溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“MySQL表的增刪改查方法是什么”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“MySQL表的增刪改查方法是什么”吧!
CRUD : Create,Retrieve,Update,Delete
新增數據
查詢數據
修改數據
刪除數據
MySQL的工作就是組織管理數據,先保存,保存好了后好進行增刪改查
增刪改查的前提是已經把數據庫創建好,并且選中了,表也創建就緒
注釋:在SQL中可以使用“–空格+描述”來表示注釋說明
CRUD 即增加(Create)、查詢(Retrieve)、更新(Update)、刪除(Delete)四個單詞的首字母縮寫
insert into 表名 values(值,值,值…);
注意此處的值的個數要和表的列數匹配,值的類型也要和列的類型匹配(不匹配就會報錯!!!)
所以也更好的體現出關系型數據庫的一個優勢:對數據進行更嚴格的校驗檢查,更容易發現問題!
1.我們先在庫里創建一個學生表:
mysql> create table student(id int, name varchar(20)); Query OK, 0 rows affected (0.01 sec)
2.查看表的結構
mysql> desc student; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | int(11) | YES | | NULL | | | name | varchar(20) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ 2 rows in set (0.00 sec)
3.新增
mysql> insert into student values (1,"zhangsan"); Query OK, 1 row affected (0.00 sec)
注意:在SQL中表示字符串,可以使用單引號也可以使用雙引號,他們兩個是等價關系,在SQL中沒有 " 字符類型 ",只有字符串類型,所以單引號就可以表示字符串。
在這里無論我們表的列數不匹配還是類型不匹配,都是會報錯的
mysql> insert into student values(2);
ERROR 1136 (21S01): Column count doesn't match value count at row 1
mysql> insert into student values ("zhangsan",3);
ERROR 1366 (HY000): Incorrect integer value: 'zhangsan' for column 'id' at row 1注意:出現ERROR意味著當前的操作是不生效的
拓展:
我們在這里還可以插入中文數據:
mysql> insert into student values (2,"張三"); Query OK, 1 row affected (0.00 sec)
在這塊我們還需知道,數據庫表示中文需要明確字符編碼,MySQL默認的字符集叫做拉丁文,不支持中文,為了可以存儲,就需要把字符集改為UTF-8。在這里我們介紹一種一勞永逸的方法來修改字符集 --> 修改MySQL的配置文件
1.先確認當前數據庫的字符集
show variables like ‘character%’;
mysql> show variables like 'character%'; +--------------------------+---------------------------------------------------------+ | Variable_name | Value | +--------------------------+---------------------------------------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | utf8 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | utf8 | | character_set_system | utf8 | | character_sets_dir | C:\Program Files\MySQL\MySQL Server 5.7\share\charsets\ | +--------------------------+---------------------------------------------------------+ 8 rows in set, 1 warning (0.00 sec)
可以看到我的數據庫就是UTF-8字符集
2.找到配置文件-my.ini
①:可以使用軟件Everything來尋找
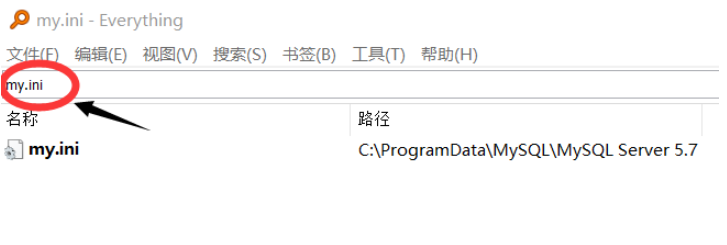
搜索框里輸入my.ini即可找到,但是可能會出現多個my.ini導致無法辨別哪一個才是我們要找的,所以不推薦
②:在我們的系統找到MySQL并且完成這一系列操作

右鍵快捷鍵進入屬性:
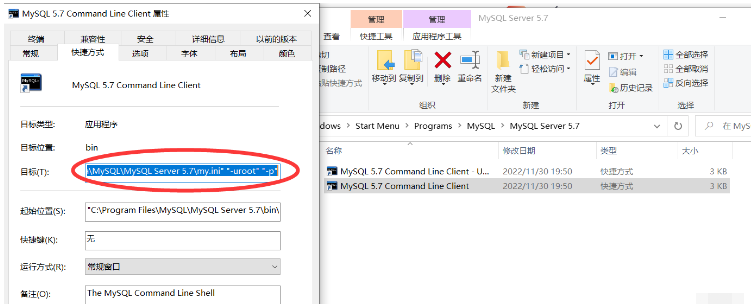
拷貝出目標里面的內容,這里就是MySQL的可執行程序路徑和配置文件路徑

把MySQL配置文件的位置復制過來
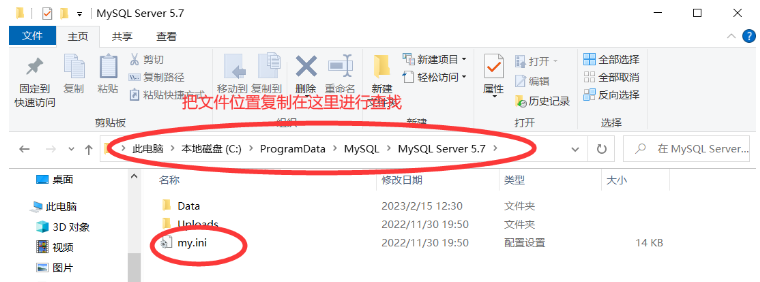
這就是我們要找的配置文件
3.修改配置文件
①:修改配置文件之前,一定要先備份!!!復制粘貼到旁邊一份保存著,以免改錯還原不回去了!!!
