溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了js如何實現一個通用的“劃詞高亮”在線筆記功能,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
1. 什么是“劃詞高亮”?
有些同學可能不太清楚“劃詞高亮”是指什么,下面就是一個典型的“劃詞高亮”:
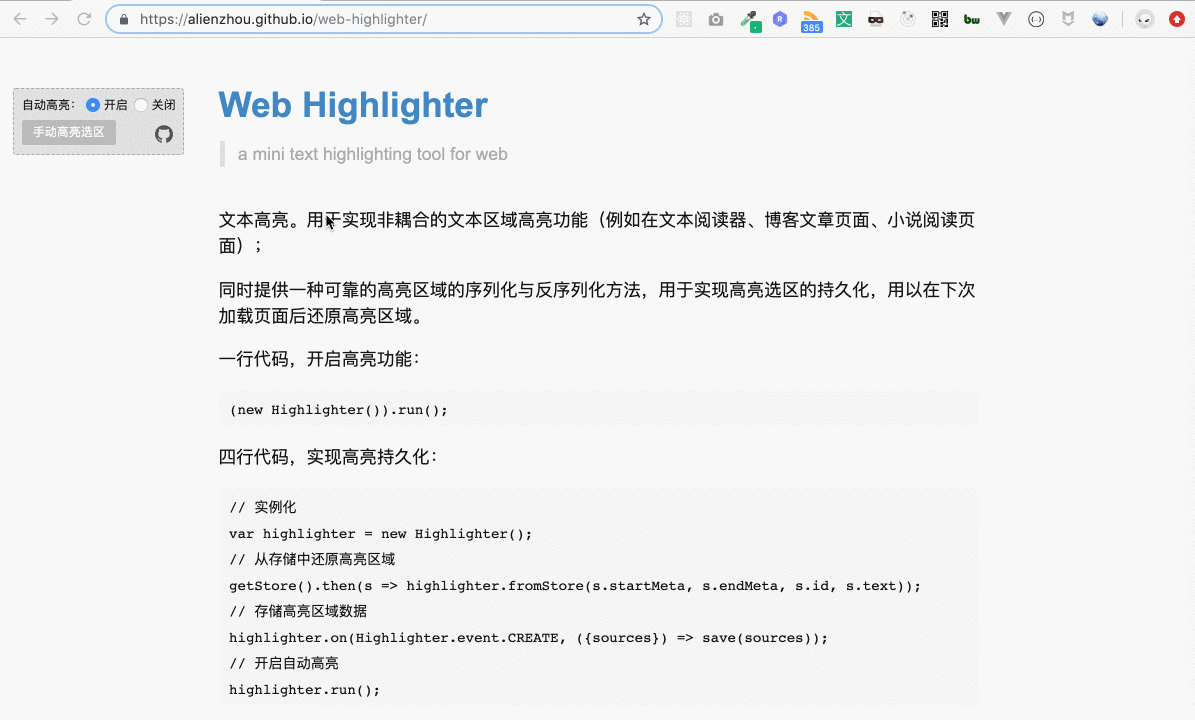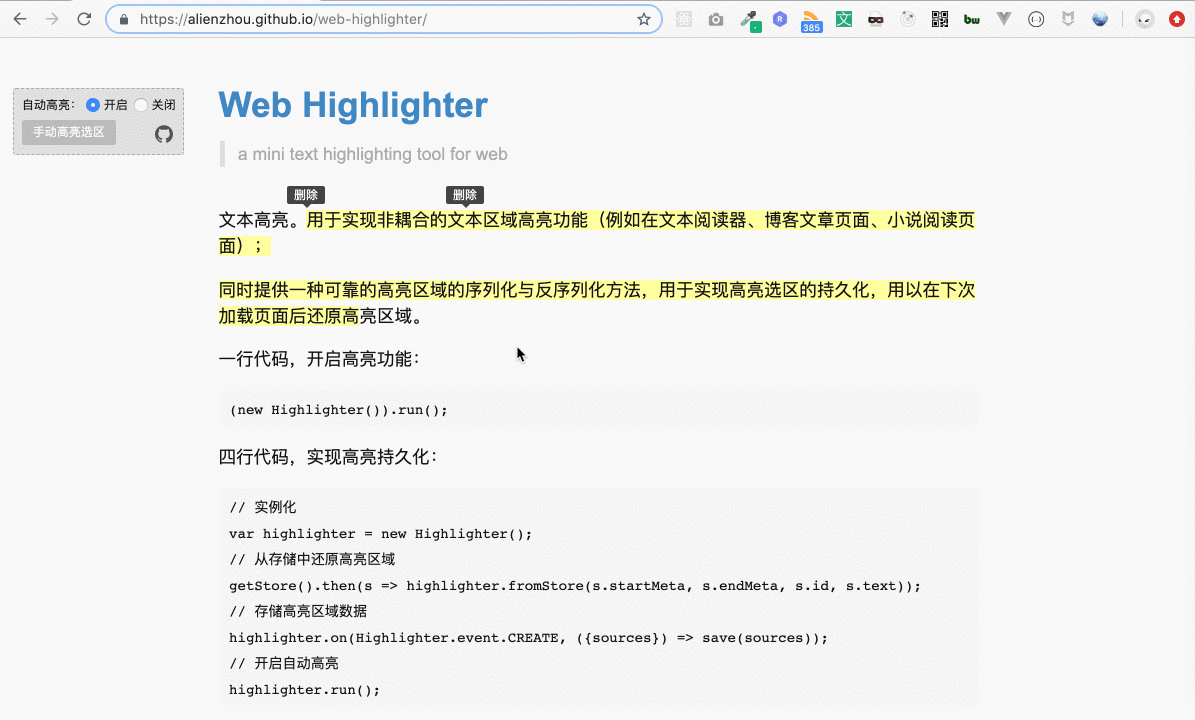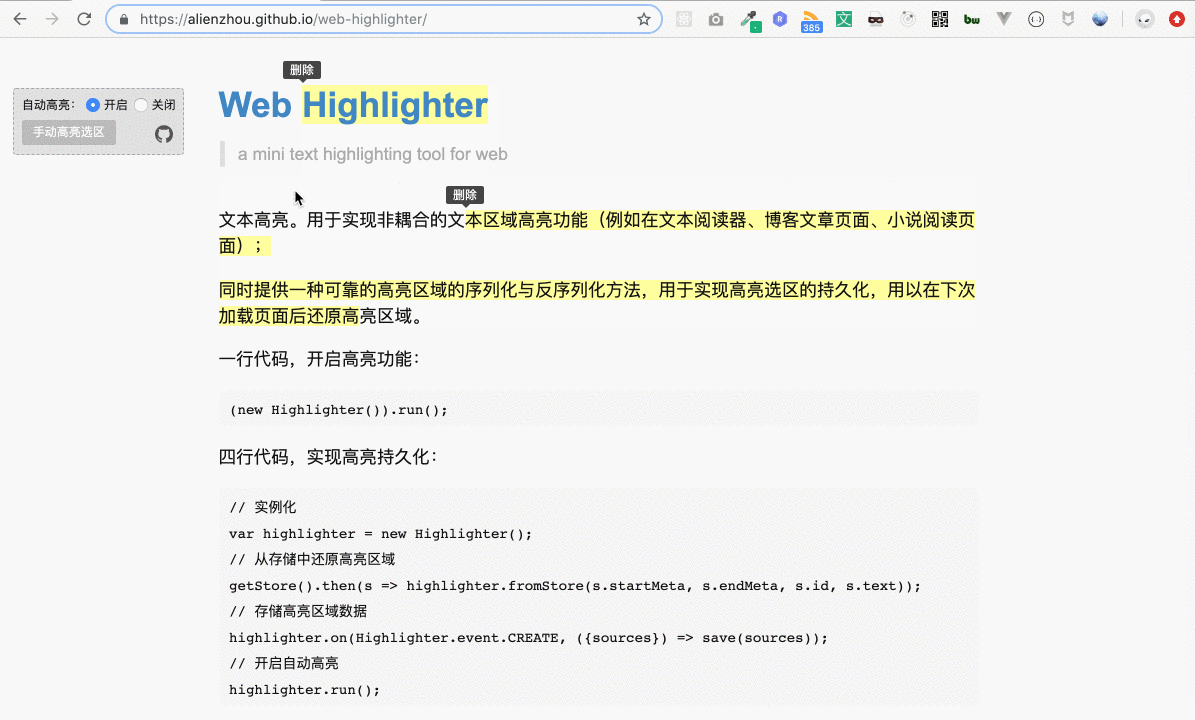