溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“ChatGPT爬蟲實例分析”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“ChatGPT爬蟲實例分析”吧!
我要寫一個爬蟲,把ChatGPT上我的數據都爬下來,首先想想我們的問題域,我想到幾個問題:
不能用HTTP請求去爬,如果我直接
用HTTP請求去抓的話,一個我要花太多精力在登錄上了,而我的數據又不多,另一個,現在都是單頁引用,你HTTP爬下來的根本就不對啊。
所以最好是自動化測試的那種方式,啟動瀏覽器去爬。
但是我又不能保證一次把代碼寫成功,反復登錄的話,會被網站封號,就幾個數據,不值當的。
所以總的來說我需要一個這樣的流程:
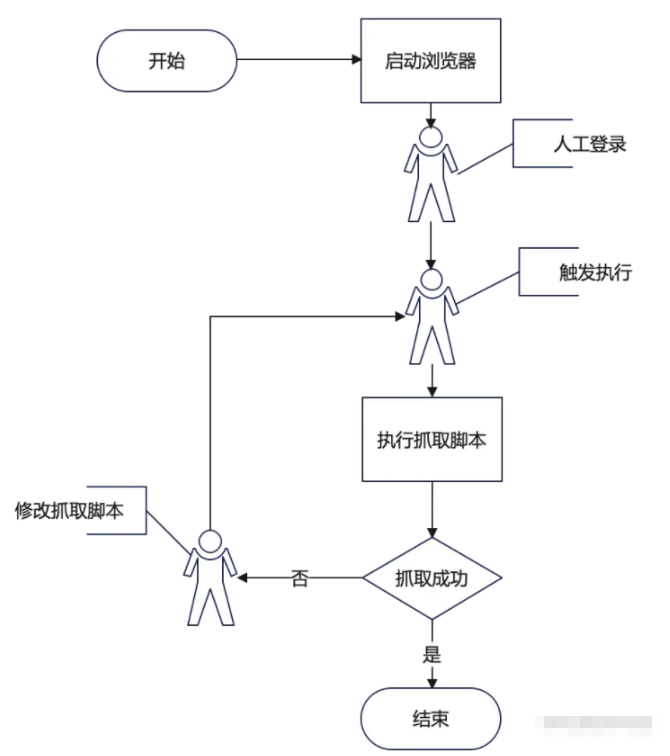
從流程上我們是不是可以看出,這個流程跟我們用WebConsole試驗一段代碼的過程很像?

從這種相似性可以看出,我需要一個類似WebConsole的東西來實現我要的效果,這個東西學名叫REPL(Read–eval–print loop),不過你不知道這個名字也無所謂,不影響。
而且還不止,我需要從文件讀入我的代碼,畢竟沒有代碼高亮,我可寫不好程序。從文件讀入的話,我就可以用vscode給我提供代碼高亮,這豈不是美滋滋。
想到這,如果是以前,我已經一個頭兩個大了,我只是想抓點東西,你讓我搞個REPL,這玩意聽著就不科學,我一天就晚上有一個小時的時間寫點代碼,這玩意太復雜了,乍一看也不是我業余時間能寫出來的。
但是現在,我們有了ChatGPT,那么我接下來可以用ChatGPT開始寫,簡單做一個任務分解:
寫一個框架,可以最大限度的幫我們提高開發效率
在這個框架上,一個場景一個場景的開發爬蟲
首先,我可能不知道這個東西叫REPL,但是我知道控制臺,那我就這么問:
如何用nodejs做一個命令行交互控制臺,執行輸入的js代碼
然后我就得到了下面的代碼:
const readline = require('readline');
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
prompt: '>> '
});
rl.prompt();
rl.on('line', (line) => {
try {
const result = eval(line);
console.log(result);
} catch (err) {
console.error(err);
}
rl.prompt();
});
rl.on('close', () => {
console.log('Exiting...');
process.exit(0);
});但是這個代碼還不夠我用的,我需要文件輸入,所以我可以問:
如果是讀入文件作為輸入呢?