②:編輯ini文件,用記事本打開即可,找到下面沒有#的地方,有#號的地方是注釋
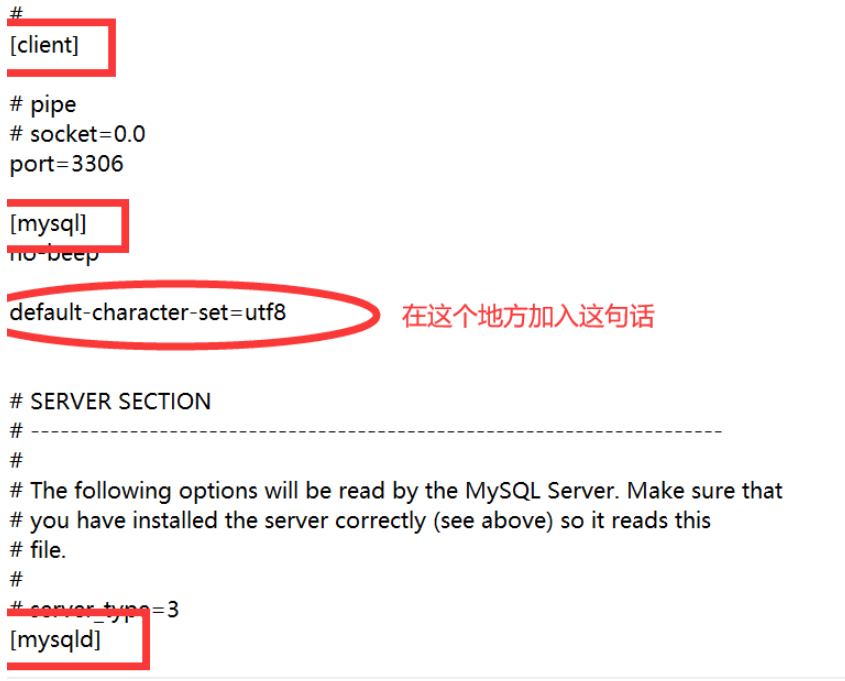
1.ini文件中,有一些[],每個[]稱為是一個selection,相當于把一組功能有聯系的配置放到了一起,構成了一個selection。
2.具體在[mysql]加入的那句話,那個配置是按照鍵值對的方式來組織的,注意這里的鍵值對單詞拼寫,等于號兩邊不要有空格。

修改完成后記得保存(Ctrl + s)就可以退出了
4.配置文件不是修改完了就立即生效,還需要額外進行一些操作
①:重啟MySQL服務器!不重啟就不會生效!
重啟服務器不是關閉黑框框(是客戶端)
在我們的搜索里搜索服務,找到MySQL然后右鍵進行重啟即可
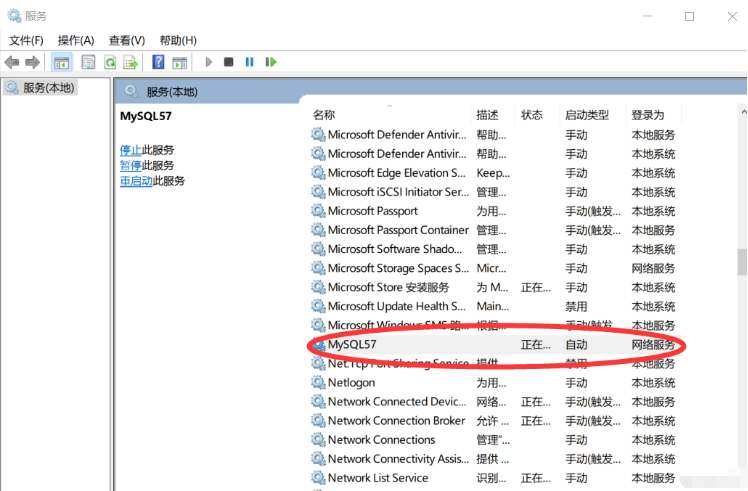
最后狀態欄顯示 " 正在運行 " 說明是重啟成功的!!!
