溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“python爬蟲方法實例分析”,在日常操作中,相信很多人在python爬蟲方法實例分析問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”python爬蟲方法實例分析”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
1、Requests庫:使用原理和方法
2、BeautifulSoup庫:使用原理和方法
3、Requests庫和BeautifulSoup庫組合應用:舉例實踐
Requests庫
import requests
res=requests.get('http://bj.xiaozhu.com/')
print(res)#返回結果為<Response [200]>,說明請求網址成功,若為404,400則請求網址失敗
print(res.text)
輸出如下圖:

有時候爬蟲需要加入請求頭來偽裝成瀏覽器,以便更好抓取數據,在開發者工具中點擊Network并且選擇name,然后查看headers下拉查看到:User-Agent
請求頭的使用方法:
import requests
headers={}
res=requests.get('http://bj.xiaozhu.com/',headers=headers)
print(res.text)
Requests庫錯誤和異常主要有以下4種:
1、Requests拋出一個ConnectionError異常,網絡問題(如DNS查詢失敗、拒絕連接等)
2、Response.raise_for_status()拋出一個HTTPError異常,原因為HTTP請求返回了不成功的狀態碼(網頁不存在,返回404錯誤)
3、Response拋出一個Timeout異常,原因為請求超時
4、Response拋出一個TooManyRedirects異常,原因為請求超過了設定的最大重定向次數
所有異常繼承自:requests.exceptions.RequestException
為了避免異常:
import requests
headers={}
res=requests.get('http://bj.xiaozhu.com/',headers=headers)
try:
print(res.text)
except ConnectionError:
print('拒絕連接')
BeautifulSoup庫
BeautifulSoup庫可以輕松解析Requests庫請求的網頁,并把網頁源代碼解析為Soup文檔,以便過濾提取數據。
import requests
from bs4 import BeautifulSoup
headers={}
res=requests.get('http://bj.xiaozhu.com/',headers=headers)
soup=BeautifulSoup(res.text,'html.parser')
print(soup.prettify())
輸出Soup文檔按照標準縮進格式結構輸出,為結構化的數據,為數據的過濾提取做好準備。
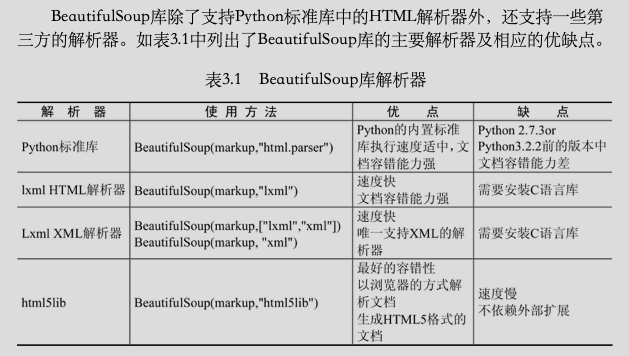
注意:BeautifulSoup庫官方推薦使用lxml作為解析器,因為效率更高。
解析得到的Soup文檔可以使用find()和find_all()方法及selector()方法定位需要的元素。
find_all(tag, attibutes, recursive, text, limit, keywords)
find(tag, attibutes, recursive, text, keywords)
備注:常用前兩個參數
1、find_all()方法