然后我得到了下面的代碼:
const fs = require('fs');
const fileName = 'path/to/file.js';
const fileContent = fs.readFileSync(fileName, 'utf8');
try {
const result = eval(fileContent);
console.log(result);
} catch (err) {
console.error(err);
}第一反應,這個不是async/await模式調用的呀,我后面代碼寫起來會很麻煩,于是我就說:
我要用fs/promises庫實現上面邏輯怎么寫呢?
然后我就得到了下面的代碼:
const fs = require('fs').promises;
const fileName = 'path/to/file.js';
const fileContent = await fs.readFile(fileName, 'utf8');
try {
const result = eval(fileContent);
console.log(result);
} catch (err) {
console.error(err);
}這個點算是令我滿意了,但馬上我又意識到不對勁,我需要執行完之后 hang 在那里等待下一次輸入的,他這執行完就退出了,于是我又改進了的問題:
我要實現的效果是,啟動后在命令行里打印一個“>”然后等待輸入,我敲擊回車,程序就會讀入代碼中寫死的目標文件,并執行其中的js,然后重新打印一個“>“等待下一次輸入,無限循環。
然后我得到了下面的代碼:
const readline = require('readline');
const fs = require('fs').promises;
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
prompt: '> '
});
let filePath = 'path/to/target/file.js';
rl.prompt();
rl.on('line', async () => {
try {
const fileContent = await fs.readFile(filePath, 'utf8');
const result = eval(fileContent);
console.log(result);
} catch (err) {
console.error(err);
}
rl.prompt();
});
rl.on('SIGINT', () => {
console.log('Exiting...');
rl.close();
process.exit(0);
});注意,我再第一次的時候忘記了寫”無限循環“,所以他寫的代碼就只執行兩次,仔細一看,確實這樣實現也符合我說的邏輯,他沒有猜測我要無限循環,所以在使用的時候要注意,有時候沒得到你想要的結果可能是你沒說清楚。
那么看起來到此為止就差不多了,沒想到也不復雜。那我測試一下。
我建立了一個下面的工程結構:
. ├── index.js └── input └── input.js
把文件名寫死為input/input.js
執行 node index.js
彩蛋:其中有一次執行的代碼在后續執行發現錯誤,
發現下面錯誤:
```
/Volumes/MyLab/chatgpt-show/crawler/workspace/v1/index.js:15
const input = await new Promise(resolve => rl.question('', resolve));
^^^^^
SyntaxError: await is only valid in async functions and the top level bodies of modules
at internalCompileFunction (node:internal/vm:73:18)
at wrapSafe (node:internal/modules/cjs/loader:1149:20)
at Module._compile (node:internal/modules/cjs/loader:1190:27)
at Module._extensions..js (node:internal/modules/cjs/loader:1280:10)
at Module.load (node:internal/modules/cjs/loader:1089:32)
at Module._load (node:internal/modules/cjs/loader:930:12)
at Function.executeUserEntryPoint [as runMain] (node:internal/modules/run_main:81:12)
at node:internal/main/run_main_module:23:47
```原來是await用錯了,不過沒關系,直接拷給他:
上面的代碼執行報錯: SyntaxError: await is only valid in async functions and the top level bodies of modules
于是得到了修改后的代碼
那么接下來,我可以試著抓取一下列表了,這部分GPT3.5就不能勝任了,我切換到GPT4,然后問:
我用puppeteer打開一個網頁,可以直接用document DOM API操作,然后返回數據,請抓取這個網頁的列表,HTML如下:
.....