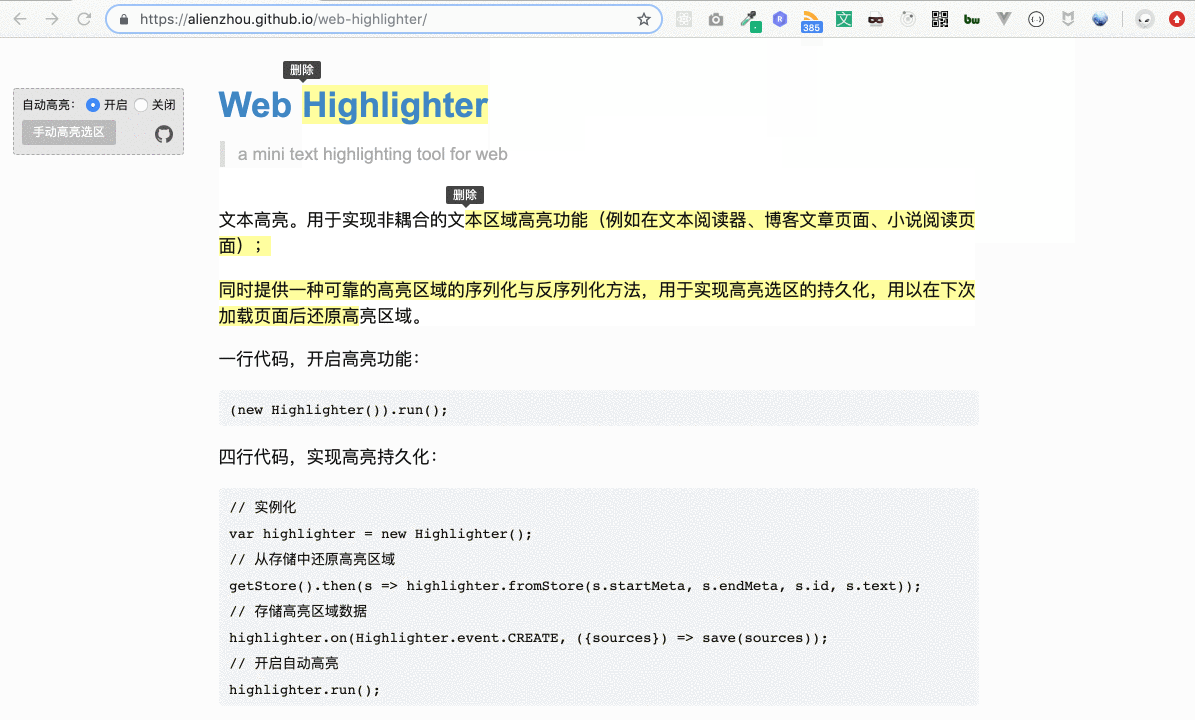
上圖的示例網站可以點擊這里訪問。用戶選擇一段文本(即劃詞),即會自動將這段選取的文本添加高亮背景,用戶可以很方便地為網頁添加在線筆記。
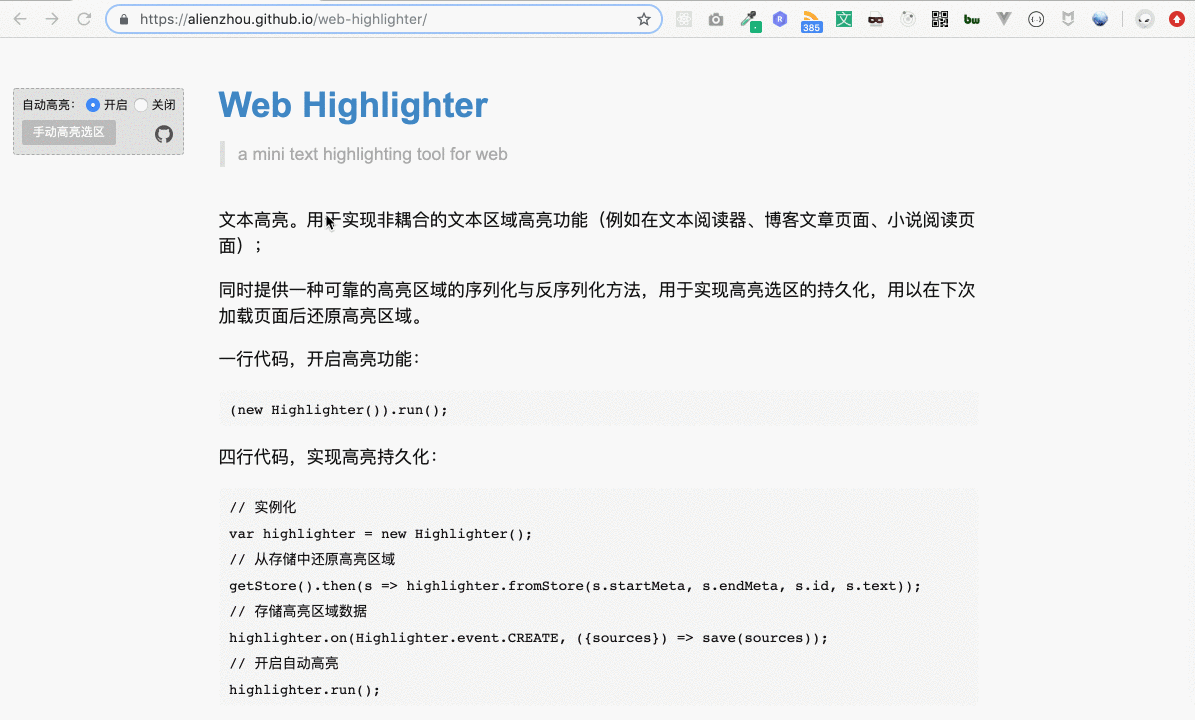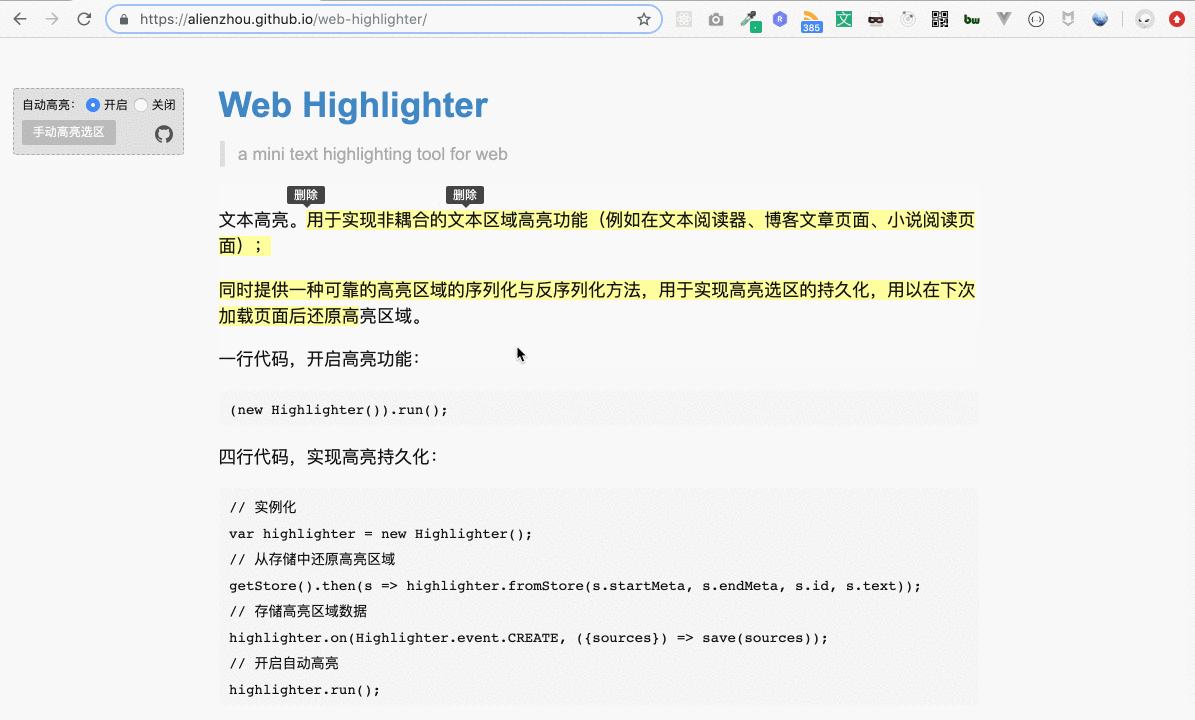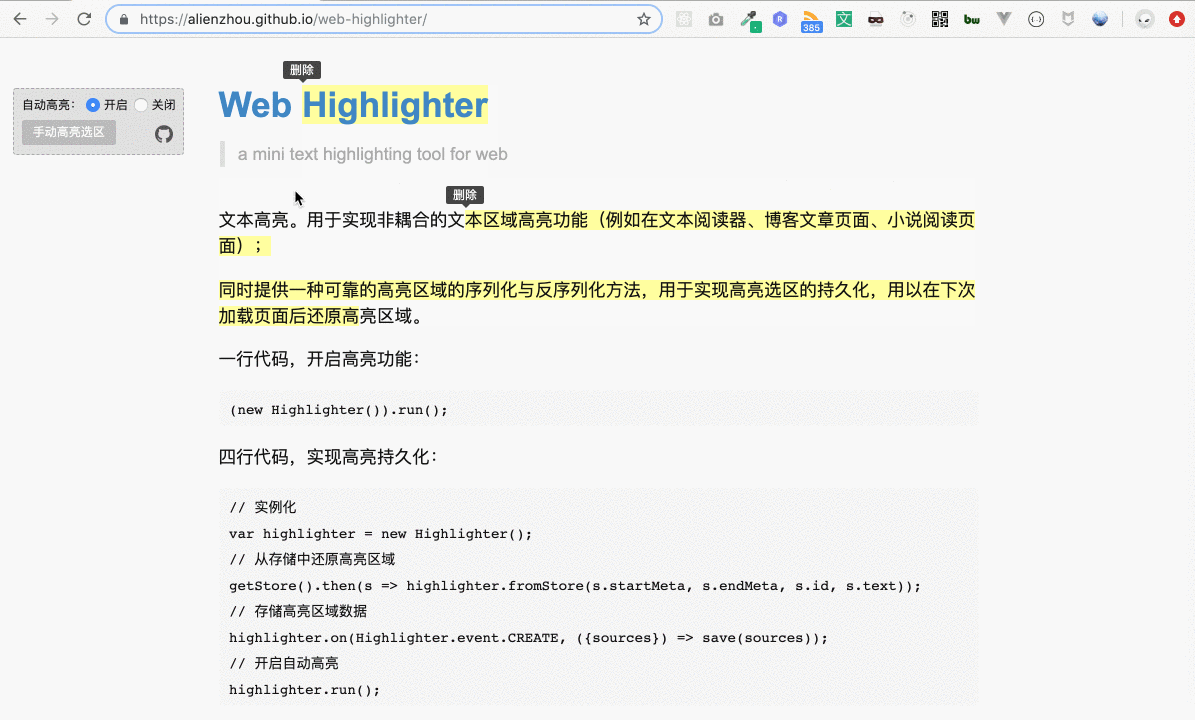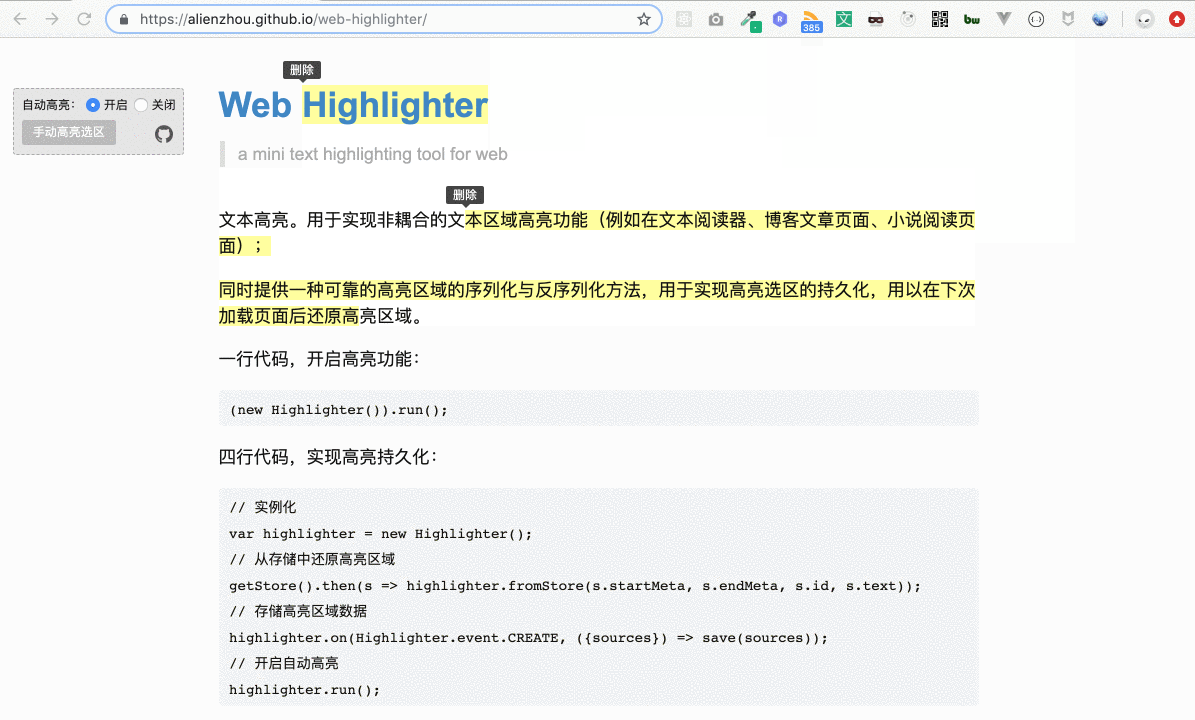