如果是其他內容(啟動中…)則是重啟失敗,最大的原因就是配置文件修改錯誤
②:修改配置文件,對已經創建好的數據庫是沒有影響的,必須要刪除舊的數據庫,重建數據庫表。
至此MySQL配置修改就徹底結束了,繼續insert的探討
insert插入的時候可以指定列進行插入,不一定非得把這一行的所有列都插入數據,可以想插入幾列就插入幾列
mysql> insert into student (name) values ("lisi");
Query OK, 1 row affected (0.00 sec)如上我們在學生名字這一列插入list,其他未被插入(id)填入的值就是默認值,默認的默認值就是啥都不填,也就是NULL。
insert語句還可以一次插入多條記錄,在values后面,帶有多組(),每個()之間使用 , 來分割
mysql> insert into student values(1,"zhangsan"),(2,"lisi"),(3,"wangwu"); Query OK, 3 rows affected (0.00 sec) Records: 3 Duplicates: 0 Warnings: 0
在MySQL中,一次插入一條記錄分多次插入 比 一次插入多條記錄慢的很多!!
原因是MySQL是一個客戶端/服務器結構的程序,每次在客戶端里輸入的命令sql,都是通過網絡來進行傳輸的。

數據庫服務器需要解析請求,獲取到其中的sql,解析sql執行相關操作,并且把操作結果返回給客戶端
如果要是一次插入一條,分成多次插入就會有多個請求/相應,如果要是一次插入多條,就一次請求/相應就夠了
結語:插入是SQL中最簡單的一個操作,也是最常用的一個操作
查詢是SQL中最最重要也最復雜的操作,此處先介紹一下最簡單的查詢
直接把整個表里面的數據都查詢出來。
select * from 表名;
其中*是通配符,表示匹配任意的列(所有的列)
mysql> select * from student; +------+----------+ | id | name | +------+----------+ | 1 | zhangsan | | 2 | 張三 | | NULL | list | | 1 | zhangsan | | 2 | lisi | | 3 | wangwu | +------+----------+ 6 rows in set (0.00 sec)
注意理解這里的執行過程,牢記,客戶端和服務器之間通過網絡進行通信
這一組結果是通過網絡返回的,最終呈現在客戶端上,這些數據是服務器篩選得到的數據結果,客戶端也是以表格的形式進行呈現,但是大家不要把客戶端顯示的這個表格視為是服務器上數據的本體,這個客戶端上顯示的表格是個“臨時表”。
問題:如果當前數據庫的數據特別多,執行上述select*會發生什么情況呢?
服務器要先讀取磁盤,把這些數據都查詢出來,再通過網卡把數據傳輸給客戶端,由于數據量非常大,極有可能就把磁盤IO(input output)吃滿,或者把網絡帶寬吃滿。最直觀的感受就是會感受到卡頓,至于卡多久,不明確!!!
在執行一些SQL的時候如果執行的時間比較長,隨時可以按 Ctrl + c 來中斷,以免造成不必要的損失
select 列名,列名,列名… from 表名;
mysql> select id from student; +------+ | id | +------+ | 1 | | 2 | | NULL | | 1 | | 2 | | 3 | +------+ 6 rows in set (0.00 sec)
當我們省略掉一些不必要的列的時候,就可以節省大量的磁盤IO和網絡帶寬了
MySQL是客戶端服務器結構的程序,在此處看到的這個表結果,也同樣是 " 臨時表 " 只是在客戶端這里顯示成這個樣子,而不是說服務器上就真有一個這樣的表,里面只存了id列。
select所有的操作結果都是臨時表,都不會影響到數據庫服務器原有的數據!!!
讓查詢結果進行一些計算
select 表達式 from 表名;
創建一個新的表格:
mysql> create table exam_result (id int, name varchar(20), chinese decimal(3,1),math decimal(3,1), english decimal(3,1)); Query OK, 0 rows affected (0.01 sec)
decimal(3,1)表示的是三個數字長度,保留一位小時,如90.1,33.4
查看表格:
mysql> desc exam_result; +---------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+---------+-------+ | id | int(11) | YES | | NULL | | | name | varchar(20) | YES | | NULL | | | chinese | decimal(3,1) | YES | | NULL | | | math | decimal(3,1) | YES | | NULL | | | english | decimal(3,1) | YES | | NULL | | +---------+--------------+------+-----+---------+-------+ 5 rows in set (0.00 sec)
插入數據:
mysql> INSERT INTO exam_result (id,name, chinese, math, english) VALUES -> (1,'唐三藏', 67, 98, 56), -> (2,'孫悟空', 87.5, 78, 77), -> (3,'豬悟能', 88, 98.5, 90), -> (4,'曹孟德', 82, 84, 67), -> (5,'劉玄德', 55.5, 85, 45), -> (6,'孫權', 70, 73, 78.5), -> (7,'宋公明', 75, 65, 30); Query OK, 7 rows affected (0.00 sec) Records: 7 Duplicates: 0 Warnings: 0
再次查詢表格
mysql> select * from exam_result; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 1 | 唐三藏 | 67.0 | 98.0 | 56.0 | | 2 | 孫悟空 | 87.5 | 78.0 | 77.0 | | 3 | 豬悟能 | 88.0 | 98.5 | 90.0 | | 4 | 曹孟德 | 82.0 | 84.0 | 67.0 | | 5 | 劉玄德 | 55.5 | 85.0 | 45.0 | | 6 | 孫權 | 70.0 | 73.0 | 78.5 | | 7 | 宋公明 | 75.0 | 65.0 | 30.0 | +------+-----------+---------+------+---------+ 7 rows in set (0.00 sec)
讓每個人的語文成績都加10分
mysql> select name,chinese + 10 from exam_result; +-----------+--------------+ | name | chinese + 10 | +-----------+--------------+ | 唐三藏 | 77.0 | | 孫悟空 | 97.5 | | 豬悟能 | 98.0 | | 曹孟德 | 92.0 | | 劉玄德 | 65.5 | | 孫權 | 80.0 | | 宋公明 | 85.0 | +-----------+--------------+ 7 rows in set (0.00 sec)
但是需要注意的是這里得到的結果都是“臨時表”,對數據庫服務器上面的數據是沒有任何影響的!!!