下面省略是openAI的頁面代碼,但是呢,因為他太大了,我不得不手動做了點刪減,比如我列表很長,我就減到只剩3個元素,其他無關的元素的代碼我都刪掉。
經過幾次詢問,他給出了我代碼:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('你的網址'); // 將'你的網址'替換為您要打開的頁面的實際URL
const list = await page.evaluate(() => {
const anchors = document.querySelectorAll('a');
const items = [];
for (const anchor of anchors) {
const itemText = anchor.querySelector('div.flex-1.text-ellipsis.max-h-5.overflow-hidden.break-all.relative');
if (itemText) {
const itemTitle = itemText.textContent.trim();
const itemLink = anchor.href;
items.push({ title: itemTitle, link: itemLink });
}
}
return items;
});
console.log(list);
await browser.close();
})();真到執行的時候又發現新問題,這個puppeteer我希望他一直開著,就不能在input.js里啟動,我需要在REPL代碼里就執行,所以我需要稍微修改下代碼,我說:
我需要在控制臺啟動的時候用puppeteer啟動一個瀏覽器,然后每次回車可以讓文件中的代碼可以通過puppeteer訪問啟動的這個瀏覽器
然后得到了代碼:
async function main() {
const readline = require('readline');
const fs = require('fs').promises;
const puppeteer = require('puppeteer-core');
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
prompt: '> '
});
const browser = await puppeteer.launch({
executablePath: '/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome'
});
let filePath = 'path/to/target/file.js';
rl.prompt();
async function executeWithBrowser(browser) {
const fileContent = await fs.readFile(filePath, 'utf8');
return eval(`async function (browser) { ${fileContent} }`)(browser);
}
rl.on('line', async () => {
try {
const result = await executeWithBrowser(browser);
console.log(result);
} catch (err) {
console.error(err);
}
rl.prompt();
});
rl.on('SIGINT', async () => {
console.log('Exiting...');
await browser.close();
rl.close();
process.exit(0);
});
}
main();這代碼還是不令我滿意,我又接連問了下面幾個問題:
我需要browser是GUI可見的
把path/to/target/file.js 改為 input/input.js
我需要在進入input/input.js之前直接啟動一個page,里直接訪問page而不是browser
這行代碼: return eval(async function (page) { ${fileContent} })(page);
報錯:
xxxx 能不能不用eval?
報錯: /Volumes/MyLab/chatgpt-show/crawler/workspace/v1/index.js:11
const browser = await puppeteer.launch({
^^^^^
SyntaxError: await is only valid in async functions and the top level bodies of modules
最后得到了我可以執行的代碼。不過實際執行中還出現了防抓機器人的問題,經過一些列的查找解決了這個問題,為了突出重點,這里就不貼解決過程了,最終代碼如下:
const readline = require('readline');
const fs = require('fs').promises;
// const puppeteer = require('puppeteer-core');
const puppeteer = require('puppeteer-extra')
// add stealth plugin and use defaults (all evasion techniques)
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
puppeteer.use(StealthPlugin());
(async () => {
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
prompt: '> '
});
const browser = await puppeteer.launch({
executablePath: '/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome',
headless: false,
args: ['--no-sandbox', '--disable-setuid-sandbox', '--disable-web-security']
});
const page = await browser.newPage();
let filePath = 'input/input.js';
rl.prompt();
async function executeWithPage(page) {