筆者前段時間為線上業務實現了一個與內容結構非耦合的文本高亮筆記功能。非耦合是指不需要為高亮功能建立特殊的頁面 DOM 結構,而高亮功能對業務近乎透明。該功能核心部分具有較強的通用性與移植性,故拿出來和大家分享交流一下。
本文具體的核心代碼已封裝成獨立庫 web-highlighter,閱讀中如有疑問可參考其中代碼↓↓。

2. 實現“劃詞高亮”需要解決哪些問題?
實現一個“劃詞高亮”的在線筆記功能需要解決的核心問題有兩個:
加高亮背景。即如何根據用戶在網頁上的選取,為相應的文本添加高亮背景;
高亮區域的持久化與還原。即如何保存用戶高亮信息,并在下次瀏覽時準確還原,否則下次打開頁面用戶高亮的信息就丟失了。
一般來說,劃詞高亮的業務需求方主要是針對自己產出的內容,你可以比較容易對內容在網頁上的排版、HTML 標簽等方面進行控制。這種情況下,處理高亮需求會更方便一些,畢竟自己可以根據高亮需求調整現有內容的 HTML。
而筆者面對的情況是,頁面 HTML 排版結構復雜,且無法根據高亮需求來推動業務改動 HTML。這也催生出了對解決方案更通用化的要求,目標就是:針對任意內容均可“劃詞高亮”并支持后續訪問時還原高亮狀態,而不用去關心內容的組織結構。
下面就來具體說說,如何解決上面的兩個核心問題。
3. 如何“加高亮背景”?
根據動圖演示我們可以知道,用戶選擇某一段文本(下文稱為“用戶選區”)后,我們會給這段文本加一個高亮背景。