再度查看表結構
mysql> select * from exam_result; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 1 | 唐三藏 | 67.0 | 98.0 | 56.0 | | 2 | 孫悟空 | 87.5 | 78.0 | 77.0 | | 3 | 豬悟能 | 88.0 | 98.5 | 90.0 | | 4 | 曹孟德 | 82.0 | 84.0 | 67.0 | | 5 | 劉玄德 | 55.5 | 85.0 | 45.0 | | 6 | 孫權 | 70.0 | 73.0 | 78.5 | | 7 | 宋公明 | 75.0 | 65.0 | 30.0 | +------+-----------+---------+------+---------+ 7 rows in set (0.00 sec)
如果數據變化超過了decimal(3,1),就是出現了多位數結果的情況,臨時表依舊會保證顯示的結果是正確的,但是嘗試往原始表中插入一個超出范圍的數據就是不行的!!!
臨時表當中的列完全取決于select指定的列名
select 表達式 as 別名 from 表名;
如求語數英三科總分
mysql> select name, chinese + math + english from exam_result; +-----------+--------------------------+ | name | chinese + math + english | +-----------+--------------------------+ | 唐三藏 | 221.0 | | 孫悟空 | 242.5 | | 豬悟能 | 276.5 | | 曹孟德 | 233.0 | | 劉玄德 | 185.5 | | 孫權 | 221.5 | | 宋公明 | 170.0 | +-----------+--------------------------+ 7 rows in set (0.00 sec)
如上我們看到的總分表達不是很合理,不直觀,我們可以對它起個別名
mysql> select name, chinese + english + math as total from exam_result; +-----------+-------+ | name | total | +-----------+-------+ | 唐三藏 | 221.0 | | 孫悟空 | 242.5 | | 豬悟能 | 276.5 | | 曹孟德 | 233.0 | | 劉玄德 | 185.5 | | 孫權 | 221.5 | | 宋公明 | 170.0 | +-----------+-------+ 7 rows in set (0.00 sec)
這樣我們的表達就清晰明了
可以通過as指定別名,as也可以省略,但是個人建議寫上
還有一些奇奇怪怪的表達式查詢,如:
mysql> select 10 from exam_result; +----+ | 10 | +----+ | 10 | | 10 | | 10 | | 10 | | 10 | | 10 | | 10 | +----+ 7 rows in set (0.00 sec)
這樣的SQL語句也可以執行,因為把10也當作是一個表達式(語法上沒錯,實際上沒啥意義)
表達式查詢,這里進行的計算,都是列和列之間的計算!!!而不是行和行之間的計算(行和行之間的計算有另外的方法)
把查詢結果相同的行,合并成一個
select distinct 列名 from 表名;
比如他們各自數學成績,有一個98.0重合的(上面數據沒有重合,此處假設),進行去重查詢之后就只剩下一個98.0
mysql> select distinct math from exam_result; +------+ | math | +------+ | 98.0 | | 78.0 | | 84.0 | | 85.0 | | 73.0 | | 65.0 | +------+ 6 rows in set (0.00 sec)
distinct 也可也以指定多個列,必須是多個列值完全相同的時候才會視為相同(才會去重)
我們在上面繼續添加相同信息
mysql> insert into exam_result (name, math) values ('唐三藏', 98.0);
Query OK, 1 row affected (0.00 sec)mysql> select * from exam_result; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 1 | 唐三藏 | 67.0 | 98.0 | 56.0 | | 2 | 孫悟空 | 87.5 | 78.0 | 77.0 | | 3 | 豬悟能 | 88.0 | 98.5 | 90.0 | | 4 | 曹孟德 | 82.0 | 84.0 | 67.0 | | 5 | 劉玄德 | 55.5 | 85.0 | 45.0 | | 6 | 孫權 | 70.0 | 73.0 | 78.5 | | 7 | 宋公明 | 75.0 | 65.0 | 30.0 | | NULL | 唐三藏 | NULL | 98.0 | NULL | +------+-----------+---------+------+---------+ 8 rows in set (0.00 sec)
對名字和數學列相同進行去重:
mysql> select distinct name, math from exam_result; +-----------+------+ | name | math | +-----------+------+ | 唐三藏 | 98.0 | | 孫悟空 | 78.0 | | 豬悟能 | 98.5 | | 曹孟德 | 84.0 | | 劉玄德 | 85.0 | | 孫權 | 73.0 | | 宋公明 | 65.0 | +-----------+------+ 7 rows in set (0.00 sec)
查詢過程中,對于查詢到的結果進行排序!(針對臨時表排序,對于數據庫上原來存的數據沒有影響)
select 列名 from 表名 order by 列名;
按照語文成績升序排序:
mysql> select * from exam_result order by chinese; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | NULL | 唐三藏 | NULL | 98.0 | NULL | | 5 | 劉玄德 | 55.5 | 85.0 | 45.0 | | 1 | 唐三藏 | 67.0 | 98.0 | 56.0 | | 6 | 孫權 | 70.0 | 73.0 | 78.5 | | 7 | 宋公明 | 75.0 | 65.0 | 30.0 | | 4 | 曹孟德 | 82.0 | 84.0 | 67.0 | | 2 | 孫悟空 | 87.5 | 78.0 | 77.0 | | 3 | 豬悟能 | 88.0 | 98.5 | 90.0 | +------+-----------+---------+------+---------+ 8 rows in set (0.00 sec)
