溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“如何使用R中的merge()函數合并數據”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“如何使用R中的merge()函數合并數據”吧!
在R中可以使用merge()函數去合并數據框,其強大之處在于在兩個不同的數據框中標識共同的列或行。
merge()最簡單的形式為獲取兩個不同數據框中交叉部分。舉例,獲取cold.states和large.states完全匹配的數據。代碼如下:
> merge(cold.states, large.states) Name Frost Area 1 Alaska 152 566432 2 Colorado 166 103766 3 Montana 155 145587 4 Nevada 188 109889
如果你屬性數據庫語法SQL,你可能想merge()和數據庫中JOIN功能很相似。確實如此,merge()函數的不同參數可以實現內join,left join,right join以及完整join。
merge()函數有很多參數,看起來非常嚇人。但他們都幾中類型參數有關:
x: 第一個數據框.
y: 第二個數據框.
by, by.x, by.y: 指定兩個數據框中匹配列名稱。缺省使用兩個數據框中相同列名稱。
all, all.x, all.y: 指定合并類型的邏輯值。缺省為false,all=FALSE (僅返回匹配的行).
最后一組參數all, all.x, all.y需要進一步解釋,決定合并類型。
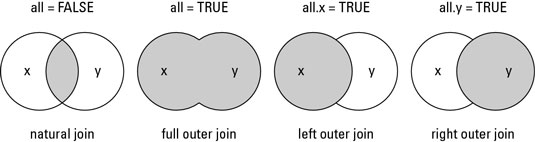
merge() 函數支持4種類型數據合并:
Natural join: 僅返回兩數據框中匹配的數據框行,參數為:all=FALSE.
Full outer join: 返回兩數據框中所有行, 參數為: all=TRUE.
Left outer join: 返回x數據框中所有行以及和y數據框中匹配的行,參數為: all.x=TRUE.
Right outer join: 返回y數據框中所有行以及和x數據框匹配的行,參數為: all.y=TRUE.
返回示例數據中美國的州,執行完整合并cold和large state,使用參數all=TRUE.
> merge(cold.states, large.states, all=TRUE) Name Frost Area 1 Alaska 152 566432 2 Arizona NA 113417 3 California NA 156361 .... 13 Texas NA 262134 14 Vermont 168 NA 15 Wyoming 173 NA
兩個數據框有不同的名稱,所以R基于兩者state的name進行匹配。Frost來自cold.states數據框,Area來自large.states.
上面代碼執行了完整合并,填充未匹配列值為NA。
到此,相信大家對“如何使用R中的merge()函數合并數據”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





