溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編這次要給大家分享的是怎么使用python中groupby函數,文章內容豐富,感興趣的小伙伴可以來了解一下,希望大家閱讀完這篇文章之后能夠有所收獲。
一、groupby 能做什么?
python中groupby函數主要的作用是進行數據的分組以及分組后地組內運算!
對于數據的分組和分組運算主要是指groupby函數的應用,具體函數的規則如下:
df[](指輸出數據的結果屬性名稱).groupby([df[屬性],df[屬性])(指分類的屬性,數據的限定定語,可以有多個).mean()(對于數據的計算方式——函數名稱)
舉例如下:
print(df["評分"].groupby([df["地區"],df["類型"]]).mean()) #上面語句的功能是輸出表格所有數據中不同地區不同類型的評分數據平均值
二、單類分組
A.groupby("性別")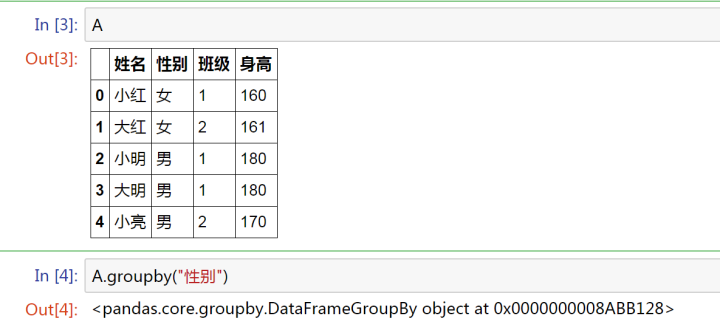
首先,我們有一個變量A,數據類型是DataFrame
想要按照【性別】進行分組
得到的結果是一個Groupby對象,還沒有進行任何的運算。
describe()
描述組內數據的基本統計量
A.groupby("性別").describe().unstack()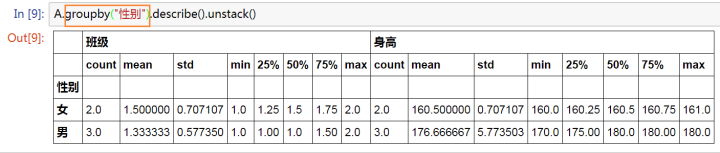
* 只有數字類型的列數據才會計算統計
* 示例里面數字類型的數據有兩列 【班級】和【身高】
但是,我們并不需要統計班級的均值等信息,只需要【身高】,所以做一下小的改動:
A.groupby("性別")["身高"].describe().unstack()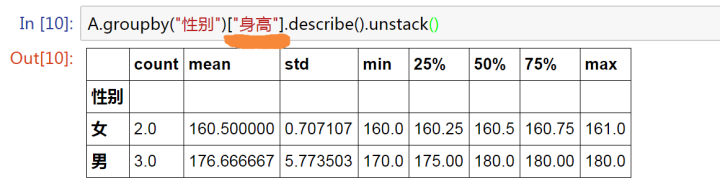
unstack()
索引重排
上面的例子里面用到了一個小的技巧,讓運算結果更便于對比查看,感興趣的同學可以自行去除unstack,比較一下顯示的效果
三、多類分組
A.groupby( ["班級","性別"])
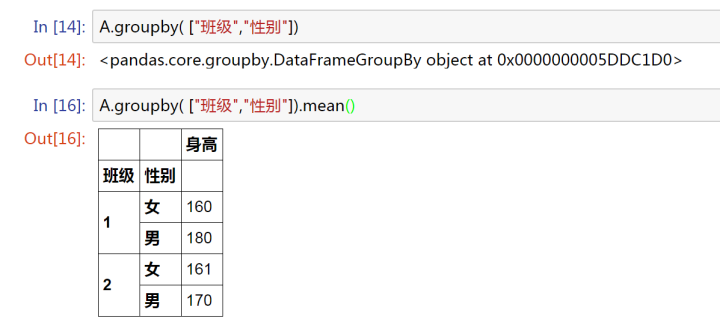
單獨用groupby,我們得到的還是一個 Groupby 對象。
mean()
組內均值計算
DataFrame的很多函數可以直接運用到Groupby對象上。
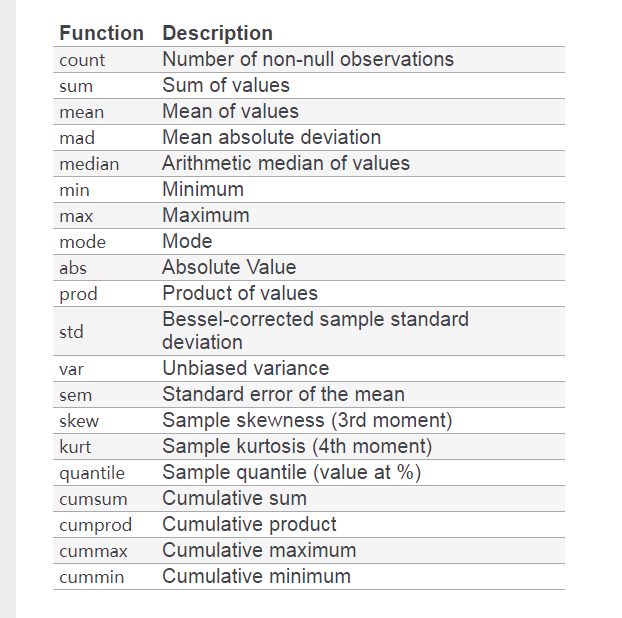
上圖截自 pandas 官網 document,這里就不一一細說。