按照語文成績降序排序:
mysql> select * from exam_result order by chinese desc; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 3 | 豬悟能 | 88.0 | 98.5 | 90.0 | | 2 | 孫悟空 | 87.5 | 78.0 | 77.0 | | 4 | 曹孟德 | 82.0 | 84.0 | 67.0 | | 7 | 宋公明 | 75.0 | 65.0 | 30.0 | | 6 | 孫權 | 70.0 | 73.0 | 78.5 | | 1 | 唐三藏 | 67.0 | 98.0 | 56.0 | | 5 | 劉玄德 | 55.5 | 85.0 | 45.0 | | NULL | 唐三藏 | NULL | 98.0 | NULL | +------+-----------+---------+------+---------+ 8 rows in set (0.00 sec)
降序排序只需要在末尾加個 desc 即可,升序末尾是asc,但是升序是默認的,可以省略!
order by 也可以針對帶有別名的表達式進行排序
總成績降序排序
mysql> select name, chinese + math + english as total from exam_result order by total desc; +-----------+-------+ | name | total | +-----------+-------+ | 豬悟能 | 276.5 | | 孫悟空 | 242.5 | | 曹孟德 | 233.0 | | 孫權 | 221.5 | | 唐三藏 | 221.0 | | 劉玄德 | 185.5 | | 宋公明 | 170.0 | | 唐三藏 | NULL | +-----------+-------+ 8 rows in set (0.00 sec)
SQL中,如果拿 NULL 和其他類型進行混合運算,結果仍然是NULL
order by 進行排序的時候,還可以指定多個列進行排序!
當指定多個列排序的時候,就相當于,先以第一個列為標準進行比較,如果第一列不分勝負,那么繼續按照第二列進行比較,以此類推…
mysql> select * from exam_result order by math desc,chinese; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 3 | 豬悟能 | 88.0 | 98.5 | 90.0 | | NULL | 唐三藏 | NULL | 98.0 | NULL | | 1 | 唐三藏 | 67.0 | 98.0 | 56.0 | | 5 | 劉玄德 | 55.5 | 85.0 | 45.0 | | 4 | 曹孟德 | 82.0 | 84.0 | 67.0 | | 2 | 孫悟空 | 87.5 | 78.0 | 77.0 | | 6 | 孫權 | 70.0 | 73.0 | 78.5 | | 7 | 宋公明 | 75.0 | 65.0 | 30.0 | +------+-----------+---------+------+---------+ 8 rows in set (0.00 sec)
select 操作中,如果沒有使用 order by 那么查詢結果順序是不確定的,沒有具體的標準進行排序
指定條件,對于查詢結果進行篩選
select * from 表名 where 條件;
引入where字句,針對查詢結果進行篩選。
篩選可以簡單理解成,對于查詢結果依次遍歷,把對應的查詢結果帶入到條件中,條件成立,則把這個記錄放到最終查詢結果里,條件不成立,則直接舍棄,不作為最終結果。
比較運算符:
| 運算符 | 說明 |
|---|---|
| >,>=,<,<= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的結果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的結果是 TRUE(1) |
| !=,<> | 不等于 |
| BETWEEN a0 AND a1 | 范圍匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN(option,…) | 如果是 option 中的任意一個,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多個(包括 0 個)任意字符;_ 表示任意一個字符 |
= 表示 =,不是賦值了,SQL中沒有 ==
SQL中,NULL = NULL 執行結果還是NULL,相當于FALSE。NULL <=> NULL 執行結果就是TRUE
LIKE能進行模糊匹配,匹配的過程中可以帶上通配符
邏輯運算符:
| 運算符 | 說明 |
|---|---|
| AND | 多個條件必須都為 TRUE(1),結果才是 TRUE(1) |
| OR | 任意一個條件為 TRUE(1), 結果為 TRUE(1) |
| NOT | 條件為 TRUE(1),結果為 FALSE(0) |
注:
WHERE條件可以使用表達式,但不能使用別名。
AND的優先級高于OR,在同時使用時,需要使用小括號()包裹優先執行的部分
進行條件查詢的時候,就是通過上述運算符組合最終完成的
①:基本查詢
查詢英語成績不及格的人
mysql> select * from exam_result where english < 60; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 1 | 唐三藏 | 67.0 | 98.0 | 56.0 | | 5 | 劉玄德 | 55.5 | 85.0 | 45.0 | | 7 | 宋公明 | 75.0 | 65.0 | 30.0 | +------+-----------+---------+------+---------+ 3 rows in set (0.00 sec)
條件查詢,就是把表里的記錄,挨個往條件中帶入
查詢語文成績比英語成績好的同學
mysql> select * from exam_result where chinese > english; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 1 | 唐三藏 | 67.0 | 98.0 | 56.0 | | 2 | 孫悟空 | 87.5 | 78.0 | 77.0 | | 4 | 曹孟德 | 82.0 | 84.0 | 67.0 | | 5 | 劉玄德 | 55.5 | 85.0 | 45.0 | | 7 | 宋公明 | 75.0 | 65.0 | 30.0 | +------+-----------+---------+------+---------+ 5 rows in set (0.00 sec)
