溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“python爬蟲實例代碼分析”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“python爬蟲實例代碼分析”吧!
虎撲體育-NBA球員得分數據排行 第1頁
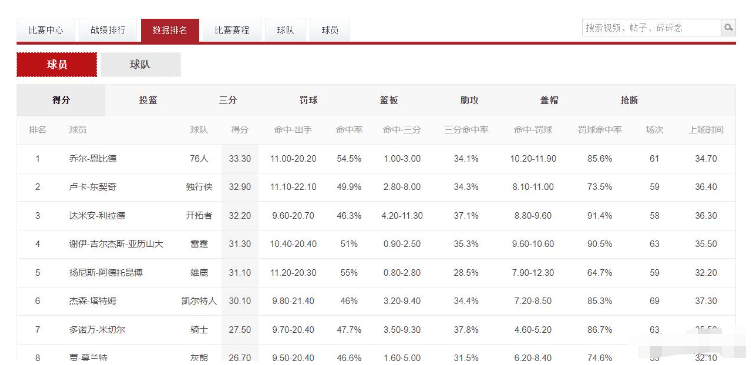
示例代碼:
import requests
from lxml import etree
url = 'https://nba.hupu.com/stats/players'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
}
res = requests.get(url=url, headers=headers)
print(res)
# 處理請求結果
e = etree.HTML(res.text)
# 解析響應的數據
player = e.xpath('//*[@id="data_js"]/div[4]/div/table/tbody/tr/td[2]/a/text()')
team = e.xpath('//*[@id="data_js"]/div[4]/div/table/tbody/tr/td[3]/a/text()')
hit_rate = e.xpath('//*[@id="data_js"]/div[4]/div/table/tbody/tr/td[6]/text()')[1:]
score = e.xpath('//*[@id="data_js"]/div[4]/div/table/tbody/tr/td[4]/text()')[1:]
for p, t, h, s in zip(player, team, hit_rate, score):
print(f"隊員:{p},球隊:{t},命中率:{h},得分:{s}")運行結果:
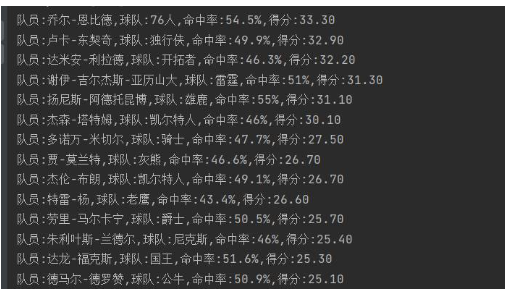
感謝各位的閱讀,以上就是“python爬蟲實例代碼分析”的內容了,經過本文的學習后,相信大家對python爬蟲實例代碼分析這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