我們還可以一次運用多個函數計算
A.groupby( ["班級","性別"]).agg([np.sum, np.mean, np.std]) # 一次計算了三個
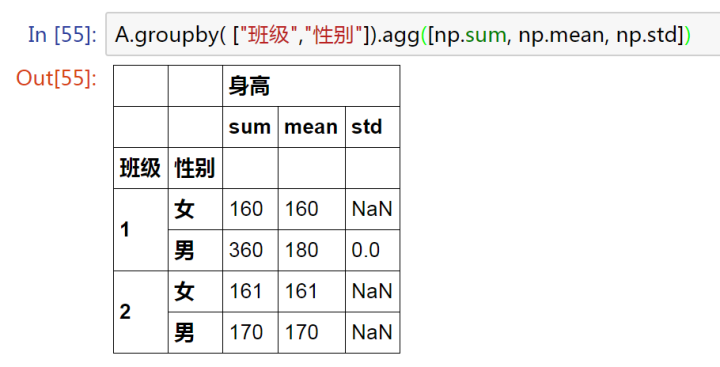
agg()
分組多個運算
四、時間分組
時間序列可以直接作為index,或者有一列是時間序列,差別不是很大。
這里僅僅演示,某一列為時間序列。
為A 新增一列【生日】,由于分隔符 “/” 的問題,我們查看列屬性,【生日】的屬性并不是日期類型
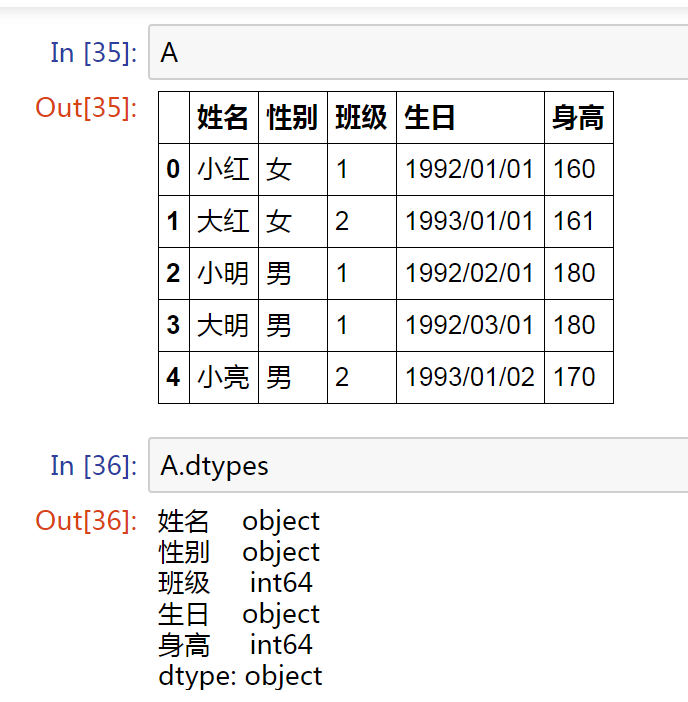
我們想做的是:
1、按照【生日】的【年份】進行分組,看看有多少人是同齡?
A["生日"] = pd.to_datetime(A["生日"],format ="%Y/%m/%d") # 轉化為時間格式 A.groupby(A["生日"].apply(lambda x:x.year)).count() # 按照【生日】的【年份】分組
進一步,我們想選拔:
2、同一年作為一個小組,小組內生日靠前的那一位作為小隊長:
A.sort_values("生日", inplace=True) # 按時間排序
A.groupby(A["生日"].apply(lambda x:x.year),as_index=False).first() 
as_index=False
保持原來的數據索引結果不變
first()
保留第一個數據
Tail(n=1)
保留最后n個數據
再進一步:
3、想要找到哪個月只有一個人過生日
A.groupby(A["生日"].apply(lambda x:x.month),as_index=False) # 到這里是按月分組 A.groupby(A["生日"].apply(lambda x:x.month),as_index=False).filter(lambda x: len(x)==1)

filter()
對分組進行過濾,保留滿足()條件的分組
以上就是 groupby 最經常用到的功能了。
用 first(),tail()截取每組前后幾個數據
用 apply()對每組進行(自定義)函數運算
用 filter()選取滿足特定條件的分組
看完這篇關于怎么使用python中groupby函數的文章,如果覺得文章內容寫得不錯的話,可以把它分享出去給更多人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