查詢總分在200分以下的同學
mysql> select name, chinese + english + math as total from exam_result where chinese + math + english < 200; +-----------+-------+ | name | total | +-----------+-------+ | 劉玄德 | 185.5 | | 宋公明 | 170.0 | +-----------+-------+ 2 rows in set (0.00 sec)
錯誤示例:
mysql> select name, chinese + english + math as total from exam_result where total < 200; ERROR 1054 (42S22): Unknown column 'total' in 'where clause'
where 中,別名并不能作為篩選條件
②:and 與 or
查詢語文大于80分并且英語也大于80分的同學
mysql> select * from exam_result where chinese > 80 and english > 80; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 3 | 豬悟能 | 88.0 | 98.5 | 90.0 | +------+-----------+---------+------+---------+ 1 row in set (0.00 sec)
查詢語文大于80分或者英語大于80分的同學
mysql> select * from exam_result where chinese > 80 or english > 80; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 2 | 孫悟空 | 87.5 | 78.0 | 77.0 | | 3 | 豬悟能 | 88.0 | 98.5 | 90.0 | | 4 | 曹孟德 | 82.0 | 84.0 | 67.0 | +------+-----------+---------+------+---------+ 3 rows in set (0.00 sec)
如果一個條件中同時有 and 和 or ,先算 and 后算 or
mysql> select * from exam_result where chinese > 80 or english > 70 and math > 70; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 2 | 孫悟空 | 87.5 | 78.0 | 77.0 | | 3 | 豬悟能 | 88.0 | 98.5 | 90.0 | | 4 | 曹孟德 | 82.0 | 84.0 | 67.0 | | 6 | 孫權 | 70.0 | 73.0 | 78.5 | +------+-----------+---------+------+---------+ 4 rows in set (0.00 sec)
加上括號之后就是先算括號里的
③:范圍查詢
查詢語文成績在80到90之間的同學
mysql> select * from exam_result where chinese >= 80 and chinese <= 90; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 2 | 孫悟空 | 87.5 | 78.0 | 77.0 | | 3 | 豬悟能 | 88.0 | 98.5 | 90.0 | | 4 | 曹孟德 | 82.0 | 84.0 | 67.0 | +------+-----------+---------+------+---------+ 3 rows in set (0.00 sec) mysql> select * from exam_result where chinese between 80 and 90; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 2 | 孫悟空 | 87.5 | 78.0 | 77.0 | | 3 | 豬悟能 | 88.0 | 98.5 | 90.0 | | 4 | 曹孟德 | 82.0 | 84.0 | 67.0 | +------+-----------+---------+------+---------+ 3 rows in set (0.00 sec)
SQL進行條件查詢的時候,需要遍歷數據,帶入條件,遍歷操作在數據集合非常大的時候,是比較低效的,數據庫內部會做出一些優化手段,盡可能避免遍歷
在進行優化的時候,MySQL自身實現的一些行為相比于上述直接使用 and 來說,between and 是更好進行優化的
查詢數學成績是 58 或者 59 或者 98 或者 99 分的同學及數學成績
mysql> select * from exam_result where math in (58,59,98,99); +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 1 | 唐三藏 | 67.0 | 98.0 | 56.0 | | NULL | bit me | NULL | 98.0 | NULL | +------+-----------+---------+------+---------+ 2 rows in set (0.00 sec) mysql> select * from exam_result where math = 58 or math = 59 or math = 98 or math = 99; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 1 | 唐三藏 | 67.0 | 98.0 | 56.0 | | NULL | bit me | NULL | 98.0 | NULL | +------+-----------+---------+------+---------+ 2 rows in set (0.00 sec)
④:模糊查詢:LIKE
通過 like 來完成模糊查詢,不一定完全相等,只要有一部分匹配即可
