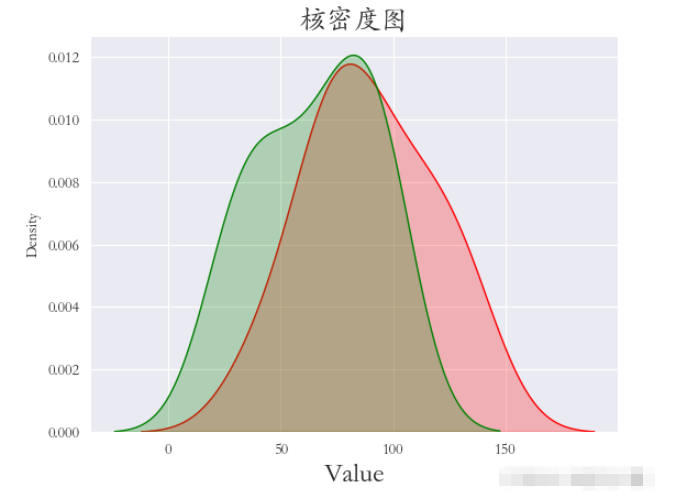
繪制和密度圖,可以讓我們更直觀地看出樣本數據的分布特征。繪制核密度圖使用的方法是kdeplot()方法。
對A屬性值和B屬性值繪制核密度圖,
將shade設置為True可以顯示包圍的陰影,否則只有線條。
sns.set_style(‘darkgrid') plt.rcParams[‘font.sans-serif'] = [‘STKAITI'] sns.kdeplot(df1[“A屬性值”], shade=True, data=df1, color=‘r') sns.kdeplot(df1[“B屬性值”], shade=True, data=df1, color=‘g') plt.title(“核密度圖”, fontsize=18) plt.xlabel(‘Value', fontsize=18) plt.subplots_adjust(left=0.15, right=0.9, bottom=0.15, top=0.9) plt.show()
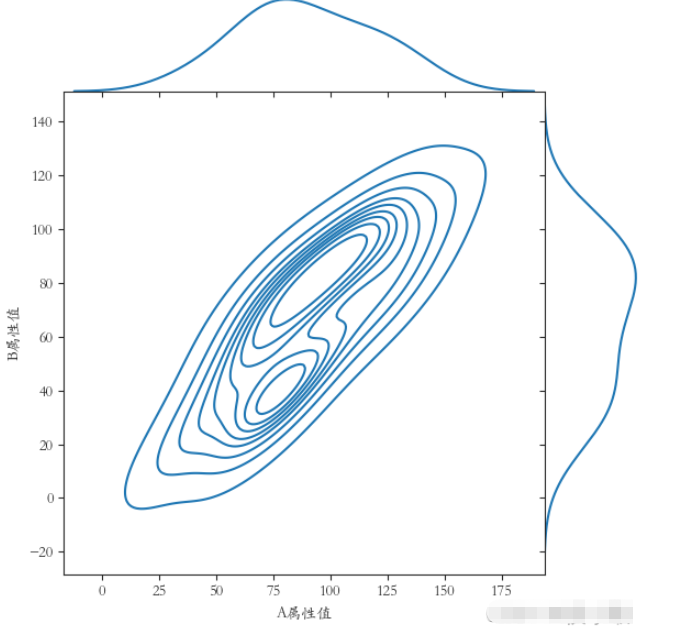
繪制邊際核密度圖時使用的是sns.jointplot()方法。參數kind應為"kde"。使用該方法時,默認使用的是dark樣式。且不建議手動添加其他樣式,否則可能使圖像無法正常顯示。
plt.rcParams[‘font.sans-serif'] = [‘STKAITI'] sns.jointplot(x=df1[“A屬性值”], y=df1[“B屬性值”], kind=“kde”, space=0) plt.show()
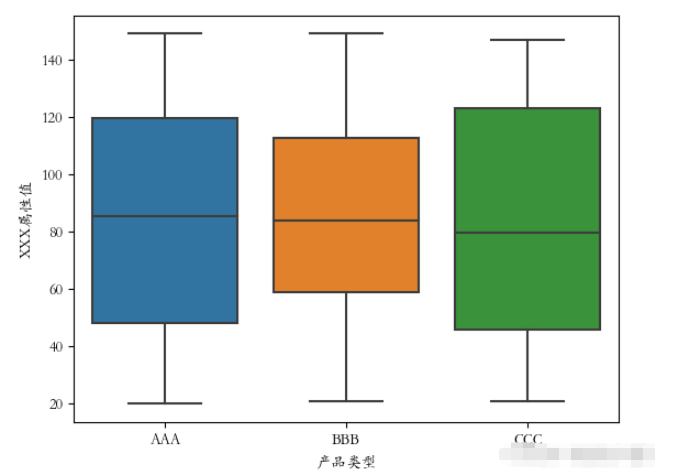
繪制箱線圖使用到的是boxplot()方法。
基本的參數有x, y, data。
除此之外 還可以有
hue 表示分類字段
width 可以調節箱體的寬度
notch 表示中間箱體是否顯示缺口,默認False不顯示。
鑒于前邊的數據數據量不太夠不便展示,這里再生成一組數據:
np.random.seed(13)
Y = np.random.randint(20, 150, 360)
df2 = pd.DataFrame(