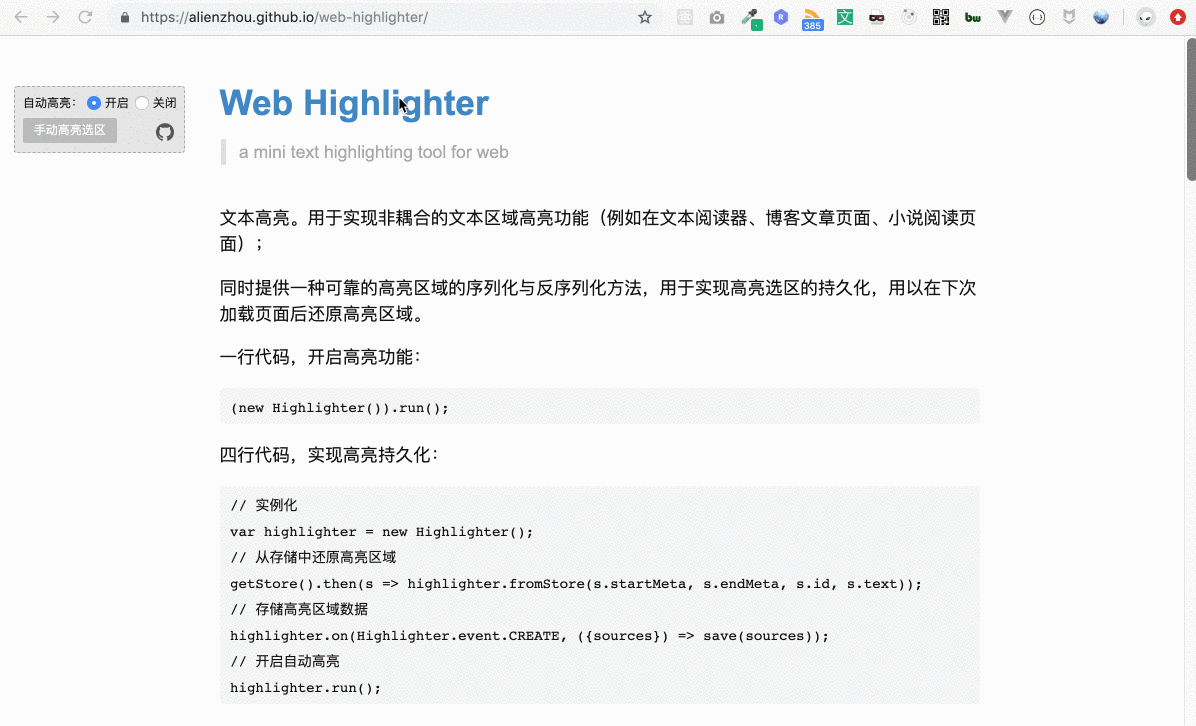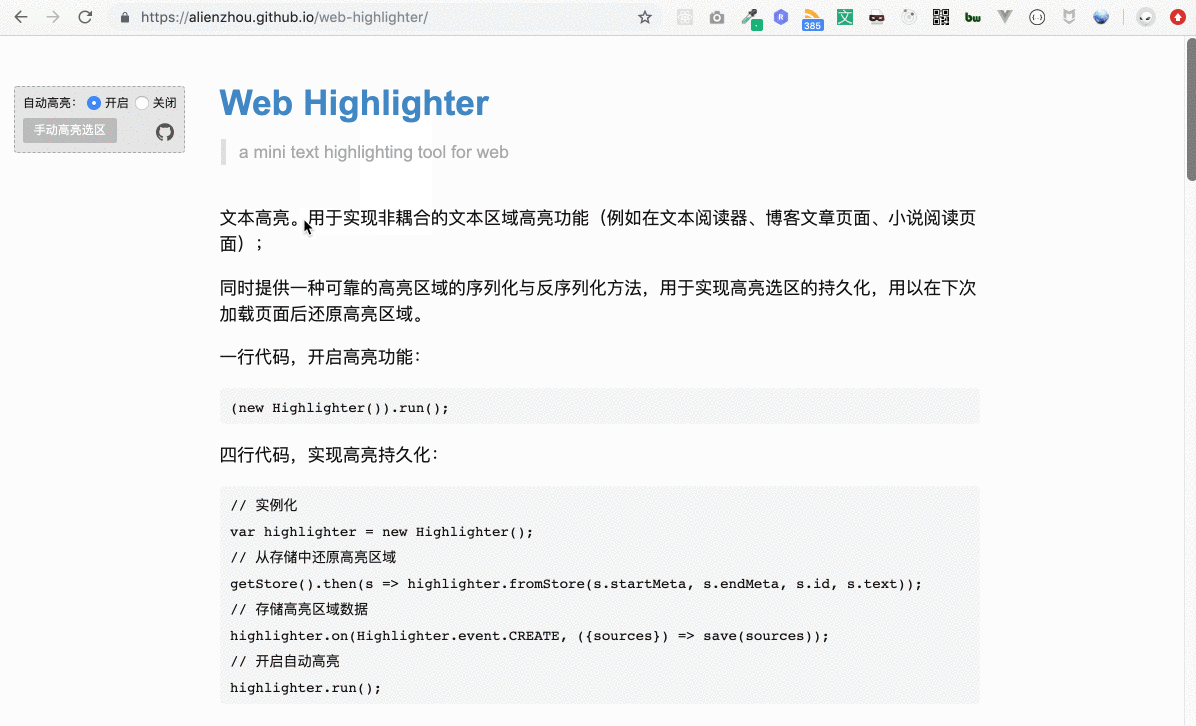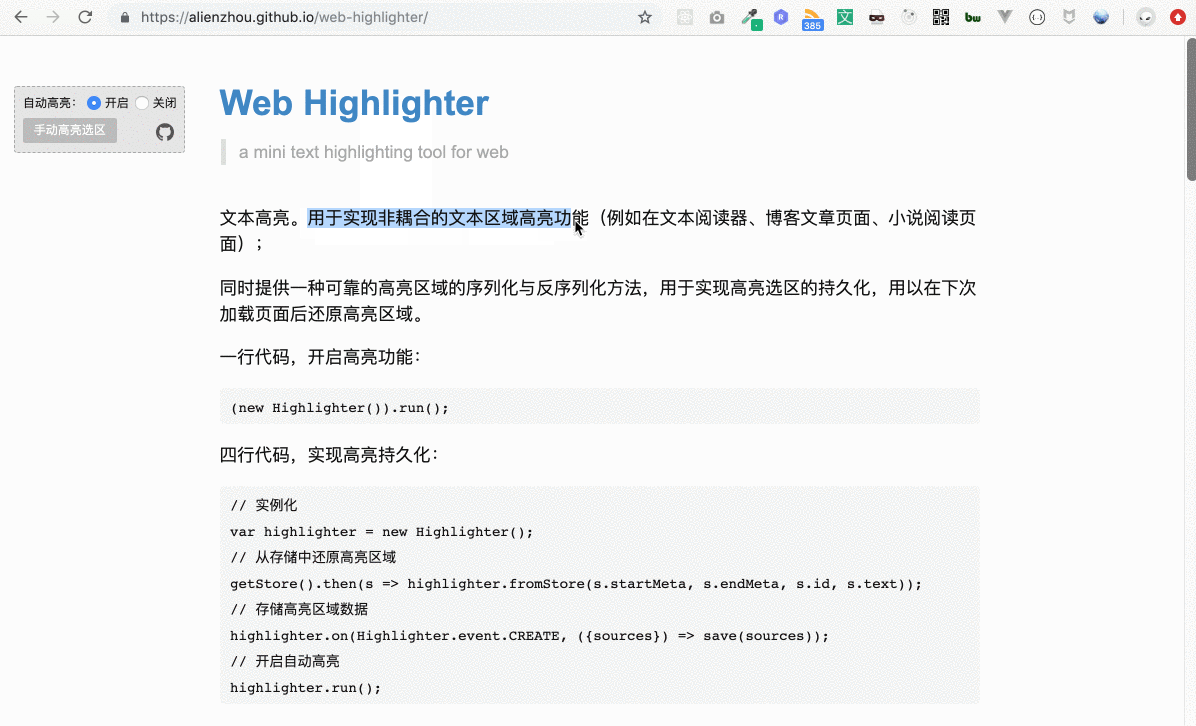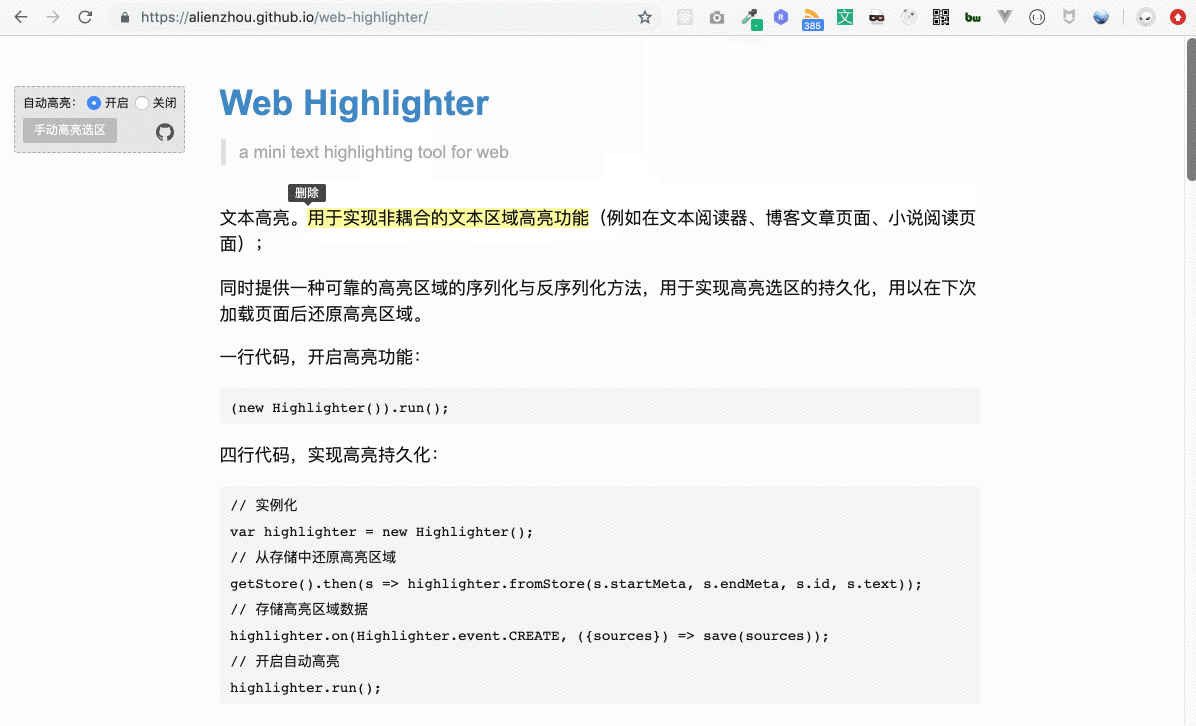
例如用戶選擇了上圖中的文本(即藍色部分)。為其加高亮的基本思路如下:
獲取選中的文本節點:通過用戶選擇的區域信息,獲取所有被選中的所有文本節點;
為文本節點添加背景色:給這些文本節點包裹一層新的元素,該元素具有指定的背景顏色。
3.1. 如何獲取選中的文本節點?