mysql> select * from exam_result where name like '孫%'; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 2 | 孫悟空 | 87.5 | 78.0 | 77.0 | | 6 | 孫權 | 70.0 | 73.0 | 78.5 | +------+-----------+---------+------+---------+ 2 rows in set (0.00 sec)
%孫–>匹配以孫結尾的數據
%孫%–>匹配含孫的數據
%–>匹配任意數據
模糊查詢中需要用到通配符:%可以代替任意個字符,_可以用來代替任意一個字符(兩個下劃線就代表兩個任意字符)
雖然數據庫支持模糊匹配,但是使用中也要慎重使用模糊匹配。模糊匹配本身,其實是非常低效的,如果做成正則表達式這樣效率就會更低。
⑤:NULL的查詢
mysql> select * from exam_result; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 1 | 唐三藏 | 67.0 | 98.0 | 56.0 | | 2 | 孫悟空 | 87.5 | 78.0 | 77.0 | | 3 | 豬悟能 | 88.0 | 98.5 | 90.0 | | 4 | 曹孟德 | 82.0 | 84.0 | 67.0 | | 5 | 劉玄德 | 55.5 | 85.0 | 45.0 | | 6 | 孫權 | 70.0 | 73.0 | 78.5 | | 7 | 宋公明 | 75.0 | 65.0 | 30.0 | | NULL | 唐三藏 | NULL | 98.0 | NULL | +------+-----------+---------+------+---------+ 8 rows in set (0.00 sec) mysql> select * from exam_result where chinese = NULL; Empty set (0.00 sec) mysql> select * from exam_result where chinese <=> NULL; +------+--------+---------+------+---------+ | id | name | chinese | math | english | +------+--------+---------+------+---------+ | NULL | 唐三藏 | NULL | 98.0 | NULL | +------+--------+---------+------+---------+ 1 row in set (0.00 sec) mysql> select * from exam_result where chinese is NULL; +------+--------+---------+------+---------+ | id | name | chinese | math | english | +------+--------+---------+------+---------+ | NULL | 唐三藏 | NULL | 98.0 | NULL | +------+--------+---------+------+---------+ 1 row in set (0.00 sec)
從上面三個式子查詢 NULL 中可以看出
直接使用 = 來進行匹配是不能正確進行篩選的
使用 <=> 可以正確和 NULL 進行匹配
使用 is NULL 也是可以進行比較的
使用 limit 關鍵字,來進行限制返回的結果條數,使用 offset 來確定從第幾條開始進行返回
select 列名 from 表名 limit N offset M;
select 列名 from 表名 limit M, N
從第 M 條開始查詢,最多返回 N 條記錄
mysql> select * from exam_result; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 1 | 唐三藏 | 67.0 | 98.0 | 56.0 | | 2 | 孫悟空 | 87.5 | 78.0 | 77.0 | | 3 | 豬悟能 | 88.0 | 98.5 | 90.0 | | 4 | 曹孟德 | 82.0 | 84.0 | 67.0 | | 5 | 劉玄德 | 55.5 | 85.0 | 45.0 | | 6 | 孫權 | 70.0 | 73.0 | 78.5 | | 7 | 宋公明 | 75.0 | 65.0 | 30.0 | | NULL | 唐三藏 | NULL | 98.0 | NULL | +------+-----------+---------+------+---------+ 8 rows in set (0.00 sec) mysql> select * from exam_result limit 3; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 1 | 唐三藏 | 67.0 | 98.0 | 56.0 | | 2 | 孫悟空 | 87.5 | 78.0 | 77.0 | | 3 | 豬悟能 | 88.0 | 98.5 | 90.0 | +------+-----------+---------+------+---------+ 3 rows in set (0.00 sec) mysql> select * from exam_result limit 3 offset 3; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 4 | 曹孟德 | 82.0 | 84.0 | 67.0 | | 5 | 劉玄德 | 55.5 | 85.0 | 45.0 | | 6 | 孫權 | 70.0 | 73.0 | 78.5 | +------+-----------+---------+------+---------+ 3 rows in set (0.00 sec) mysql> select * from exam_result limit 3 offset 6; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 7 | 宋公明 | 75.0 | 65.0 | 30.0 | | NULL | 唐三藏 | NULL | 98.0 | NULL | +------+-----------+---------+------+---------+ 2 rows in set (0.00 sec)
查詢總分前三成績的同學
mysql> select name, chinese + english + math as total from exam_result order by total desc limit 3; +-----------+-------+ | name | total | +-----------+-------+ | 豬悟能 | 276.5 | | 孫悟空 | 242.5 | | 曹孟德 | 233.0 | +-----------+-------+ 3 rows in set (0.00 sec)