{‘廠商編號': [‘001', ‘001', ‘001', ‘002', ‘002', ‘002', ‘003', ‘003', ‘003', ‘004', ‘004', ‘004'] * 30,
‘產品類型': [‘AAA', ‘BBB', ‘CCC', ‘AAA', ‘BBB', ‘CCC', ‘AAA', ‘BBB', ‘CCC', ‘AAA', ‘BBB', ‘CCC'] * 30,
‘XXX屬性值': Y
}
)生成好后,開始繪制箱線圖:
plt.rcParams[‘font.sans-serif'] = [‘STKAITI'] sns.boxplot(x=‘產品類型', y=‘XXX屬性值', data=df2) plt.show()
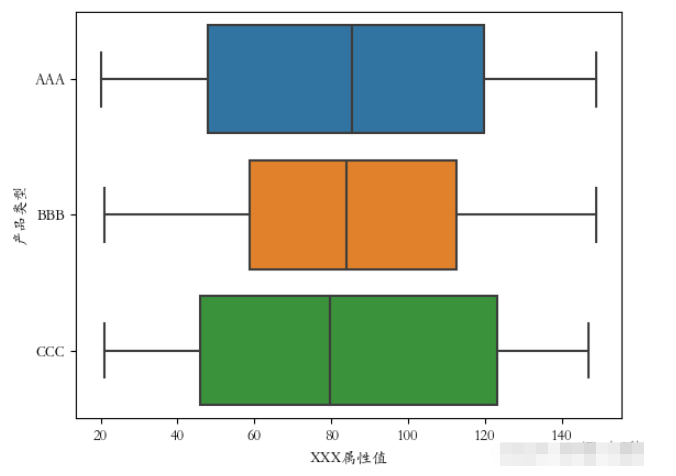
交換x、y軸數據后:
plt.rcParams[‘font.sans-serif'] = [‘STKAITI'] sns.boxplot(y=‘產品類型', x=‘XXX屬性值', data=df2) plt.show()
可以看到箱線圖的方向也隨之改變
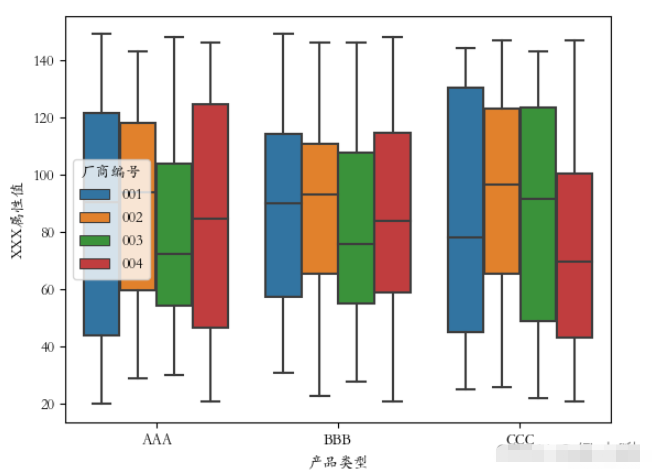
將廠商編號作為分類字段:
plt.rcParams[‘font.sans-serif'] = [‘STKAITI'] sns.boxplot(x=‘產品類型', y=‘XXX屬性值', data=df2, hue=“廠商編號”) plt.show()
提琴圖結合了箱線圖和核密度圖的特征,用于展示數據的分布形狀。
使用violinplot()方法繪制提琴圖。
plt.rcParams[‘font.sans-serif'] = [‘STKAITI'] sns.violinplot(x=‘產品類型', y=‘XXX屬性值', data=df2) plt.show()
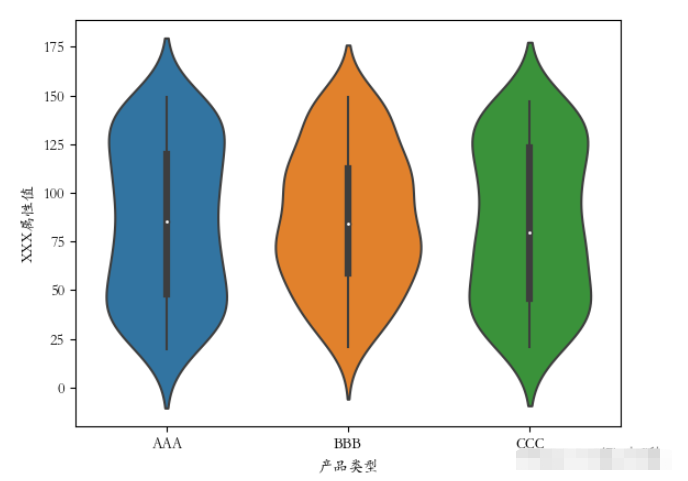
plt.rcParams[‘font.sans-serif'] = [‘STKAITI'] sns.violinplot(x=‘XXX屬性值', y=‘產品類型', data=df2) plt.show()
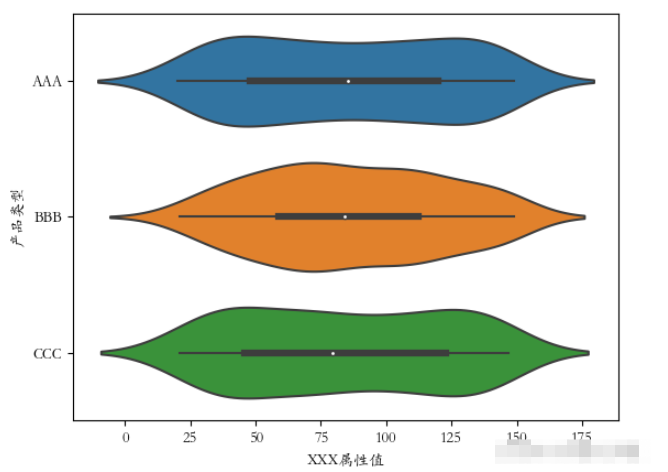
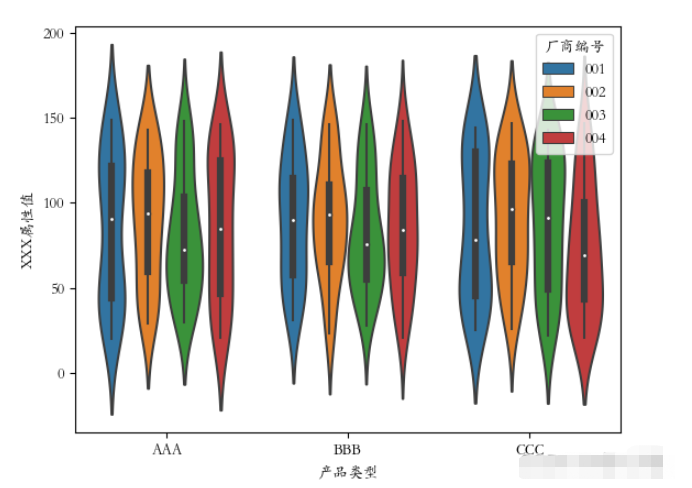