const fileContent = await fs.readFile(filePath, 'utf8');
const func = new Function('page', fileContent);
return func(page);
}
rl.on('line', async () => {
try {
const result = await executeWithPage(page);
console.log(result);
} catch (err) {
console.error(err);
}
rl.prompt();
});
rl.on('SIGINT', async () => {
console.log('Exiting...');
await browser.close();
rl.close();
process.exit(0);
});
})();而既然瀏覽器一直開著了,那我們需要執行的代碼其實只有兩個了:
goto_chatgpt.js
(async () => {
await page.goto('https://chat.openai.com/chat/');
})();fetch_list.js
(async () => {
const list = await page.evaluate(() => {
const anchors = document.querySelectorAll('a');
const items = [];
for (const anchor of anchors) {
const itemText = anchor.querySelector('div.flex-1.text-ellipsis.max-h-5.overflow-hidden.break-all.relative');
if (itemText) {
const itemTitle = itemText.textContent.trim();
const itemLink = anchor.href;
items.push({ title: itemTitle, link: itemLink });
}
}
return items;
});
console.log(list);
})();當然實際上fetch_list.js有點問題,因為openai做了防抓程序,我們可能很難搞到列表項的鏈接,不過這個也不難,我們用名字匹配挨個點就好了嘛,反正也不多。
比如下面這樣:
(async () => {
const targetTitle = 'AI Replacing Human';
const targetSelector = await page.evaluateHandle((targetTitle) => {
const anchors = document.querySelectorAll('a');
for (const anchor of anchors) {
const itemText = anchor.querySelector('div.flex-1.text-ellipsis.max-h-5.overflow-hidden.break-all.relative');
if (itemText && itemText.textContent.trim() === targetTitle) {
return anchor;
}
}
return null;
}, targetTitle);
if (targetSelector) {
const box = await targetSelector.boundingBox();
await page.mouse.click(box.x + box.width / 2, box.y + box.height / 2);
console.log(`Clicked the link with title "${targetTitle}".`);
} else {
console.log(`No link found with title "${targetTitle}".`);
}
})();說句題外話,上面的代碼很有意思,似乎它為了防止點某個具體元素不管用,竟然點擊了一個區域。
接下來如果我們想備份我們的每一個thread就可以在這個基礎上,讓ChatGPT繼續給我們寫實現完成即可,這里就不繼續展開了,大家可以自己完成。
首先,我們對問題域做了分析,把目標網站和工作者我本人以及時間限制等約束都納入了問題域進行了分析,得到了一個方案,然后通過類比發現我們的方案其實就是做一個有特定上下文的REPL,然后用這個REPL再去干具體的事。
接著,我們基于這個方案做了任務分解,粗略分成了做一個REPL和實現具體的抓取代碼兩部分。
接著我們靠ChatGPT把些任務實現,在實現的過程中,我們發現自己對問題域的細節了解不夠,于是我們又迭代了我們的任務列表。可以說方案沒有大的變化,實現上做了很多調整。
最終,我們就靠ChatGPT把這個REPL給做了出來,為了寫一個這樣的小功能,我們做了個框架,頗有點為了這點醋才包的這頓餃子的味道了。這要是在以前的時代,是一個巨大的浪費,但其實先做一個框架的思路在ChatGPT時代應該成為一種習慣,它會從兩個方面帶來好處:
可以降低輸入的文本數量,避免ChatGPT犯錯。因為很多人都知道,ChatGPT可以快速寫出一些小程序,但是長一點的總是會出錯,很多人到這里就放棄了,但其實,我們會發現如果我們能把問題分解到它恰好擅長的領域我們就可以最大限度的利用它的優勢,規避它的劣勢。人類歷史上,蒸汽機車發明的時候,它肯定不如馬耐顛,但為了充分理由他的優勢,人們為它鋪了鐵軌。直到今天為了發揮機動車的效力,我們還是要修路鋪軌,但是我們并不覺得有什么不對,從這個角度來講,我們也不該只盯著ChatGPT的缺點看,揚長避短才是正道。
縮短反饋環,提高效率。從整體效率角度來講,只有反饋環的縮短才是真正提高了效率,某一步的快速完成并不真正提高效率。所謂反饋環的縮短在我們的上下文里就是”我想到怎么編碼完成任務 -> 編碼 -> 測試 -> 得知代碼執行失敗->我又想到怎么編碼完成任務"的這個循環,我們不能假設代碼編寫一次成功,所以這個環越短,我們的效率就越高。在這個例子里我想到了我不能一次寫對,所以我就先做了REPL,這就是所謂磨刀不誤砍柴工。但是道理大家都懂,在有ChatGPT之前,磨刀這個事他總是誤砍柴工的,但是在今天,你可以用幾個問題就得到一個趁手的工具,開始你的工作,所以不要著急沖進去工作,先做個工具可能是新時代的好習慣。
到此,相信大家對“ChatGPT爬蟲實例分析”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