select * 這樣的操作,容易把數據庫弄掛了,除了 select * 之外,只要你返回的記錄足夠多哪怕用了其他方式查詢,也是同樣有風險的,即使你加上 where 條件篩選,萬一篩選的結果很多,還是會弄壞服務器,最穩妥的辦法就是加上 limit 。
此處的修改,是針對數據庫服務器進行的,這里的修改是持續有效的
update 表名 set 列名 = 值… where 子句
核心信息:針對哪個表,的哪些行,的哪些列,改成啥樣的值。
把孫悟空數學成績修改為80分
mysql> update exam_result set math = 80 where name = '孫悟空'; Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select * from exam_result; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 1 | 唐三藏 | 67.0 | 98.0 | 56.0 | | 2 | 孫悟空 | 87.5 | 80.0 | 77.0 | | 3 | 豬悟能 | 88.0 | 98.5 | 90.0 | | 4 | 曹孟德 | 82.0 | 84.0 | 67.0 | | 5 | 劉玄德 | 55.5 | 85.0 | 45.0 | | 6 | 孫權 | 70.0 | 73.0 | 78.5 | | 7 | 宋公明 | 75.0 | 65.0 | 30.0 | | NULL | 唐三藏 | NULL | 98.0 | NULL | +------+-----------+---------+------+---------+ 8 rows in set (0.00 sec)
將曹孟德同學的數學成績變更為 60 分,語文成績變更為 70 分
mysql> update exam_result set chinese = 70, math = 60 where name = '曹孟德'; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select * from exam_result; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 1 | 唐三藏 | 67.0 | 98.0 | 56.0 | | 2 | 孫悟空 | 87.5 | 80.0 | 77.0 | | 3 | 豬悟能 | 88.0 | 98.5 | 90.0 | | 4 | 曹孟德 | 70.0 | 60.0 | 67.0 | | 5 | 劉玄德 | 55.5 | 85.0 | 45.0 | | 6 | 孫權 | 70.0 | 73.0 | 78.5 | | 7 | 宋公明 | 75.0 | 65.0 | 30.0 | | NULL | 唐三藏 | NULL | 98.0 | NULL | +------+-----------+---------+------+---------+ 8 rows in set (0.00 sec)
將總成績倒數前三的 3 位同學的數學成績加上 30 分(先查明成績總單)
mysql> select name, chinese + english + math as total from exam_result order by total; +-----------+-------+ | name | total | +-----------+-------+ | 唐三藏 | NULL | | 宋公明 | 170.0 | | 劉玄德 | 185.5 | | 曹孟德 | 197.0 | | 唐三藏 | 221.0 | | 孫權 | 221.5 | | 孫悟空 | 244.5 | | 豬悟能 | 276.5 | +-----------+-------+ 8 rows in set (0.00 sec) mysql> update exam_result set math = math + 30 order by chinese + english + math limit 3; ERROR 1264 (22003): Out of range value for column 'math' at row 1
發現出現了錯誤,原因就是有數學加30超出了合理范圍,但是可以減去30(不能寫成 math += 30)
update 后面的條件很重要,修改操作是針對條件篩選之后對剩下的數據進行的修改,如果沒寫條件,意味著就是對所以行都進行修改!!!
update 也是一種比較危險的操作,除了提前備份就基本無法還原改前數據!!!
刪除符合條件的行
delete from 表名 where 條件;
delete from 表名; --> 把表里的記錄都刪除了,表只剩下一個空的表了
刪除唐三藏的信息
mysql> delete from exam_result where name = '唐三藏'; Query OK, 1 row affected (0.00 sec) mysql> select * from exam_result; +------+-----------+---------+------+---------+ | id | name | chinese | math | english | +------+-----------+---------+------+---------+ | 2 | 孫悟空 | 87.5 | 80.0 | 77.0 | | 3 | 豬悟能 | 88.0 | 98.5 | 90.0 | | 4 | 曹孟德 | 70.0 | 60.0 | 67.0 | | 5 | 劉玄德 | 55.5 | 85.0 | 45.0 | | 6 | 孫權 | 70.0 | 73.0 | 78.5 | | 7 | 宋公明 | 75.0 | 65.0 | 30.0 | +------+-----------+---------+------+---------+ 6 rows in set (0.00 sec)
刪除表里的內容,表還存在!!!
mysql> delete from exam_result; Query OK, 7 rows affected (0.00 sec) mysql> select * from exam_result; Empty set (0.00 sec)
drop table 是把整個表都干掉了
感謝各位的閱讀,以上就是“MySQL表的增刪改查方法是什么”的內容了,經過本文的學習后,相信大家對MySQL表的增刪改查方法是什么這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