plt.rcParams[‘font.sans-serif'] = [‘STKAITI'] sns.violinplot(x=‘產品類型', y=‘XXX屬性值', data=df2, hue=“廠商編號”) plt.show()
以雙色球中獎號碼數據為例繪制熱力圖,這里數據采用隨機數生成。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
?
sns.set()
plt.figure(figsize=(6,6))
plt.rcParams[‘font.sans-serif'] = [‘STKAITI']
?
s1 = np.random.randint(0, 200, 33)
s2 = np.random.randint(0, 200, 33)
s3 = np.random.randint(0, 200, 33)
s4 = np.random.randint(0, 200, 33)
s5 = np.random.randint(0, 200, 33)
s6 = np.random.randint(0, 200, 33)
s7 = np.random.randint(0, 200, 33)
data = pd.DataFrame(
{‘一': s1,
‘二': s2,
‘三': s3,
‘四':s4,
‘五':s5,
‘六':s6,
‘七':s7
}
)
?
plt.title(‘雙色球熱力圖')
sns.heatmap(data, annot=True, fmt=‘d', lw=0.5)
plt.xlabel(‘中獎號碼位數')
plt.ylabel(‘雙色球數字')
x = [‘第1位', ‘第2位', ‘第3位', ‘第4位', ‘第5位', ‘第6位', ‘第7位']
plt.xticks(range(0, 7, 1), x, ha=‘left')
plt.show()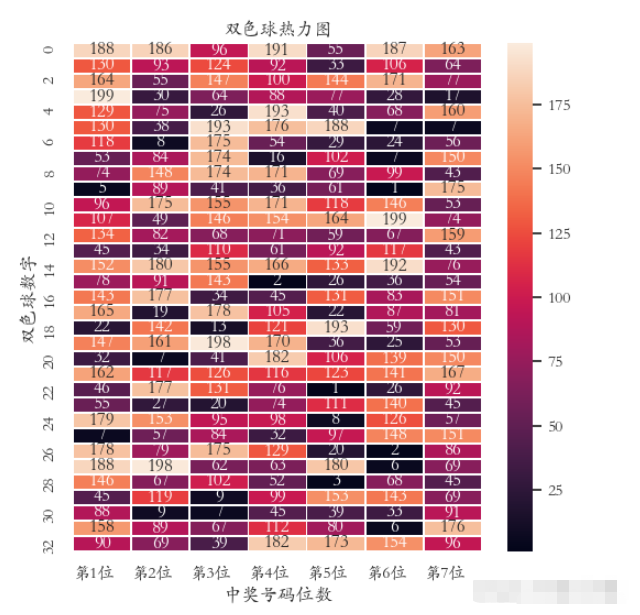
關于“Python數據可視化之Seaborn怎么使用”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“Python數據可視化之Seaborn怎么使用”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





