溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
groupby中怎么重置索引,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
1. 先加載數據
df = pd.read_excel(r"D:\我的文檔\jupyter.xlsx") df
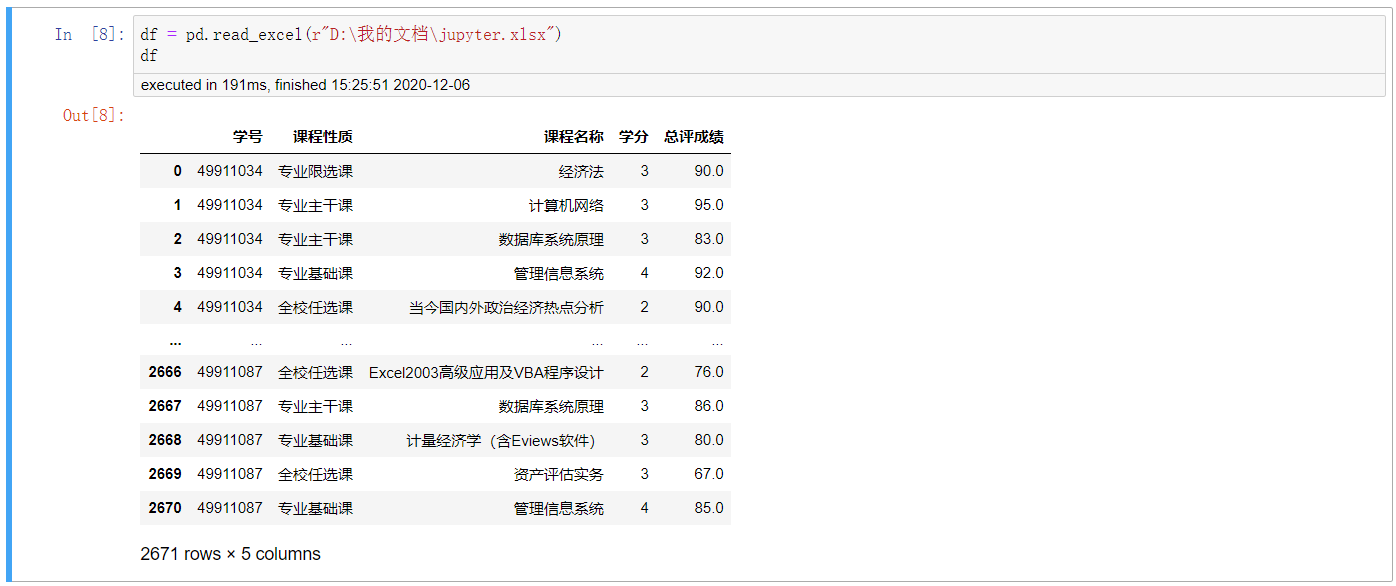
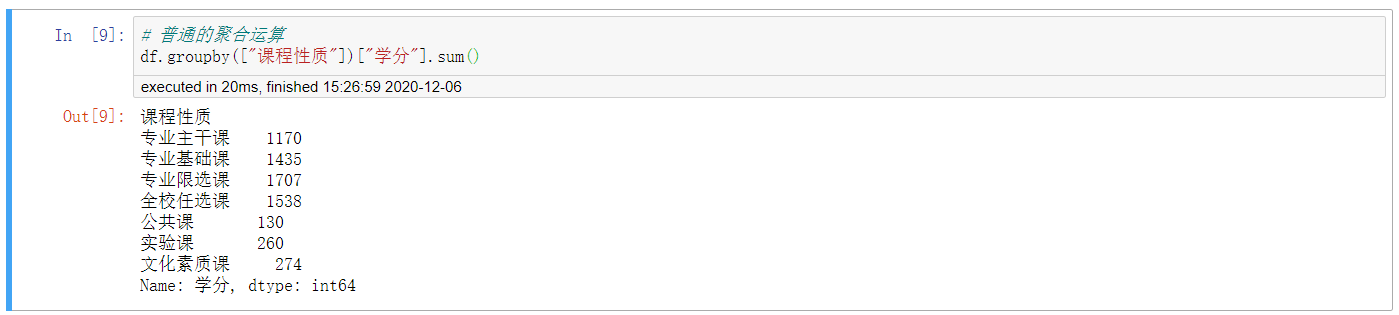
2. 常規的聚合運算
# 普通的聚合運算 df.groupby(["課程性質"])["學分"].sum()
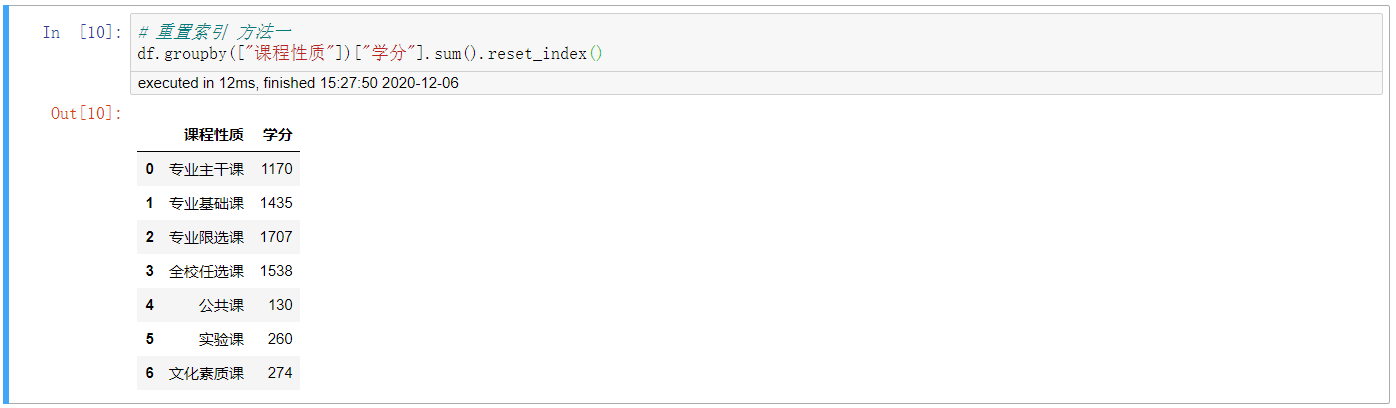