1)Selection API
需要基于瀏覽器為我們提供的 Selection API 。它的兼容性還不錯。如果要支持更低版本的瀏覽器則需要用 polyfill。
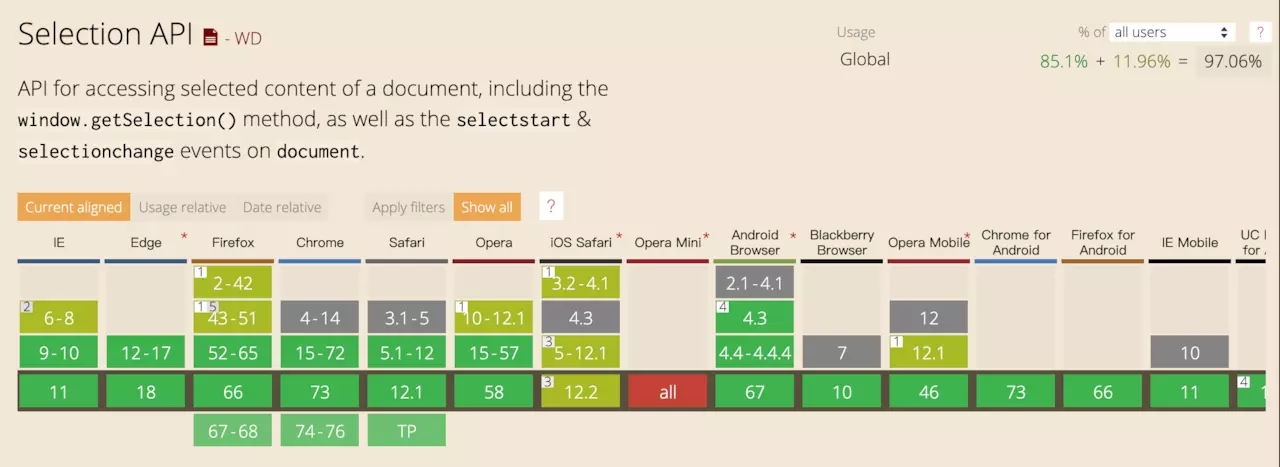
Selection API 可以返回一系列關于用戶選區的信息。那么是不是可以通過它直接獲取選取中的所有 DOM 元素呢?
很遺憾并不能。但好在它可以返回選區的首尾節點信息:
const range = window.getSelection().getRangeAt(0);
const start = {
node: range.startContainer,
offset: range.startOffset
};
const end = {
node: range.endContainer,
offset: range.endOffset
};Range 對象包含了選區的開始與結束信息,其中包括節點(node)與文本偏移量(offset)。節點信息不用多說,這里解釋一下 offset 是指什么:例如,標簽<p>這是一段文本的示例</p>,用戶選取的部分是“一段文本”這四個字,這時首尾的 node 均為 p 元素內的文本節點(Text Node),而 startOffset 和 endOffset 分別為 2 和 6。
2)首尾文本節點拆分
理解了 offset 的概念后,自然就發現有個問題需要解決。由于用戶選區(selection)可能只包含一個文本節點的一部分(即 offset 不為 0),所以我們最后得到的用戶選區所包含的節點里,也只希望有首尾文本節點的這“一部分”。對此,我們可以使用 .splitText() 拆分文本節點:
// 首節點
if (curNode === $startNode) {
if (curNode.nodeType === 3) {
curNode.splitText(startOffset);
const node = curNode.nextSibling;
selectedNodes.push(node);
}
}
// 尾節點
if (curNode === $endNode) {
if (curNode.nodeType === 3) {
const node = curNode;
node.splitText(endOffset);
selectedNodes.push(node);
}
}以上代碼會依據 offset 對文本節點進行拆分。對于開始節點,只需要收集它的后半部分;而對于結束節點則是前半部分。
3)遍歷 DOM 樹
到目前為止,我們準確找到了首尾節點,所以下一步就是找出“中間”所有的文本節點。這就需要遍歷 DOM 樹。
“中間”加上引號是因為,在視覺上這些節點是位于首尾之間的,但由于 DOM 不是線性結構而是樹形結構,所以這個“中間”換成程序語言,就是指深度優先遍歷時,位于首尾兩節點之間的所有文本節點。DFS 的方法有很多,可以遞歸,也可以用棧+循環,這里就不贅述了。
需要提一下的是,由于我們是要為文本節點添加高亮背景,因此在遍歷時只會收集文本節點。
if (curNode.nodeType === 3) {
selectedNodes.push(curNode);
}3.2. 如何為文本節點添加背景色?
這一步本身并不困難。在上一步的基礎上,我們已經選出了所有被用戶選中的 文本節點(包括拆分后的首尾節點)。對此,一個最直接的方法就是為其“包裹上”一個帶背景樣式的元素。
具體的,我們可以給每個文本節點外加上一個 class 為 highlight 的 <span> 元素;而背景樣式則通過 CSS .highlight 選擇器設置。
// 使用上一步中封裝的方法獲取選區內的文本節點
const nodes = getSelectedNodes(start, end);
nodes.forEach(node => {
const wrap = document.createElement('span');
wrap.setAttribute('class', 'highlight');
wrap.appendChild(node.cloneNode(false));
node.parentNode.replaceChild(wrap);
});.highlight {
background: #ff9;
}這樣就可以給被選中的文字添加一個“永久”的高亮背景了。
p.s. 選區的重合問題
然而,文本高亮里還有一個比較棘手的需求 —— 高亮區域的重合。舉個例子,最開始的演示圖(下圖)里,第一個高亮區域和第二個高亮區域之間存在重疊部分,即“本區域高”四個字。
這個問題目前來看似乎還不是問題,但在結合下面要提到的一些功能與需求時,就會變成非常麻煩,甚至無法正常運行(一些開源庫這塊處理也不盡如人意,這也是沒有選擇它們的一個原因)。這里簡單提一下,具體的情況我會放到后續對應的地方再詳細說。
4. 如何實現高亮選區的持久化與還原?
