溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
除了使用xlrd庫或者xlwt庫進行對excel表格的操作讀與寫,而且pandas庫同樣支持excel的操作;且pandas操作更加簡介方便。
首先是pd.read_excel的參數:函數為:
pd.read_excel(io, sheetname=0,header=0,skiprows=None,index_col=None,names=None,
arse_cols=None,date_parser=None,na_values=None,thousands=None,
convert_float=True,has_index_names=None,converters=None,dtype=None,
true_values=None,false_values=None,engine=None,squeeze=False,**kwds)
表格數據:
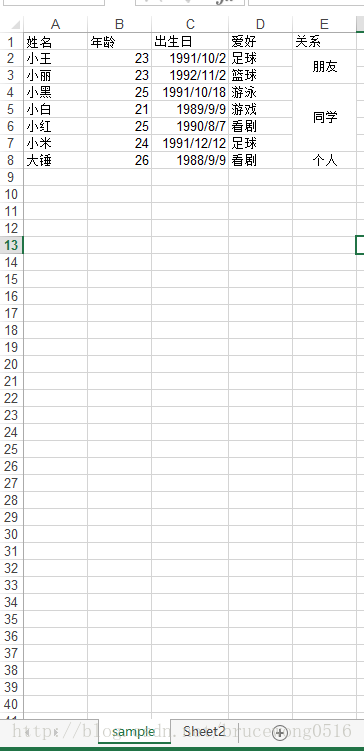

常用參數解析:
io :excel 路徑;
In [10]: import pandas as pd #定義路徑IO In [11]: IO = 'example.xls' #讀取excel文件 In [12]: sheet = pd.read_excel(io=IO) #此處由于sheetname默認是0,所以返回第一個表 In [13]: sheet Out[13]: 姓名 年齡 出生日 愛好 關系 0 小王 23 1991-10-02 足球 朋友 1 小麗 23 1992-11-02 籃球 NaN 2 小黑 25 1991-10-18 游泳 同學 3 小白 21 1989-09-09 游戲 NaN 4 小紅 25 1990-08-07 看劇 NaN 5 小米 24 1991-12-12 足球 NaN 6 大錘 26 1988-09-09 看劇 個人 #上述列表返回的結果和原表格存在合并單元格的差異
sheetname:默認是sheetname為0,返回多表使用sheetname=[0,1],若sheetname=None是返回全表 。注意:int/string返回的是dataframe,而none和list返回的是dict of dataframe。
In [7]: sheet = pd.read_excel('example.xls',sheetname= [0,1])
#參數為None時,返回全部的表格,是一個表格的字典;
#當參數為list = [0,1,2,3]此類時,返回的多表格同樣是字典
In [8]: sheet
Out[8]:
{0: 姓名 年齡 出生日 愛好 關系
0 小王 23 1991-10-02 足球 朋友
1 小麗 23 1992-11-02 籃球 NaN
2 小黑 25 1991-10-18 游泳 同學
3 小白 21 1989-09-09 游戲 NaN
4 小紅 25 1990-08-07 看劇 NaN
5 小米 24 1991-12-12 足球 NaN
6 大錘 26 1988-09-09 看劇 個人, 1: 1 3 5 學生
0 2 3 4 老師
1 4 1 9 教授}
#value是一個多位數組
In [15]: sheet[0].values
Out[15]:
array([['小王', 23, Timestamp('1991-10-02 00:00:00'), '足球', '朋友'],
['小麗', 23, Timestamp('1992-11-02 00:00:00'), '籃球', nan],
['小黑', 25, Timestamp('1991-10-18 00:00:00'), '游泳', '同學'],
['小白', 21, Timestamp('1989-09-09 00:00:00'), '游戲', nan],
['小紅', 25, Timestamp('1990-08-07 00:00:00'), '看劇', nan],
['小米', 24, Timestamp('1991-12-12 00:00:00'), '足球', nan],
['大錘', 26, Timestamp('1988-09-09 00:00:00'), '看劇', '個人']], dtype=object)
#同樣可以根據表頭名稱或者表的位置讀取該表的數據
#通過表名
In [17]: sheet = pd.read_excel('example.xls',sheetname= 'Sheet2')
In [18]: sheet
Out[18]:
1 3 5 學生
0 2 3 4 老師
1 4 1 9 教授
#通過表的位置
In [19]: sheet = pd.read_excel('example.xls',sheetname= 1)
In [20]: sheet
Out[20]:
1 3 5 學生
0 2 3 4 老師
1 4 1 9 教授
header :指定作為列名的行,默認0,即取第一行,數據為列名行以下的數據;若數據不含列名,則設定 header = None;
#數據不含作為列名的行
In [21]: sheet = pd.read_excel('example.xls',sheetname= 1,header = None)
In [22]: sheet
Out[22]:
0 1 2 3
0 1 3 5 學生
1 2 3 4 老師
2 4 1 9 教授
#默認第一行數據作為列名
In [23]: sheet = pd.read_excel('example.xls',sheetname= 1,header =0)
In [24]: sheet
Out[24]:
1 3 5 學生
0 2 3 4 老師
1 4 1 9 教授
skiprows:省略指定行數的數據
In [25]: sheet = pd.read_excel('example.xls',sheetname= 1,header = None,skiprows= 1)
#略去1行的數據,自上而下的開始略去數據的行
In [26]: sheet
Out[26]:
0 1 2 3
0 2 3 4 老師
1 4 1 9 教授
skip_footer:省略從尾部數的行數據
In [27]: sheet = pd.read_excel('example.xls',sheetname= 1,header = None,skip_footer= 1)
#從尾部開始略去行的數據
In [28]: sheet
Out[28]:
0 1 2 3
0 1 3 5 學生
1 2 3 4 老師
index_col :指定列為索引列,也可以使用 u'string'
#指定第二列的數據作為行索引
In [30]: sheet = pd.read_excel('example.xls',sheetname= 1,header = None,skip_footer= 1,index_col=1)
In [31]: sheet
Out[31]:
0 2 3
1
3 1 5 學生
3 2 4 老師
names:指定列的名字,傳入一個list數據
In [32]: sheet = pd.read_excel('example.xls',sheetname= 1,header = None,skip_footer= 1,index_col=1,names=['a','b','c'])
...:
In [33]: sheet
Out[33]:
a b c
1
3 1 5 學生
3 2 4 老師
總體而言,pandas庫的pd.read_excel和pd.read_csv的參數比較類似,且相較之前的xlrd庫的讀表操作更加簡單,針對一般批量的數據處理最好選擇pandas庫操作。但是功能有待完善或者本次研究的不夠深入,比如合并單元格的問題,歡迎一起討論交流。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