3. 重置索引 方法一
# 重置索引 方法一 df.groupby(["課程性質"])["學分"].sum().reset_index()
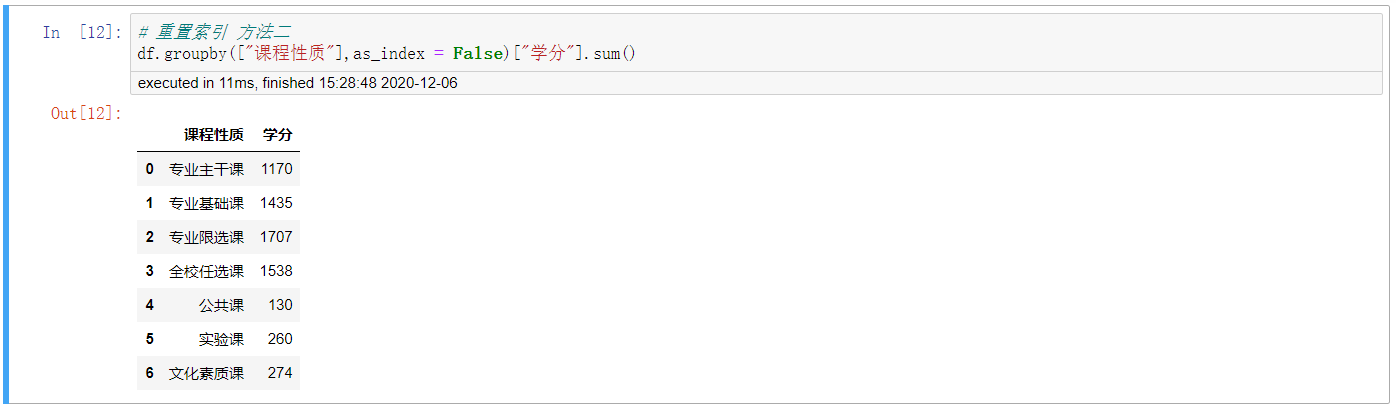
4. 重置索引 方法二
# 重置索引 方法二 df.groupby(["課程性質"],as_index = False)["學分"].sum()
如果看不清楚,請在看下面:
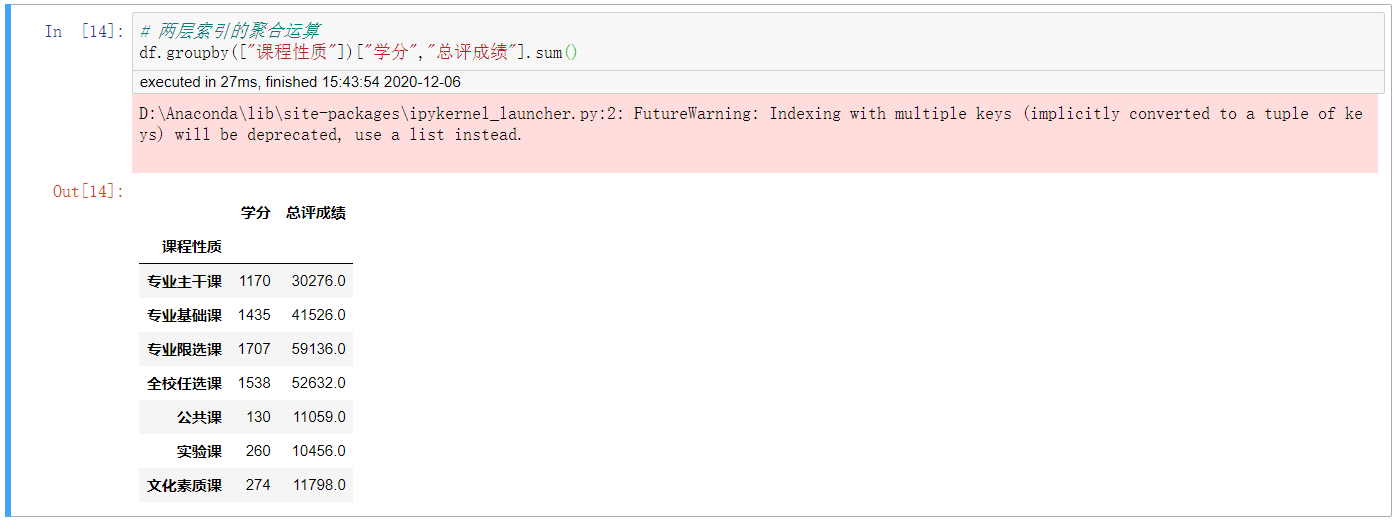
5. 帶兩組變元(下面的兩層索引純屬筆誤,但懶得改了)的聚合運算
# 兩層索引的聚合運算 df.groupby(["課程性質"])["學分","總評成績"].sum()
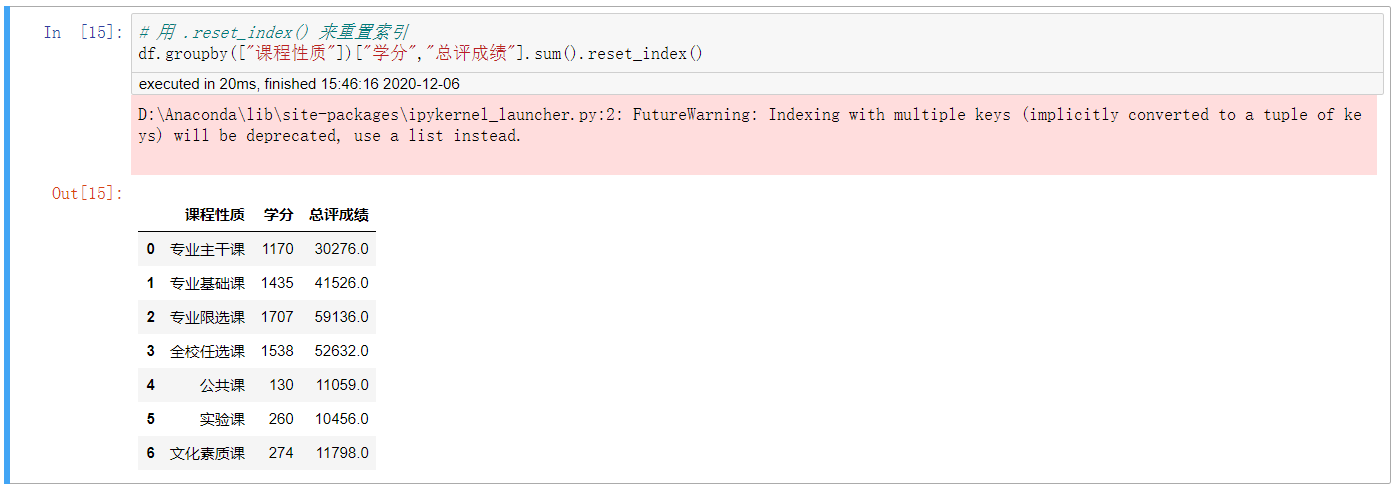
6. 用 .reset_index() 來重置索引
# 用 .reset_index() 來重置索引 df.groupby(["課程性質"])["學分","總評成績"].sum().reset_index()
7. 用 .groupby(as_index = False) 來重置索引
# 用 .groupby(as_index = False) 來重置索引 df.groupby(["課程性質"],as_index = False)["學分","總評成績"].sum()

看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