到目前我們已經可以給選中的文本添加高亮背景了。但還有一個大問題:
想象一下,用戶辛辛苦苦劃了很多重點(高亮),開心地退出頁面后,下次訪問時發現這些都不能保存時,該有多么得沮喪。因此,如果只是在頁面上做“一次性”的文本高亮,那它的使用價值會大大降低。這也就促使我們的“劃詞高亮”功能要能夠保存(持久化)這些高亮選區并正確還原。
持久化高亮選區的核心是找到一種合適的 DOM 節點序列化方法。
通過第三部分可以知道,當確定了首尾節點與文本偏移(offset)信息后,即可為其間文本節點添加背景色。其中,offset 是數值類型,要在服務器保存它自然沒有問題;但是 DOM 節點不同,在瀏覽器中保存它只需要賦值給一個變量,但想在后端保存所謂的 DOM 則不那么直接了。
4.1 序列化 DOM 節點標識
所以這里的核心點就是找到一種方法,能夠定位 DOM 節點,同時可以被保存成普通的 JSON Object,用以傳給后端保存,這個過程在本文中被稱為 DOM 標識 的“序列化”。而下次用戶訪問時,又可以從后端取回,然后“反序列化”為對應的 DOM 節點。
有幾種常見的方式來標識 DOM 節點:
使用 xPath
使用 CSS Selector 語法
使用 tagName + index
這里選擇了使用第三種方式來快速實現。需要注意一點,我們通過 Selection API 取到的首尾節點一般是文本節點,而這里要記錄的 tagName 和 index 都是該文本節點的父元素節點(Element Node)的,而 childIndex 表示該文本節點是其父親的第幾個兒子:
function serialize(textNode, root = document) {
const node = textNode.parentElement;
let childIndex = -1;
for (let i = 0; i < node.childNodes.length; i++) {
if (textNode === node.childNodes[i]) {
childIndex = i;
break;
}
}
const tagName = node.tagName;
const list = root.getElementsByTagName(tagName);
for (let index = 0; index < list.length; index++) {
if (node === list[index]) {
return {tagName, index, childIndex};
}
}
return {tagName, index: -1, childIndex};
}通過該方法返回的信息,再加上 offset 信息,即定位選取的起始位置,同時也完全可發送給后端進行保存了。
4.2 反序列化 DOM 節點
基于上一節的序列化方法,從后端獲取到數據后,可以很容易反序列化為 DOM 節點:
function deSerialize(meta, root = document) {
const {tagName, index, childIndex} = meta;
const parent = root.getElementsByTagName(tagName)[index];
return parent.childNodes[childIndex];
}至此,我們大體已經解決了兩個核心問題,這似乎已經是一個可用版本了。但其實不然,根據實踐經驗,如果僅僅是上面這些處理,往往是無法應對實際需求的,存在一些“致命問題”。
但不用灰心,下面會具體來說說所謂的“致命問題”是什么,而又是如何解決并實現一個線上業務可用的通用“劃詞高亮”功能的。
5. 如何實現一個生產環境可用的“劃詞高亮”?
1)上面的方案有什么問題?
首先來看看上面的方案會有什么問題。
當我們需要高亮文本時,會為文本節點包裹span元素,這就改動了頁面的 DOM 結構。它可能會導致后續高亮的首尾節點與其 offset 信息其實是基于被改動后的 DOM 結構的。帶來的結果有兩個:
下次訪問時,程序必須按上次用戶高亮的順序還原。
用戶不能隨意取消(刪除)高亮區域,只能按添加順序從后往前刪。
否則,就會有部分的高亮選區在還原時無法定位到正確的元素。
文字可能不好理解,下面我舉個例子來直觀解釋下這個問題。
<p> 非常高興今天能夠在這里和大家分享一下文本高亮的實現方式。 </p>
對于上面這段 HTML,用戶分別按順序高亮了兩個部分:“高興”和“文本高亮”。那么按照上面的實現方式,這段 HTML 變成了下面這樣:
<p> 非常 <span class="highlight">高興</span> 今天能夠在這里和大家分享一下 <span class="highlight">文本高亮</span> 的實現方式。 </p>
對應的兩個序列化數據分別為:
// “高興”兩個字被高亮時獲取的序列化信息
{
start: {
tagName: 'p',
index: 0,
childIndex: 0,
offset: 2
},
end: {
tagName: 'p',
index: 0,
childIndex: 0,
offset: 4
}
}// “文本高亮”四個字被高亮時獲取的序列化信息。
// 這時候由于p下面已經存在了一個高亮信息(即“高興”)。
// 所以其內部 HTML 結構已被修改,直觀來說就是 childNodes 改變了。
// 進而,childIndex屬性由于前一個 span 元素的加入,變為了 2。
{
start: {
tagName: 'p',
index: 0,
childIndex: 2,
offset: 14
},
end: {
tagName: 'p',
index: 0,
childIndex: 2,
offset: 18
}
}可以看到,“文本高亮”這四個字的首尾節點的 childIndex 都被記為 2,這是由于前一個高亮區域改變了<p>元素下的DOM結構。如果此時“高興”選區的高亮被用戶取消,那么下次再訪問頁面就無法還原高亮了 —— “高興”選區的高亮被取消了,<p>下自然就不會出現第三個 childNode,那么 childIndex 為 2 就找不到對應的節點了。這就導致存儲的數據在還原高亮選區時出現問題。
此外,還記得在第三部分末尾提到的高亮選取重合問題么?支持選取重合很容易出現如下的包裹元素嵌套情況:
<p> 非常 <span class="highlight">高興</span> 今天能夠在這里和大家分享一下 <span class="highlight"> 文本 <span class="highlight">高涼</span> </span> 的實現方式。 </p>
這也使得某個文本區域經過多次高亮、取消高亮后,會出現與原 HTML 頁面不同的復雜嵌套結構。可以預見,當我們使用 xpath 或 CSS selector 作為 DOM 標識時,上面提到的問題也會出現,同時也使其他需求的實現更加復雜。
到這里可以提一下其他開源庫或產品是如何處理選區重合問題的:
開源庫 Rangy 有一個 Highlighter 模塊可以實現文本高亮,但其對于選區重合的情況是將兩個選區直接合并了,這是不合符我們業務需求的。
付費產品 Diigo 直接不允許選區的重合。
Medium.com 是支持選區重合的,體驗非常不錯,這也是我們產品的目標。但它頁面的內容區結構相較我面對的情況會更簡單與更可控。
所以如何解決這些問題呢?