2、find()方法

3、selector()方法
soup.selector(div.item>a>h2)#括號內容通過Chrome復制得到
(1)鼠標定位到想要提取的數據位置,右擊,在彈出的快捷菜單中選擇”檢查“命令
(2)在網頁源代碼中右擊所選元素
(3)在彈出的快捷菜單中選擇Copy selector.
import requests
from bs4 import BeautifulSoup
headers={) Chrome/73.0.3683.86 Safari/537.36'}
res=requests.get('http://bj.xiaozhu.com/',headers=headers)
res.encoding = 'utf-8'
soup=BeautifulSoup(res.text,'html.parser')
#price=soup.select('#page_list > ul > li:nth-child(1) > div.result_btm_con.lodgeunitname > div:nth-child(1) > span > i')
#price=soup.select('#page_list > ul > li:nth-of-type(1) > div.result_btm_con.lodgeunitname > div:nth-of-type(1) > span > i')
prices=soup.select('#page_list > ul > li > div.result_btm_con.lodgeunitname > div > span > i')
print(prices)
for price in prices:
print (price) #獲取單條html信息
print (price.get_text()) #獲取中間文字信息
Requests庫和BeautifulSoup庫組合應用:舉例實踐
實踐案例1:爬取北京地區短租房信息
1、爬蟲思路分析
(1)本節爬取小豬短租網北京地區短租房10頁信息。通過手動瀏覽,確認前4頁網址如下:
http://bj.xiaozhu.com/
http://bj.xiaozhu.com/search-duanzufang-p2-0/
http://bj.xiaozhu.com/search-duanzufang-p3-0/
http://bj.xiaozhu.com/search-duanzufang-p4-0/
把第一頁網址改為:
http://bj.xiaozhu.com/search-duanzufang-p1-0/后也能正常瀏覽,因此只需要更改p后面的數字就可以了,以此來構造10頁網址
(2)本次爬蟲在詳細頁面中進行,因此先需爬取進入詳細頁面的網址鏈接,進而爬取數據
(3)需要爬取的信息有:標題、地址、價格、房東名稱、房東性別和房東頭像的鏈接
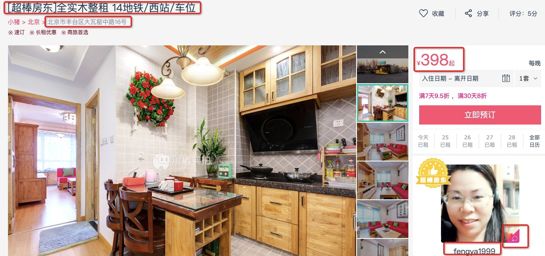
from bs4 import BeautifulSoup
import pandas as pd
import requests
import time
import lxml
#加入請求頭
headers={}
#定義判斷用戶性別的函數
def judgment_sex(class_name):
if class_name ==['member_icol']:
return '女'
else:
return '男'
#定義獲取詳細頁URL的函數
def get_links(url):
wb_data=requests.get(url,headers=headers)
#print(wb_data)
soup=BeautifulSoup(wb_data.text,'lxml')
#print(soup)
links=soup.select('#page_list > ul > li > a') #links為url列表
#page_list > ul > li:nth-child(1) > a
for link in links:
href=link.get("href")
get_info(href) #循環出的url,依次調用get_info()函數
#定義獲取網頁信息的函數
def get_info(url):
wb_data=requests.get(url,headers=headers)
soup=BeautifulSoup(wb_data.text,'lxml')
#tittles=soup.select('div.pho_info>h5')
#tittles=soup.select('#page_list > ul > li> div.result_btm_con.lodgeunitname > div.result_intro > a > span')
tittles = soup.select('div.pho_info > h5')
addresses = soup.select('span.pr5')
prices = soup.select('#pricePart > div.day_l > span')
imgs = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > a > img')
names = soup.select('#floatRightBox > div.js_box.clearfix > div.w_240 > h7 > a')
sexs = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > div')
for tittle,address,price,img,name,sex in zip(tittles,addresses,prices,imgs,names,sexs):
data={
'tittle':tittle.get_text().strip(),
'address':address.get_text().strip(),
'price':price.get_text(),
'img':img.get("src"),
'name':name.get_text(),
'sex':judgment_sex(sex.get("class"))
}
#print(data)#獲取信息并通過字典的信息打印
#print(pd.DataFrame([data]).head())
if __name__ == '__main__':
urls=['http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(number) for number in range(1,2)]
for single_url in urls:
print(single_url)
get_links(single_url)
time.sleep(2)到此,關于“python爬蟲方法實例分析”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





