溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Python怎么采集王者皮膚圖片的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇Python怎么采集王者皮膚圖片文章都會有所收獲,下面我們一起來看看吧。
我們在對王者英雄的主頁,進行了分析,我們發現,其網頁地址相似,就差一個數字。
https://pvp.qq.com/web201605/herodetail/{ename}.shtml我們可以把它當作為每個英雄的編號,我們可以從英雄列表獲取編號,不過,這里我們直接請求第三方接口數據。
html_url ='https://www.sapi.run/hero/getHeroList.php' datas = requests.get(html_url).json()['data'] for data in datas: ename = data['ename'] cname = data['cname'] print(ename,cname)
這段代碼中,html_url 是一個 URL,指向一個 SAPI 的 Hero 列表頁面。requests.get(html_url).json()['data'] 返回一個 JSON 對象,其中包含了 Hero 列表頁面的數據。ename 和 cname 是 JSON 對象中的兩個鍵值對,分別表示 Hero 的編號和名字。
在這段代碼中,我們使用了一個 for 循環來遍歷 JSON 對象中的每一個鍵值對,并打印出它們的值。這樣就可以得到 Hero 列表頁面中所有 Hero 的編號和名字。
我們拿到每一個英雄的編號之后,我們就可以訪問每一個英雄的主頁,我們在其主頁可以看到他們的英雄名稱和他們的英雄皮膚的地址。我們先獲取英雄皮膚的名稱。
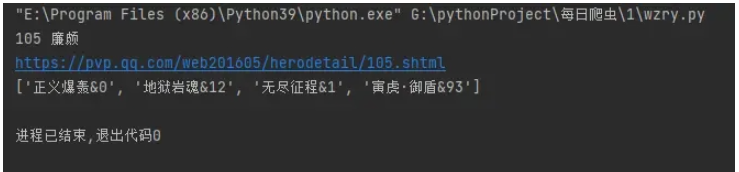
herodetail_url = f'https://pvp.qq.com/web201605/herodetail/{ename}.shtml'
print(herodetail_url)
res = requests.get(herodetail_url,headers=headers)
res.encoding = 'gbk'
# print(res.text)
pfs = re.findall('data-imgname="(.*?)"',res.text)[0]
pfs=pfs.split('|')
print(pfs)這段代碼中,herodetail_url 是一個 URL,指向一個 Hero 詳細頁面。requests.get(herodetail_url,headers=headers) 返回一個 JSON 對象,其中包含了 Hero 詳細頁面的數據。res.encoding = 'gbk' 設置了 JSON 對象的編碼方式為 GBK。re.findall('data-imgname="(.*?)"',res.text)[0] 使用正則表達式匹配 Hero 詳細頁面中的英雄名稱,并返回第一個匹配項。pfs 是匹配項的值,它是一個包含英雄名稱的列表。
接下來,我們對字段進行處理。
for pf in pfs:
pf = pf.split('&')[0]
# print(pf)
pf_list.append(pf)
print(len(pf_list))
print(pf_list)我們得到了這樣的數據。['正義爆轟', '地獄巖魂', '無盡征程', '寅虎·御盾'],到了這里,我們皮膚名字就獲取下來了。
pages = len(pfs)
for page in range(1,pages+1):
pf_url = f'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{ename}/{ename}-bigskin-{page}.jpg'
pf_url_list.append(pf_url)這段代碼中,我們首先計算出 Hero 詳細頁面中圖片的數量,然后使用 range 函數生成從 1 到 pages 的整數序列。接下來,我們使用一個循環來遍歷這個序列,并將每個圖片的 URL 添加到 pf_url_list 列表中。
最后,我們將 pf_url_list 列表中的所有 URL 連接起來,并將它們作為參數傳遞給 requests.get() 函數,以獲取 Hero 詳細頁面的數據。
到這里,我們把所有皮膚的地址獲取了下來。
for name,url in zip(pf_list,pf_url_list):
path = f'.//皮膚//{cname}//'
# print(path)
if not os.path.exists(path):
os.mkdir(path)
# print(cname,name,url)
pf_save = requests.get(url,headers=headers)
print(f"path + '{name}.jpg'")
with open(path + f'{name}.jpg', 'wb') as f:
f.write(pf_save.content)這段代碼中,我們首先將 pf_list 和 pf_url_list 兩個列表進行了 zip 操作,并將結果存儲在 pf_list 和 pf_url_list 兩個變量中。然后,我們使用 os.path.exists() 函數來檢查 path 目錄是否存在,如果不存在,則使用 os.mkdir() 函數創建該目錄。接下來,我們使用 requests.get() 函數來獲取 pf_url_list 列表中的每個 URL,并將它們作為參數傳遞給 requests.get() 函數,以獲取 pf_list 列表中的每個 URL。
最后,我們使用 with open() 語句打開 path + '{name}.jpg' 文件,并將 pf_save.content 寫入該文件中。這樣就可以將 pf_list 和 pf_url_list 中的每個 URL 保存到 path + '{name}.jpg' 文件中。
關于“Python怎么采集王者皮膚圖片”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“Python怎么采集王者皮膚圖片”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