2)另一種序列化 / 反序列化方式
我會對第四部分提到的序列化方式進行改進。仍然記錄文本節點的父節點 tagName 與 index,但不再記錄文本節點在 childNodes 中的 index 與 offset,而是記錄開始(結束)位置在整個父元素節點中的文本偏移量。
例如下面這段 HTML:
<p> 非常 <span class="highlight">高興</span> 今天能夠在這里和大家分享一下 <span class="highlight">文本高亮</span> 的實現方式。 </p>
對于“文本高亮”這個高亮選區,之前用于標識文本起始位置的信息為childIndex = 2, offset = 14。而現在變為offset = 18(從<p>元素下第一個文本“非”開始計算,經過18個字符后是“文”)。可以看出,這樣表示的優點是,不管<p>內部原有的文本節點被<span>(包裹)節點如何分割,都不會影響高亮選區還原時的節點定位。
據此,在序列化時,我們需要一個方法來將文本節點內偏移量“翻譯”為其對應的父節點內部的總體文本偏移量:
function getTextPreOffset(root, text) {
const nodeStack = [root];
let curNode = null;
let offset = 0;
while (curNode = nodeStack.pop()) {
const children = curNode.childNodes;
for (let i = children.length - 1; i >= 0; i--) {
nodeStack.push(children[i]);
}
if (curNode.nodeType === 3 && curNode !== text) {
offset += curNode.textContent.length;
}
else if (curNode.nodeType === 3) {
break;
}
}
return offset;
}而還原高亮選區時,需要一個對應的逆過程:
function getTextChildByOffset(parent, offset) {
const nodeStack = [parent];
let curNode = null;
let curOffset = 0;
let startOffset = 0;
while (curNode = nodeStack.pop()) {
const children = curNode.childNodes;
for (let i = children.length - 1; i >= 0; i--) {
nodeStack.push(children[i]);
}
if (curNode.nodeType === 3) {
startOffset = offset - curOffset;
curOffset += curNode.textContent.length;
if (curOffset >= offset) {
break;
}
}
}
if (!curNode) {
curNode = parent;
}
return {node: curNode, offset: startOffset};
}3)支持高亮選區的重合
重合的高亮選區帶來的一個問題就是高亮包裹元素的嵌套,從而使得 DOM 結構會有較復雜的變動,增加了其他功能(交互)實現與問題排查的復雜度。因此,我在 3.2. 節提到的包裹高亮元素時,會再進行一些稍復雜的處理(尤其是重合選區),以保證盡量復用已有的包裹元素,避免元素的嵌套。
在處理時,將需要包裹的各個文本片段(Text Node)分為三類情況:
完全未被包裹,則直接包裹該部分。
屬于被包裹過的文本節點的一部分,則使用.splitText()將其拆分。
是一段完全被包裹的文本段,不需要對節點進行處理。
于此同時,為每個選區生成唯一 ID,將該段文本幾點多對應的 ID、以及其由于選區重合所涉及到的其他 ID,都附加包裹元素上。因此像上面的第三種情況,不需要變更 DOM 結構,只用更新包裹元素兩類 ID 所對應的 dataset 屬性即可。
6. 其他問題
解決以上的一些問題后,“文本劃詞高亮”就基本可用了。還剩下一些“小修補”,簡單提一下。
6.1. 高亮選區的交互事件,例如 click、hover
首先,可以為每個高亮選區生成一個唯一 ID,然后在該選區內所有的包裹元素上記錄該 ID 信息,例如用data-highlight-id屬性。而對于選取重合的部分可以在data-highlight-extra-id屬性中記錄重合的其他選區的 ID。
而監聽到包裹元素的 click、hover 后,則觸發 highlighter 的相應事件,并帶上高亮 ID。
6.2. 取消高亮(高亮背景的刪除)
由于在包裹時支持選區重合(對應會有上面提到的三種情況需要處理),因此,在刪除選取高亮時,也會有三種情況需要分別處理:
直接刪除包裹元素。即不存在選區重合。
更新data-highlight-id屬性和data-highlight-extra-id屬性。即刪除的高亮 ID 與 data-highlight-id 相同。
只更新data-highlight-extra-id屬性。即刪除的高亮 ID 只在 data-highlight-extra-id 中。
6.3. 對于前端生成的動態頁面怎么辦?
不難發現,這種非耦合的文本高亮功能很依賴于頁面的 DOM 結構,需要保證做高亮時的 DOM 結構和還原時的一致,否則無法正確還原出選區的起始節點位置。據此,對“劃詞”高亮最友好的應該是純后端渲染的頁面,在onload監聽中觸發高亮選區還原的方法即可。但目前越來越多的頁面(或頁面的一部分)是前端動態生成的,針對這個問題該怎么處理呢?
我在實際工作中也遇到了類似問題 —— 頁面的很多區域是 ajax 請求后前端渲染的。我的處理方式包括如下:
隔離變化范圍。將上述代碼中的“根節點”從documentElement換為另一個更具體的容器元素。例如我面對的業務會在 id 為 article-container 的<div>內加載動態內容,那么我就會指定這個 article-container 為“根節點”。這樣可以最大程度防止外部的 DOM 變動影響到高亮位置的定位,尤其是頁面改版。
確定高亮選區的還原時機。由于內容可能是動態生成,所以需要等到該部分的 DOM 渲染完成后再調用還原方法。如果有暴露的監聽事件可以在監聽內處理;或者通過 MutationObserver 監聽標志性元素來判斷該部分是否加載完成。
記錄業務內容信息,應對內容區改版。內容區的 DOM 結構更改算是“毀滅性打擊”。如何確實有該類情況,可以嘗試讓業務內容展示方將段落信息等具體的內容信息綁定在 DOM 元素上,而我在高亮時取出這些信息來冗余存儲,改版后可以通過這些內容信息“刷”一遍存儲的數據。
6.4. 其他
篇幅問題,還有其他細節的問題就不在這篇文章里分享了。詳細內容可以參考 web-highlighter 這個倉庫里的實現。
7. 總結
本文先從“劃詞高亮”功能的兩個核心問題(如何高亮用戶選區的文本、如何將高亮選區還原)切入,基于 Selection API、深度優先遍歷和 DOM 節點標識的序列化這些手段實現了“劃詞高亮”的核心功能。然而,該方案仍然存在一些實際問題,因此在第 5 部分進一步給出了相應的解決方案。
基于實際開發的經驗,我發現解決上述幾個“劃詞高亮”核心問題的代碼具有一定通用性,因此把核心部分的源碼封裝成了獨立的庫 web-highlighter,托管在 github,也可以通過 npm 安裝。
其已服務于線上產品業務,基本的高亮功能一行代碼即可開啟:
(new Highlighter()).run();
兼容IE 10/11、Edge、Firefox 52+、Chrome 15+、Safari 5.1+、Opera 15+。
感謝你能夠認真閱讀完這篇文章,希望小編分享的“js如何實現一個通用的“劃詞高亮”在線筆記功能”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





